DockerでOllama × Open WebUI を最小構成で起動し、ローカルLLMを試す
🧠 はじめに
ChatGPTのような大規模言語モデル(LLM)をローカル環境で動かしてみたいと思ったことはありませんか?
ChatGPTに入力された情報はOpenAIにその内容を利用されることがあるとされています。
そのため、ChatGPTの利用については個人情報や機密情報の入力に注意する必要があります。
多くの企業はファイルアップロード機能があるサービスの利用を制限しており、ChatGPTもその中に含まれます。
Ollama, ローカルLLM, Open WebUIの組み合わせはOpen WebUIへの入力をOllamaに引き渡し、ローカルLLMから回答を得るため、個人情報や機密情報の漏洩を気にすることなく、使用することが可能です。
本記事では、Ollama と Open WebUI を使って、最小構成のDocker環境で、ローカルAIチャットを立ち上げる方法を紹介します。
📝 用語解説
-
LLM
大規模言語モデル。OpenAIのChatGPTなどを総称してこのように呼ぶ。 -
ローカルLLM
LLMの中で特にクラウド環境ではなく、ローカルに構築されたLLMについてこのように呼ぶ。OpenAIやDeepSeekのようなクラウドLLM事業者にデータを提供しないため、個人情報や機密情報の利用にも安全と考えられている。 -
Ollama
LLMを使うための統一的なインターフェース。LLMをダウンロードしたり実行したりする環境を提供する。 -
Open WebUI
Ollamaを便利に使うためのウェブのインターフェース。OpenAIのChatGPTの画面に寄せて開発されているため、一般ユーザでも使いやすい。チャットのみでなく、ファイルアップロードやユーザ管理などの機能も同梱されている。
🛠️ 前提条件
- Docker がインストール済み(公式サイト)
- Docker Compose が使用可能
- ターミナル操作に慣れている方
- Git(任意)
- そこそこ高スペックのPC(筆者の環境はApple M4 chip, メモリ32GB、dockerへのメモリ割り当て20GB)

📦 リポジトリのクローン
筆者が公開しているgithubのレポジトリをcloneします。
git clone https://github.com/kondonator/ollama-open-webui.git
cd ollama-open-webui
🚀 起動方法
最初に.env.exampleを.envにコピーします。
次にWEBUI_SECRET_KEYを作成します。
Linux/macOSの場合:
openssl rand -base64 48
Windows PowerShellの場合:
[Convert]::ToBase64String((1..48 | ForEach-Object {Get-Random -Maximum 256}) -as [byte[]])
作成したWEBUI_SECRET_KEYを.envに記述します。
docker imageをpullします。
docker compose pull
docker containerを起動します。
docker-compose up
数秒で以下の2つのサービスが立ち上がります:
- ollama:ローカルでLLMを実行するAPIサーバ
- open-webui:ブラウザベースのチャットインターフェース
以下の表示が現れるまで待ちましょう。
Fetching 30 files: 100%|██████████| 30/30 [02:18<00:00, 4.63s/it]
open-webui-ui | INFO: Started server process [1]
open-webui-ui | INFO: Waiting for application startup.
open-webui-ui | 2025-05-14 09:38:18.730 | INFO | open_webui.utils.logger:start_logger:140 - GLOBAL_LOG_LEVEL: INFO - {}
open-webui-ui | 2025-05-14 09:38:18.730 | INFO | open_webui.main:lifespan:464 - Installing external dependencies of functions and tools... - {}
open-webui-ui | 2025-05-14 09:38:18.735 | INFO | open_webui.utils.plugin:install_frontmatter_requirements:185 - No requirements found in frontmatter. - {}
🌐 Open Web UI にアクセス
ブラウザで以下のURLを開きます。
http://localhost:3000
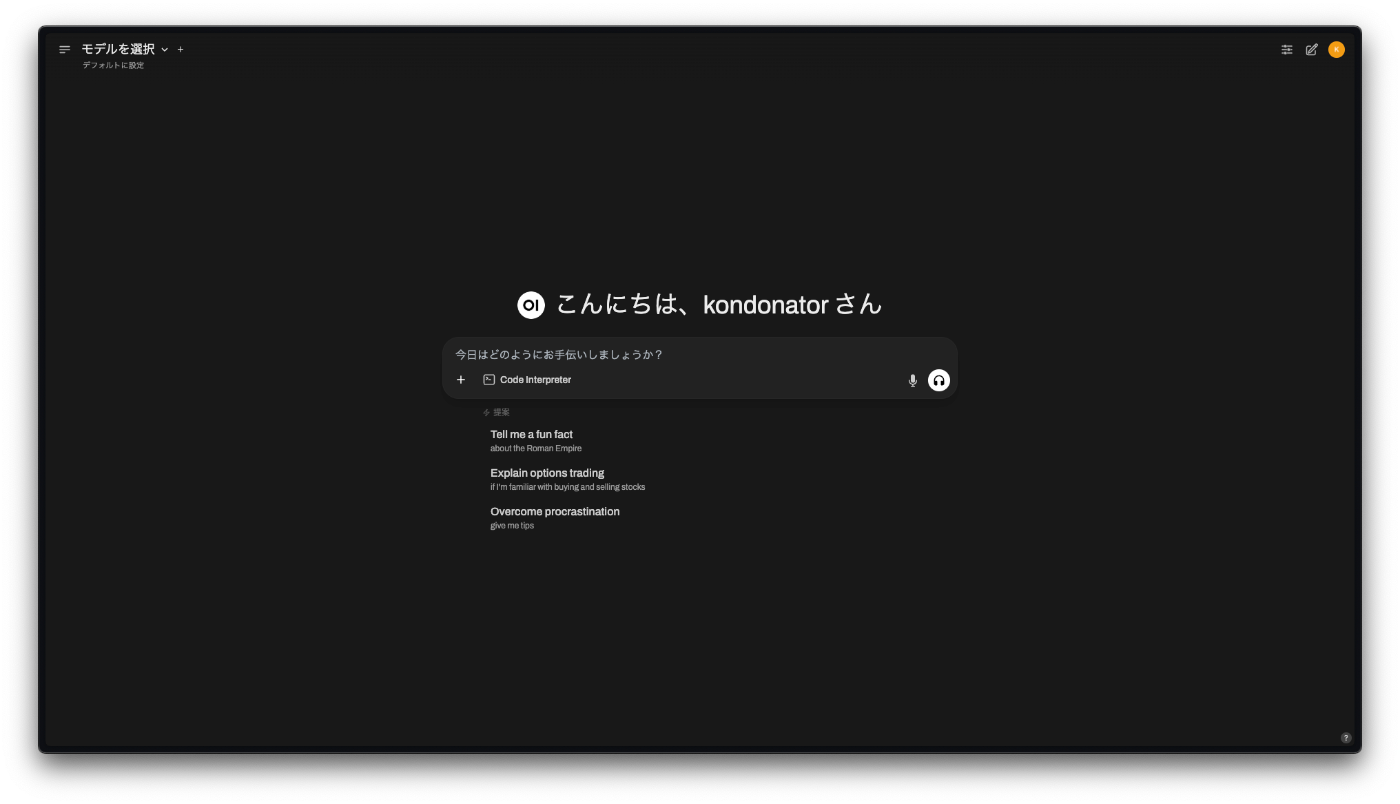
Open WebUI の起動画面が表示されます。

名前、メールアドレス、パスワードを入力して、管理者として登録します。

リリースノートが表示されます。

チャット画面が表示されます。
📥 モデルの読み込み
起動直後はモデルが読み込まれていないため、ターミナルから以下を実行してモデルを起動します。
以下はllama3モデルを取得する例です。
docker exec -it ollama ollama pull llama3
初回実行時は数GBのモデルデータをダウンロードします(インターネット接続が必要です)。
ollamaで利用可能なモデルはこちらから取得可能です。用途に応じて取得してください。
大きなモデルほどよりよい回答を得られますが、より大きなメモリ空間や高性能なCPU/GPUが必要になります。
✍️ 実際に使ってみる
-
ブラウザで localhost:3000 にアクセス
-
ユーザ登録
Google Accountでのユーザ登録とメールアドレスでのユーザ登録を選択することが可能です。

- モデル(例:llama3)を選択もしくはOpenWebUIでollamaにモデルをpullして選択
モデルをpull

モデルを選択

-
任意のプロンプトを入力
-
Ollama がローカルで応答を生成

この例では、llama3.1:8bとgemma3:12bにPR TIMESの不正アクセスによる情報漏えいの記事の要約を依頼しましたが。どちらも正しい回答を作成できませんでした。
ローカルLLMを使う場合、ウェブサイトのURLを引き渡しても、正しい回答を得ることができません。なので、ローカルLLMがウェブ検索を行えるように設定を変更する必要があります。
※プロンプト処理中は以下のようにCPUがゴリゴリに張り付きます。これは主にdockerの処理で張り付いているため、ollamaをdocker環境で使うのではなく、ローカル環境にインストールして、Open WebUIから使うように設定すれば問題なくなります。

🧹 停止・削除
docker-compose down
📚 まとめ
- Ollama × Open WebUI により、誰でもローカルでLLMを使える環境が簡単に構築可能
- モデルの切り替えやデータ永続化もDockerで柔軟に管理できる
🔗 参考リンク
以上です。
最後までお読み頂き、ありがとうございました!
Discussion