Soda SQLとStreamlitでポータブルなデータ品質チェックツールを実装する
以前、Great Expectationsを使ったデータバリデーションの仕組みについての記事を書きました。
Great Expectationsはデータに対するテスト実行とプロファイリングを実行し、結果をHTMLで出力してくれる、高機能で便利なツールでした。しかし、環境の構築や設定の準備に手間が掛かり、スモールスタートでテストだけ始めたいというような場合は導入のコストがネックになると思います。
一方で、Great Expectationと同様に有名なツールとして、Soda SQLというものがあります。こちらは、コマンドラインツールで、pipでインストールしてYAMLでテストやプロファイリングの設定を記述すればすぐに実行することができます。
ただし、テストやプロファイリングの実行結果はJSONになるので、Webブラウザでレポートを見たいといった場合には、自前でその仕組みを実装する必要があります。(もしくは、SaaSのSoda Cloudを使う手もあります。)
そこで、スキャン(テストとプロファイリング)を実行して、その結果をWebブラウザで確認できるような仕組みを実装してみました。スキャンはSoda SQLを使い、結果のレポートはStreamlitで表示するというものです。スキャン結果は外部のDBに保存するようにしています。そうすることで、過去のスキャン結果からの変化を分析することもできます。更には、Streamlit以外の任意のツールでもスキャン結果を閲覧できるというメリットもあります。
今回スキャン対象をBigQueryとしているため、スキャン結果もBigQueryに保存することにしました。また、Airflowなどのオーケストレーションツールでスキャンを実行したり、GKEやCloud Runなどでスキャン結果のレポーティングサービスを起動できるように、これらのツールはDockerイメージとして纏めています。以下が構成のイメージとなります。

ここでは、Soda SQLを実行するコンテナをスキャナー、Streamlitを実行するコンテナをレポーターと呼ぶことにします。
尚、ソースコードはGitHubにありますので参考にして頂ければと思います。
使用方法
スキャナーの実行
スキャナーではSoda SQLによってテーブルに対するテストとプロファイリングを実行します。そして、その結果をBigQueryのテスト結果テーブルとプロファイリング結果テーブルに書き込みます。そのため、以下の準備が必要になります。
-
warehouse.yml
Soda SQLがスキャン対象のDBへ接続するのに必要な設定を記述します。今回BigQueryに接続するので、以下のような設定で用意します。(warehouse.ymlの詳細はドキュメントを参照)
name: bigquery_lab connection: type: bigquery account_info_json_path: /app/scanner.json project_id: <your project-id> dataset: <your BigQuery dataset>ここで
account_info_json_pathはGoogle Cloudのサービスアカウントのクレデンシャル(JSON)へのパスを指定します。事前に、スキャン対象テーブルへの参照権限をもつサービスアカウントを用意しておいて、そのクレデンシャル(JSON)を作成しておきます。 -
scan.yml
Soda SQLがスキャン対象のテーブルに対して実行するテストの定義とプロファイリング項目の定義を記述します。(scan.ymlの詳細はドキュメントを参照)
table_name: category metrics: - row_count - missing_count - missing_percentage - values_count - values_percentage - invalid_count - invalid_percentage - valid_count - valid_percentage - avg_length - max_length - min_length - avg - sum - max - min - stddev - variance tests: - row_count > 0 columns: category_major_cd: valid_values: ['04', '05', '06', '07', '08', '09'] tests: - name: invalid_percent title: 04〜09の値を取る expression: invalid_percentage == 0 category_medium_cd: valid_format: number_whole tests: - invalid_percentage == 0 category_small_cd: valid_format: number_whole tests: - invalid_percentage == 0この例では、categoryテーブルに対するプロファイリングとテストを定義しています。
このようにSoda SQLのテストとプロファイリングの定義はシンプルで簡単です。エンジニアでなくても書けるのが良いところです。簡単に説明すると、 事前に用意されている集計方法のメトリクスの中からテストで使うものを
metricsに設定し、テーブル全体に対するテストはtestsに定義し、カラムごとに実行したいテストはcolumnsに定義します。尚、他のテーブルのレコードを使った(JOINなどする)複雑なテストをやりたい場合、カスタムメトリクスを定義することもできます。その場合は、sql_metricsでSQLを記述して、その結果に対するテストを定義します。カスタムメトリクスの詳細は、こちらを参照して下さい。 -
サービスアカウントのクレデンシャル
スキャン結果をBigQueryの書き込むためのサービスアカウントを用意しておいて、そのクレデンシャル(JSON)を作成しておきます。今回は、Soda SQLで使うテーブルスキャン用のサービスアカウントを流用します。
以上の準備が完了したら、スキャナーのコンテナを実行します。
docker run \
-e BQ_SA_KEY_JSON=/app/scanner.json \
-e PROJECT_ID=<your project-id> \
-e MEASUREMENTS_TABLE=<project-id>.<dataset>.<プロファイリング結果用テーブル> \
-e TEST_RESULTS_TABLE=<project-id>.<dataset>.<テスト結果用テーブル> \
-v /path/to/warehouse.yml:/app/warehouse.yml \
-v /path/to/scan.yml:/app/scan.yml \
-v /path/to/scanner.json:/app/scanner.json \
data-scanner:latest warehouse.yml category.yml
結果はBigQueryに以下のように保存されます。
-
テスト結果
テスト内容とテストがパスしたかなどの情報が記録されます。

-
プロファイリング結果
各カラムの最大値、最小値、平均値やテーブルのschemaなどのプロファイリング結果が記録されます。また、現在のschemaだけでなく、前回スキャン時からschemaが変化していないかもmetric =
schema_changeで記録されます。
レポーターの実行
レポーターでは、スキャナーがBigQueryに記録した各スキャン結果をもとにレポートを生成します。レポートはStreamlitによって作られており、テスト/プロファイリング結果テーブルに対してクエリを実行して表示しているだけです。
- テスト結果レポート
レポーターを起動します。
docker run \
-e BQ_SA_KEY_JSON=/app/scanner.json \
-e PROJECT_ID=<your project id> \
-e TEST_RESULTS_TABLE=<project-id>.<dataset>.<テスト結果用テーブル> \
-v /path/to/scanner.json:/app/scanner.json \
-p 8080:8080 \
data-reporter:latest test_report.py
テスト結果レポートでは、テストの成功を%表示し、失敗したテストがあった場合はそれらをリスト表示します。

- プロファイリング結果レポート
こちらも同様にレポーターを起動します。
docker run \
-e BQ_SA_KEY_JSON=/app/scanner.json \
-e PROJECT_ID=<your project id> \
-e MEASUREMENTS_TABLE=<project-id>.<dataset>.<プロファイリング結果用テーブル> \
-v /path/to/scanner.json:/app/scanner.json \
-p 8080:8080 \
data-reporter:latest profile.py
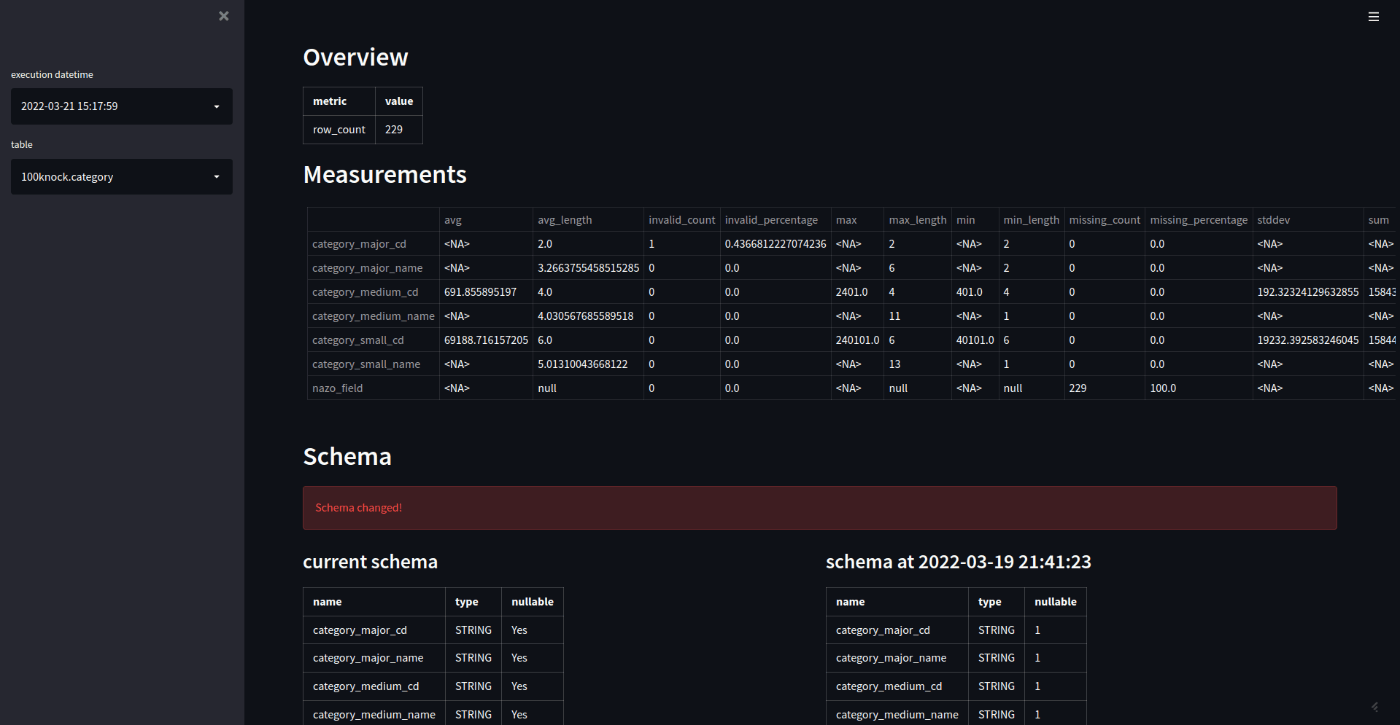
プロファイリング結果レポートでは、Overviewにテーブル全体のプロファイリング結果、Measurementsにはカラムごとのプロファイリング結果を表示します。そして、Schemaには、現在のschemaを表示しますが、前回スキャン時よりschemaに変更あった場合、その旨アラート表示し、併せて前回のschemaも表示します。
最後に
Soda SQLとStreamlitを使い、スキャン結果をBigQueryに保存することで、データ品質チェックの仕組みを簡単に実現することができました。この仕組みの特徴としては、テスト実行とレポーティングのシステムをDockerコンテナとして提供し、スキャン結果は任意のDB(今回はBigQueryだけ対応しました)に保存できるというところです。そのため、Soda SQL単体では実現できない、過去のスキャン結果との比較や時系列での可視化などにも活用できると思います。更に、既存システムとの統合の観点でも、AirflowのKubernetesPodOperatorでスキャナーを実行して、Cloud Runでレポーターをホスティングするといった使い方ができます。
また、Soda SQL自体は、MySQLやRedshiftなど様々なターゲットに対応しています。同様にスキャン結果の保存先もBigQueryだけでなくMySQLやオブジェクトストレージなどにも対応できると汎用性が増して便利な仕組みになるのではないかと考えています。
Discussion