Haskell で Cloudflare Workers 製のフルスタックブログエンジンを作ったら快適すぎた
TL;DR
-
GHC の WASM バックエンドを使って、フロントエンドからCloudflare Workersで動くバックエンドまで、全部 Haskell で書かれたブログエンジンを実装したよ。
-
Servant の Workers 向けアダプタを実装したよ
- いちどAPIを型レベルで定義したら、バックエンドのルーティングやクライアントからのAPIへのアクセス、SPAのビューのルーティングまで全部同じ定義を使い回せてしかもリンク切れがない事が静的に保証されるので、かなり快適だったよ。
-
フロントノードは Miso を使ったので、同じデータ型と API 定義を共有できて、SSRも out-of-the-box でサポートしているのでかなり体験がよかったよ
-
なぜか Twitter が OGP を表示してくれないけど私は元気です。
2025-02-08 追記
ARM Mac を含め独自の GHCup チャネルを登録すれば降ってくるようになりました!開発チームの皆さん(というか terrorjackさん)ありがとうございます!遂に Earthly などが要らなくなった……。
基本的には以下の公式ページの指示に従えば大丈夫です。
ただし、以下に注意
-
Using ghcupの節ではwasm32-wasi-ghc-9.12としてしか指定していませんが、これだと厳密にマッチするバイナリがないので、ghcup list -t ghc |grep wasm32などして入れたいバージョンをフルで指定して install する必要があります。- 例:2025-02-08 現在では
ghcup install --force wasm32-wasi-9.12.1.20250206 -- $CONFIGURE_ARGSとする。
- 例:2025-02-08 現在では
- Bash なら上のコマンドで動くんですが、Zsh の変数展開がよくわからない悪さをするので、上の
$CONFIGURE_ARGSは内容を確認してベタ書きしたほうがいいです。-
例:2025-02-08 現在、ARM Mac 上だったら以下のように実行したら上手くいきました:
$ echo $CONFIGURE_ARGS --host=aarch64-apple-darwin --target=wasm32-wasi --with-intree-gmp --with-system-libffi $ ghcup install ghc --force wasm32-wasi-9.12.1.20250206 -- --host=aarch64-apple-darwin --target=wasm32-wasi --with-intree-gmp --with-system-libffi ...
-
導入
以前の投稿で、GHC WASM backend を使ってものすごく簡単な Cloudflare Workers アプリを実装する話をしました:
これは単純にリクエストをダンプしたりなんかFibonacci数を計算してみたりするだけなので、あくまでもPoCというべきもので、実際に実用的なウェブアプリを実装できるのかな?というのは今後の課題としていました。
実は最近転職しまして、一ヶ月くらい暇だったので、よい機会ということでCloudflare Workers上で動くブログエンジンをつくってみました。
ソースコードはこちら:
実際に動いているものは以下です。
もともと、10年くらい前から主に自炊画像を投稿しているたんぶらーがあり、なんか最近たんぶらーの使い勝手が悪くなってきたので移行したい、というのがモチベーションの一つでした。
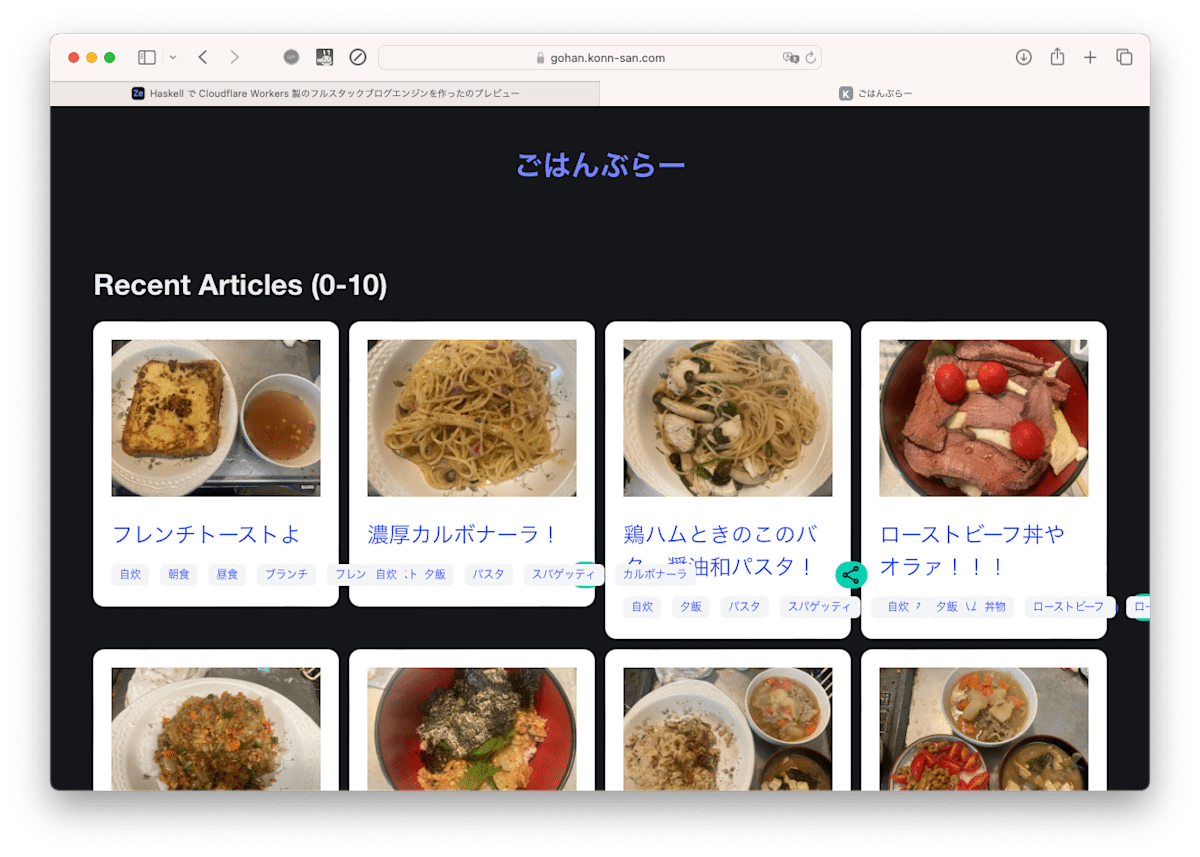
もともと、10年くらい前から主に自炊画像を投稿しているたんぶらーがあり、なんか最近たんぶらーの使い勝手が悪くなってきたので移行したい、というのがモチベーションの一つでした。
言い訳:ウェブ産業の人間でもなく、Cloudflare Workersについてもドキュメントを調べたりTwitterで人々に質問したり(@mizchi さんありがとうございました)してやっているので全然ベストプラクティスではない(フロントエンドに至ってはBulmaの使い方がわかっていないのでアホみたいに描画が乱れている)ですが、とりあえず個人ブログとして運用する上では問題ないものができたんじゃないかと思います。
以下では、あんまり詳細には立ち入らず、アプリの構成と、それを実現するために使った既存のもの、新しく作ったもの、作ってみた所感について簡単に紹介していきたいと思います。
既存記事への誘導
Cloudflare Workers で動かすための WASM や界面となる JS の生成に必要な固有の事項や、拙作の ghc-wasm-compat ライブラリを使って HLS を使う方法、Earthlyでのビルド方法などについては、前回の記事で扱っているのでそちらを御覧ください。
今回の記事では、複数の Worker からなるサービスの構築、Miso製フロントエンドとの協業などについて焦点を当てます。
背景
本論に入る前に、今回 Cloudflare Workers と組み合わせて使う既存の Haskell ライブラリについて簡単に紹介しておきます。
扱うものはAPI 記述フレームワークの Servant (のレコードを使ったGenericインタフェース)と、 フロントエンドフレームワークの Misoです。
知っている方は飛ばして次の節に進んでいただいて構いません。
背景1:Servantによる API 記述
Haskellには、Servantというフレームワークがあります:
これは、型レベルで REST API を定義してやることで、バックエンドのルータ、HTTPクライアント、静的リンクの生成、API ドキュメントの生成、OpenAPI のスキーマなどREST APIに係る様々な局面でその定義を共有して静的に保証できるというものです。
Servantでルータを実装するには servant-server パッケージを使いますが、型レベルAPI定義を充足するようなルートごとのハンドラを過不足なく定義することを強制されます。
また、servant-client を使うと、型レベル定義からそれら全ての API へのリクエストが自動的に生成されます。
たとえば、ブログサービスのフロントエンド配信用のエンドポイントと、内部的に用いる REST API は次のようになります:
type RootApi =
"api" :> RestApi -- ^ REST Api のエンドポイント群
:<|> "articles" :> Capture "slug" Text
:> QueryParam "page" Int :> Get '[HTML] Text
:<|> Get '[HTML] Text -- ^ トップページ
type RestApi =
"articles" :> Capture "slug" Text :> Get '[JSON] Article
:<|> "articles" :> Get '[JSON] [Article]
:<|> "tags" :> Get '[JSON] [Text]
:<|> "tags" :> Capture "tag" Text :> Get '[JSON] [Article]
:<|> "admin" :> Auth '[JWT] User :> AdminApi
type AdminApi =
"articles"
:> ReqBody '[JSON] ArticleSeed
:> POST '[PlainText] NoContent
:<|> "articles" :> Capture "slug" Text
:> ReqBody '[JSON] ArticleUpdate
:> Put '[PlainText] NoContent
:<|> "articles" :> Capture "slug" Text :> Delete '[PlainText] NoContent
なんとなく雰囲気は把めると思います。 :<|> で区切られた各成分が個別のエンドポイントに対応し、 :> の左辺が各エンドポイントが要求するデータ(パス(Capture)やクエリパラメータ(QueryParam)、リクエストボディ(ReqBody)、認証(Auth)など)に対応し、最後にリクエストのメソッドと正常系の場合の Content-Type およびその意味論的な表現を書く形になります。
バックエンドを実装するときは :<|> の順に :> の左辺値を引数に持つハンドラ関数を定義してやり、逆にクライアントを使う際には型から自動生成された関数に必要な引数を渡してやって呼び出すことで、それぞれ統一的に扱ってやることができます(静的リンクの生成もそう)。
とはいえ、順番をいちいちちゃんと覚えておくのは大変なので、Servant には Generic インタフェースがあり、型演算子を使って並べる代わりにレコードでAPIを定義してフィールド名でエンドポイントを区別する事ができます。
上の API に対応する定義は次のようになります:
data RootApi mode=
{ restApi :: mode :- "api" :> NamedRoutes RestApi
, articlePage ::
mode :- "articles" :> Capture "slug" Text
:> QueryParam "page" Int :> Get '[HTML] Text
, topPage :: mode :- Get '[HTML] Text -- ^ トップページ
}
deriving (Generic)
type RestApi mode =
{ getArticle :: mode :- "articles" :> Capture "slug" Text :> Get '[JSON] Article
, listArticles :: mode :- "articles" :> Get '[JSON] [Article]
, listTags :: mode :- "tags" :> Get '[JSON] [Text]
, getTagArticles :: mode :- "tags" :> Capture "tag" Text :> Get '[JSON] [Article]
, adminApi :: mode :- "admin" :> Auth '[JWT] User :> NaemdRoutes AdminApi
}
deriving (Generic)
-- ... AdminApi も同様 ...
servant-server でバックエンドを書く場合は、対応する引数・返値を持つ関数から成るレコードを定義してやることで自動的にバックエンドの実装ができます:
backend :: Application
backend = genericServer rootApi
rootApi :: RootApi AsServer
rootApi = RotoApi { restApi, articlePage, topPage }
restApi :: RestApi AsServer
restApi = RestApi { getArticle, .. }
articlePage :: Text -> Handler Text
articlePage "slug" = pure $ "You requested " <> slug
getArticle :: Text -> Handler Article
-- ...
adminApi :: AuthResult User -> AdminApi AsServer
-- ...
-- ... ナドナド ...
逆に servant-client を介して REST API を呼ぶ場合は、genericClient を呼んでやると、API呼び出しに対応する関数からなるレコードが降ってきます:
{-# LANGUAGE OverloadedRecordDot #-}
apis :: RootApi (AsClient ClientM)
apis = genericClient
main :: IO ()
main = do
art <- runClient (apis.restApi.getArticle "my-first-blog") (mkClient ...)
case art of
Left err -> throwError err
Right a -> print a
このようにして、Servantを使うと同一の API 定義を共有して過不足なく呼び出しができることを統一的に保証でき、各エンドポイントを関数として統一的に扱うことが出来るようになるのです。
今回の目標の一つは、この機構を Cloudflare Workers でも使えるようにすることです。
Miso: フロントエンドフレームワーク
Haskellでは、主にJSコンパイラバックエンドを念頭においた Miso というフロントエンドフレームワークがあり、実戦でも使われているようです:
これは The Elm Architecture に基づいたもので、状態を表すモデルとそのレンダリング関数、および状態遷移関数を与えてやる形でSPA(Single Page App)を記述するというものです。効率的な仮想 DOM 差分アルゴリズムの実装を謳っており、パフォーマンスにもそれなりに気をつかっているようです。
要するに、モデルとその間の遷移関数を与えてやることでよしなに差分をとってビューをアップデートしてくれるのが Miso で、それを Haskell で書けるのが嬉しいという訳です。
これに加え、Elmと異なり Haskell で書かれているため、バックエンドとフロントエンドで同じ言語・コードを共有できる Isomorphism を謳っています。要は、サーバサイドレンダリング[1]が手軽にできますよ、という話です。
また、SPAでも状態遷移に応じてブラウザのURLを差し替えたり、逆にURLに応じてビューを差し替えたりするルーティングが必要になりますが、MisoもServantをここに使っています。バックエンドや静的リンク生成にも Servant を使いますので、API回りの扱いが統一的かつ型安全にできると期待できそうです。
実際の構成と必要に応じて創ったもの
フロントエンドもバックエンドも GHC WASM Backend を使って Haskell で記述されています。
バックエンドの構成と工夫
バックエンドは Cloudflare Workers を利用し、CDNエッジでミリ秒単位で動くサーバレスアプリとして実装しています。
プランはkonn-san.com ドメインについてきた Free Plan の範囲内で使っています。
当初は一枚岩のWorker一つでできていたのですが、圧縮後のWASMバイナリの容量が Free Plan上限である 1000KiB [2] を越えてしまうので、mizchiさんに教えてもらった Service Bindings の仕組みを使って、現在では担当範囲の違う5つのWorkerから成っています:
-
Router: HTTPリクエストを基にルーティングを行い、Service Bindingsを介して適切なWorkerを呼び出す。
-
自前で実装したServant の Cloudflare Workers 向けアダプタを使って記述されています(後述)。
-
フロントエンドのアセットや robots.txt などは Static Assets 機能を使ってサーヴさせている。
-
管理画面やAPIなどは、Cloudflare Zero Trust のヘッダを検証することで認可を行う
-
-
Database: Cloudflare D1 を使って、記事の管理(投稿・一覧・修正)や添付画像のメタデータの管理を行うWorker。
- D1: Cloudflare の Workers などから呼び出せる強化版SQLiteみたいなもの。書き込みはCDN Edge上の一箇所だけにいて、Read Replicaが世界中に分散しているものらしい。
-
Storage: 記事の添付リソース(現状画像のみ)を保存したり、リソースへの15分間アクセス可能な署名つきURLを発行したり、署名つきURLを検証して生リソースを返したりする。
- Cloudflare Images にはストレージサービスもあるが、Free では使えないので画像はR2に保存している。
-
Images: 上記 Storage Worker と通信をして、トップページや記事、OGPに埋め込む用の画像を生成・サーヴするWorker。メタデータの削除と画像のリサイズに必要。
- Cloudflare Images の Transform 機能を使って実装。
-
SSR: 個別記事のページをサーバサイドレンダリングするためのワーカ。MisoのIsomorphism機能を使って実現。目的は三つ:
- SNSでシェアした際のリンクカードを生成できるように、記事HTMLにOGPタグを埋め込むため
- ブラウザでの Markdown のレンダリングを省くため
- APIコールを削減してキャッシュ化してコストを抑えるため。
これらの間のRPCにCloudflareのService Bindingsの機能を使っているわけです。
Servant によるルータの実装
Haskellのバックエンド周辺には、WAI (Web Application Interface) という枠組みがあり、これは具体的なフレームワークやバックエンドエンジンに依存せずに、ウェブアプリケーションを実装するための枠組みで、簡単にはアプリケーションを Request -> IO Response [3] の型を持つものと考えて抽象化するものです。
ServantもWAIに立脚した servant-server パッケージがあり、最終的には WAI アプリケーションにコンパイルされるようになっています。
実は、Cloudflare Workers でも Servant を使おうよ、というアイデアは私のオリジナルではありません。実際、GHC WASM Backendの前身である Asterius の時代には、WASM Backendを先導している Tweag IO の人達が「Servant を Cloudflare Workres で使おう!」という記事を書いています:
ここでのアプローチは、WAIの Request / Response と Workers の Request / Response を相互に変換する関数を提供することで WAI アプリケーションを全部動かせるようにしよう、というものでした。ワーカ内部の処理が完全にHaskellで閉じている場合、これで必要十分ですし、(バイナリサイズ・実行時間を度外視すれば)既存のバックエンドを Cloudflare Workers で動かすことができます。
しかし、今回はこの手法は取らず、自前で Servant の Cloudflare Workers 向けアダプタを実装する道を選びました。以下がその成果物です:
なぜ自前でやったのかというと、WAIアプリを解釈する形にしてしまうと、JavaScript 世界のリクエスト・レスポンスのボディのデータをHaskellのByteStringと相互に変換する処理が挟まってしまうためです。
Cloudflare Workres は Cloudflare の CDN エッジで約10ミリ秒以内で動くワーカを分散して動かすことでスケールするウェブアプリを作れる、というサービスです。10ミリ秒というとい少なく聞こえますが、外部のサービスと通信待ちをして await している時間はカウントされないのがポイントです。Cloudflareはオブジェクトストレージ R2 や分散SQLiteデータベース D1、画像加工・配信サービスのImagesなど幅広いサービスを提供していますので、ワーカでは簡単なデータの変換やリクエスト/レスポンスヘッダの書き換えやCloudflare固有の設定の付加などだけをするようにし、リソースの非自明な書き換えはこれらに投げるようにすることで、リッチなサービスが創れる、というのが Cloudflare Workers の使い方になります。
ここでポイントなのは、Cloudflare Workres は実体としては分散しつつ複数スレッドで並行に動く JavaScript ランタイムみたいなものであるということです。特に、リクエストやレスポンスのボディ、あるいはオブジェクトストレージ上のblobなんかのデータは、全て ReadableStream として扱われます。そして、ヘッダやメタデータを変更しても、ReadableStream は一切触らずにそのまま返してやれば、ボディがそのまま(任意の時間をかけて)ちゃんとサーヴされる、というのが Cloudflare Workers が限られた時間リソースの中で任意のデータを扱うことができる理由です。
ここで WAI を経由するために ReadableStream と Haskell の ByteString の変換を経由してしまうと、この「そのまま返す」ことが出来なくなってしまいます。なので、自前で Cloudflare Workres 特化版を実装する必要があった、という訳です。
また、Cloudflare Workers の Free Plan では圧縮後のバイナリが 1000KiB でないといけないので、ある程度内部実装を簡素化する必要があった、というのも動機の一つです。
上のリンクを踏むとわかりますが、たとえばこれを使って API 部分の Router は次のように書かれています:
apiRoutes ::
RestApi (AsWorker HumblrEnv)
apiRoutes =
RestApi
{ listTagArticles = listTagArticles
, listArticles = listArticles
, getArticle = getArticle
, adminAPI
}
listTagArticles :: T.Text -> Maybe Word -> App (Paged Article)
listTagArticles tag mpage = do
db <- getBinding "Database"
liftIO $ await' =<< db.listTagArticles tag mpage
putResource :: AuthResult User -> T.Text -> T.Text -> ReadableStream -> Handler HumblrEnv T.Text
putResource user slug name body = protectIfConfigured user $ do
storage <- getBinding "Storage"
liftIO $ await' =<< storage.put slug name body
resources :: [T.Text] -> POSIXTime -> T.Text -> Worker HumblrEnv Raw
resources paths expiry sign = Cache.serveCachedRaw imageCacheOptions $ Tagged \_ env _ -> do
let storage = Raw.getBinding "Storage" env
await' =<< storage.get GetParams {..}
-- ...
キャッシュについて
ルータでリクエストを処理する際に、Workers の Cache機能を使って記事のページや加工済のデータを一定時間キャッシュするようにしています(現時点では2週間くらい)。
記事の更新や削除などがあったらキャッシュを無効化する作業が必要になりますが、面倒なのでやっておらず、これはよくないですね。キャッシュ機構には削除機能があった筈なのでその内直します。
アクセス時によって値が異なり得るトップページやタグ記事一覧はキャッシュしてません。このへんはプロダクションだと色々知見があるんですかね。
上のコードを見てもわかりますが、一部のエンドポイントは自動的に Cache を問い合わせるミドルウェアみたいなものを書いて、それを呼び出して必要に応じてキャッシュを使うようにしています。
画像配信まわりについて
画像配信に係るのは Storage と Images Workersです。
Cloudflare は Images というストレージと加工(Transform)・配信を統合的に手掛けるサービスを展開しているんですが、無料プランではストレージ機能は使えません。
そこで、今回は画像は R2 (Cloudflare 版の S3、イグレス料金がかからない)に保存することにして、それを Transform 機能を使って加工し配信させることにしました。
問題は、投稿画像からメタデータを削除する必要があることです。
これは Transform 時に {metadata: none} オプションを渡せばそのようにできるのですが、それにはインターネットからアクセスできる場所に画像を配置する必要があります。
より具体的には、/cdn-cgi/image/... 以下にURLを渡すか、fetch関数の cf.image オプションでこれらの値を指定する必要がありますが、/cdn-cgi は Workers からは呼び出すことができないようなので、fetchを使うことになります[4] [5]。
以上を踏まえて、時限つきの署名済URLを発行し、そこに fetch することでメタデータの削除とリサイズを行うことにしました。
具体的な実装については、以下を参考にしました:
署名・検証は SubtleCrypto API が使えるので、JSFFI でその部分だけ呼び出してやることで実現しています。
署名鍵はKVに保存していて、Storageワーカからしか見えないようになっています。
まあ Images を買えばいいんですけど、ドメインにタダでついてきてるのと素振りのためですねこれは。
認証・認可系について
基本的には servant-auth を使えばよいのですが、これらは現状WASMバックエンドで使えない暗号系ライブラリ crypton や cryptonite に依存しているので、それらへの依存を削った servant-auth-lite をつくりました。
また、今回認証系は全部 Cloudflare Zero Trust に任せたかったので、そこ回りの機能も追加したものになっています。
crypton は利用できませんでしたが、Cloudflare Workers では SubtleCrypto API が使えますので、cryptonなどの提供する機能のかわりにこちらを使って比較的簡単に書き直すことができました。
フロントエンド
前述の通り Miso を使いました。Miso から内部の REST API を呼ぶ必要がありますので、ブラウザの Fetch API 経由で servant-client を使えるようにする必要がありました。これは servant-client-core の提供する RunClient のインスタンスを新しく定義すればいいのでそんなに大変ではありませんでした。
(とはいえ、JSの例外をちゃんとキャッチして Haskell で投げ直すみたいな必要はあったりしたので、何も考えなくていい訳じゃなかったですが)
あとはフロントから API へのアクセスは servant-client-fetch を使ってやり、リソースへのリンクは servant の静的リンク生成を使い、SPAのビューのルーティングには Miso の機能を使い、という形で、バックエンドと共有したAPI定義を Servant を介して使い回せて非常に楽でした。かなり体験がいい。
ルーティングとSSRの併用をどうすればいいのかのはっきりした公式ドキュメントがなかったのがちょっと面倒でしたが、そこを除けばかなり快適でした。データ型も(Aeson による JSON のデ/シリアライズを介したりして)シームレスにできるので、かなりよい。
おわりに
というわけで、フロントからバックまで全部 GHC WASM Backend をつかって Cloudflare Workers で動くブログシステムを書いたよ、という話でした。
前回はかなり単純な例でしたが、これで結構実用的なServerlessウェブアプリもHaskellで書けるぞ、ということがわかってもらえたのではないでしょうか。わからなかったら今わかってください。
以下、雑感です。
- 全ての局面でServantが使えてかなり楽
- API定義を一回しちゃえばそれを使い回して型レベルで安全性が保証されるのはかなり体験がよい
- 型レベルAPI定義が Single Source of Truth になるので、API構成の変更するとそれが型レベルの変更として全てに波及し、対応漏れをコンパイラが教えてくれる
- バイナリサイズ小さくするのがたいへん
- Service Bindings が何故要るのか最初ぜんぜんわからなかったんですが、確かにこれは細かくワーカを区切っていく形にして Bindings 越しに呼ぶのが想定される使い方だなというのがわかった
- それでも Haskell はランタイムシステムがデカいので、なかなかサイズを削るのに苦労しました
- モナド変換子やめて手書きの RIO パターンみたいなことをしたらだいぶ小さくなったのでよかった
- とはいえルータWorkerがまだ結構ギリギリなサイズなので、Servantの実装を見直しつつ、必要に応じて Cloudflare Worker 側の Routing や Custom Domain の利用を検討してもいいかもしれない
- Service Binding や Handler で Promise も返せるようにした
- やるだけなんですが、ちょっと設計を変える必要があるので要検討
- Miso の SSR のベクトプラクティスがわからない
- pre-rendered Body を配信する以外の方法は想定されていない?
- なんか Bluesky は OGP に基づいてリンクカード表示してくれるんだけど Twitter がしてくれない。なんで?誰かおしえて〜〜〜!
ではではそんな感じで。Happy Haskelling!
-
レンダリングじゃなくない?という話もありますが、定着しているしここではSSRと呼んじゃうことにします。Miso は Isomorphism と呼んでいるが、これはこれで数学用語と衝突してるし。 ↩︎
-
FreeのWASMバイナリの上限は圧縮後の容量が基準で、ドキュメントだと「1MB」、Wranglerだと「1MiB」とかかれています。前者は(今日では)十進接頭語、後者は二進接頭語なのでそれぞれ
10^6 2^{20} -
厳密には、ミドルウェアを定式化しやすいように、これを CPS 変換した
Request -> (Response -> IO ResponseReceived) -> IO ResponseReceivedがApplicationの定義になっています。 ↩︎ -
Service Bindings では他のワーカに直接
fetchを投げる機能がありますが、これへのcf.imageオプションは無視されるようだったので無理でした。 ↩︎ -
駄目元で自前で画像のリサイズをするワーカを実装もしてみたんですが、動かしてみたら案の定30秒とかかかっちゃうので駄目でした。 ↩︎
Discussion