slackとAWSでLLM ChatbotをServerlessで運用する
組織内のデータを使ってLLMによるチャットシステムを導入したいと考えたとき、ある程度実データを集めて関係者に実際に使ってもらいながら検証やチューニングを進めるのが良いのではないかと考えています。
そこで、すぐに組織内で運用を始められるよう、導入に関して敷居が低い構成を考えプロトタイプ実装してみたので紹介します。
チャットシステムの実装
アプリケーションはChatGPT/LangChainによるチャットシステム構築[実践]入門を参考に実装しています。
以下は、プログラミング言語MojoのREADME.mdを補足情報として参照可能な状態にしてgpt-3.5-turbo-16k-0613に質問をしています。
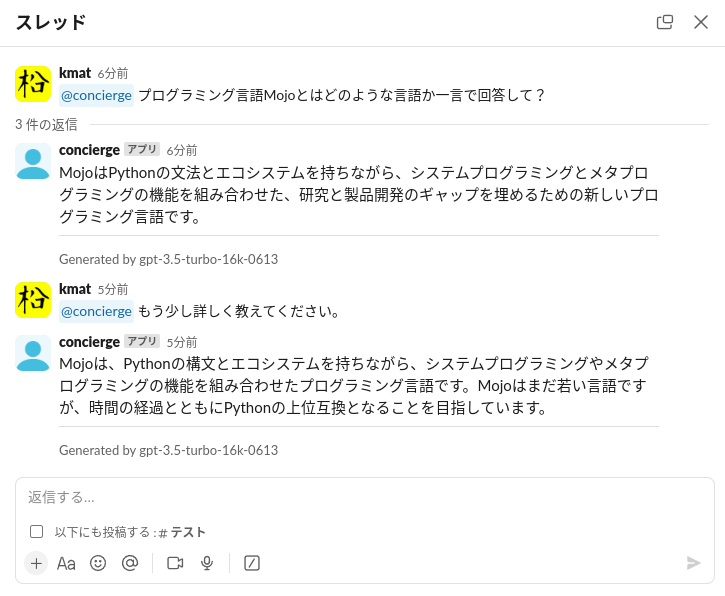
実際の利用イメージ
全体の処理の流れは次のようになります。
システムの特徴
- 検証開始時点から組織内のユーザーがサービスとして利用できる。
- 運用コストを最低限に抑えるためServerlessなコンポーネントで構成する。
- 利用サービスをslackとAWSだけにすることで運用開始の敷居を下げる。
- 本格運用を踏まえて、各コンポーネントを入れ替え可能なように疎結合で構成し、必要に応じスケールできる。
構成
システムの全体構成は以下になります。

LLM
メジャーかつ情報も多いため、OpenAIが提供するLLMのモデルを使います。現在、GPT-4系とGPT-3.5系があり、GPT-4系の方が利用料金が高くなります。検証では基本的にGPT-3.5系を使ってコストを抑え、必要に応じてGPT-4系に切り替えられるようにしておきます。
LLMの利用についてはOpenAIが提供するChat Completions APIを使います。
UI
チャットシステムをサービスとして提供する場合、Webアプリケーションを開発するという選択肢があります。一方で、組織内でslackなどのチャットサービスを利用しているのであれば、それをUIとして使ったほうが手軽に素早く展開できます。
今回はslackをチャットシステムのUIとして使います。
LLM Application Library
LLMを使ったアプリケーションの開発では、回答の精度を高めるために外部から情報を取得して文脈を補ったりするため、内部でチャットのパイプラインを構築する必要があります。
今回は、LLMに対して組織内にある情報を補足として与えたうえで回答を生成するようにするためRAG(Retrieval Augmented Generation)という手法を使います。
この手法に基づいたパイプラインを簡単に構築して利用するためLLMアプリケーション用のライブラリを使います。
有名どころではLangChainやLlamaIndexなどがありますが、より汎用的な用途で使えるLangChainを採用します。
LLM Application実行基盤
AWS上でServerlessで運用を開始したいためAWS Lambdaを選択します。
Vector Store
RAGにおいて、質問の都度 関連する情報をLLMに補足するため、事前にその情報を保存しておき検索と取得ができる必要があります。
ここで、その情報とはLLMが学習していない非公開の情報を想定しており、具体的には組織内の非公開情報などが挙げられます。
これらの情報はドキュメント(テキスト)として保存しておき、質問との関連度を基に効率的に検索できるようにそのドキュメントのベクトル表現と関連付けてデータベース化しておきます。
このデータベースシステムをVector Storeと呼びます。
Vector Storeには、SaaSとして提供されるPineconeやPaaSのAmazon OpenSearch Service、Azure Cosmos DB、またセルフホスト可能なQdrant、インメモリでも利用可能なchromaなどがあります。
今回、AWS内でServerlessで運用したいためLanceDBを採用します。(Amazon OpenSearch Service Serverlessという選択肢もありますが最低利用料金がそこそこ掛かるので見送りました。)LanceDBはデータをローカルファイルシステムやS3などのオブジェクトストレージに保存し、クライアントライブラリで検索処理を行うServerlessなVector Storeです。
ドキュメントとベクトル表現を保存するストレージとしてS3を使います。
会話履歴用のデータストア
GPT-4やGPT-3.5単体は単発のQ&Aには対応していますが、会話履歴を踏まえた回答には対応していません。そのため、質問側で会話履歴を踏まえた形で質問を構成する必要があります。つまり、会話履歴を保存しておく必要があります。特に、AWS Lambdaのように質問&回答のたびに起動される基盤ではインメモリで会話履歴を保持しておく方法が取れないためデータの永続化が必要になります。
今回はLangChainがサポートしているAmazon DynamoDBを使います。
実装のポイント
アプリケーションの実装のポイントを記載しておきます。
slackへの応答を3秒以内に返す
slackがメンション付きの質問を受けると、その内容をもってアプリケーション(on Lambda)にリクエストを投げます。そのリクエストに3秒以内に応答しないとslack側がtimeoutエラーとみなします。
質問への回答は概ね3秒以上かかるため、リクエストを受けたら即ackだけ返してtimeoutエラーを回避します。
slackからのリクエストを検証する
アプリケーションはLambdaでホストし、エンドポイントをインターネットに公開します。つまり、誰でもリクエストを送信して実行できる状態となります。
ただし、slackからのリクエストには事前に発行されたSigning Secretによる署名が付与されます。アプリケーションではリクエストに付与された署名をSigning Secretを使って検証することで、自分のslack Appからのリクエストであることを確認できます。
自分のslack App以外からのリクエストをLambdaにも到達させたくない場合は、Amazon API Gatewayなどを活用すると良さそうです。
なお、リクエストの検証と前述のack応答については、slackが提供するライブラリBolt for Pythonを使用することで自前で実装する必要がなくなります。
Serverless Vector Store LanceDB
前述の通り、Vector StoreとしてLanceDBを採用しています。
LanceDBは、コンピュート(検索やクエリ実行)とデータストレージを分離したアーキテクチャとなっています。そのため、サービスの進化に合わせて必要なリソースだけスケールさせることができます。
今回のように始めのうちはアプリケーション(on Lambda)にコンピュートを埋め込んで処理させる方式をとっておき、負荷が上がってきたらコンピュート部分だけECS taskなどにオフロードさせる方法やSaaSのLanceDB Cloudに移行する方法を取ることもできると思います。
また、LanceDB自体はデータ界隈に馴染みのあるPandas DataFrameやApache Arrowなどのエコシステムをベースにしているため個人的には扱い易いと感じています。
実装詳細
今回実装したアプリケーションは、ChatGPT/LangChainによるチャットシステム構築[実践]入門やLangChainのドキュメントを参照すれば簡単に実装できるので参考程度に載せておきます。
実装を理解するにはLLMアプリケーション特有の手法(特にRAG)に関する知識が必要です。
RAGで使用する文書の登録
アプリケーションの実行には事前にLanceDBへの文書登録が必要となります。
定期的に組織内の文書を登録する際、データパイプラインなどで実行することになると思いますのでコード化しておきます。
Markdown形式の文書をLanceDBに登録する場合、 python add_document.py XXXX.md のように実行します。今回データストレージとしてS3を選択したので、環境変数に LANCEDB_DB='s3://path/to/lancedb-data 、 LANCEDB_TABLE=table-name を設定しておきます。
import os
import sys
import lancedb
import pyarrow as pa
from langchain_community.document_loaders.markdown import UnstructuredMarkdownLoader
from langchain_community.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores.lancedb import LanceDB
def initialize_vectorstore():
db = lancedb.connect(os.environ["LANCEDB_DB"])
try:
table = db.open_table(os.environ["LANCEDB_TABLE"])
except FileNotFoundError:
schema = pa.schema(
[
pa.field("vector", pa.list_(pa.float32(), list_size=1536)),
pa.field("id", pa.string()),
pa.field("text", pa.string()),
pa.field("source", pa.string()),
]
)
table = db.create_table(
os.environ["LANCEDB_TABLE"],
schema=schema,
)
embeddings = OpenAIEmbeddings()
return LanceDB(
table,
embeddings,
)
if __name__ == "__main__":
file_path = sys.argv[1]
loader = UnstructuredMarkdownLoader(file_path)
raw_docs = loader.load()
text_splitter = CharacterTextSplitter(
chunk_size=300,
chunk_overlap=30,
)
docs = text_splitter.split_documents(raw_docs)
vectorstore = initialize_vectorstore()
vectorstore.add_documents(docs)
アプリケーション本体
import json
import logging
import os
import re
import time
from typing import Any
import lancedb
import slack_bolt
from langchain.chains.conversational_retrieval.base import ConversationalRetrievalChain
from langchain.memory.buffer import ConversationBufferMemory
from langchain_community.chat_message_histories import DynamoDBChatMessageHistory
from langchain_community.chat_models.openai import ChatOpenAI
from langchain_community.embeddings.openai import OpenAIEmbeddings
from langchain_community.vectorstores.lancedb import LanceDB
from langchain_core.callbacks.base import BaseCallbackHandler
from langchain_core.outputs.llm_result import LLMResult
from slack_bolt.adapter.aws_lambda import SlackRequestHandler
INITIAL_CHAT_UPDATE_INTERVAL_SEC = 1
SlackRequestHandler.clear_all_log_handlers()
logging.basicConfig(
format="[%(levelname)s] %(message)s",
level=logging.INFO,
)
logger = logging.getLogger(__name__)
def initialize_conversation_memory(id_ts: str) -> ConversationBufferMemory:
history = DynamoDBChatMessageHistory(
table_name=os.environ["DYNAMODB_TABLE"],
session_id=id_ts,
)
return ConversationBufferMemory(
chat_memory=history,
memory_key="chat_history",
return_messages=True,
)
def initialize_vector_store() -> LanceDB:
db = lancedb.connect(os.environ["LANCEDB_DB"])
table = db.open_table(os.environ["LANCEDB_TABLE"])
embeddings = OpenAIEmbeddings()
return LanceDB(
table,
embeddings,
)
app = slack_bolt.App(
signing_secret=os.environ["SLACK_SIGNING_SECRET"],
token=os.environ["SLACK_BOT_TOKEN"],
process_before_response=True,
)
class SlackStreamingCallbackHandler(BaseCallbackHandler):
last_send_time = time.time()
message = ""
def __init__(self, channel, ts):
self.channel = channel
self.ts = ts
self.interval = INITIAL_CHAT_UPDATE_INTERVAL_SEC
self.update_count = 0
def on_llm_new_token(self, token: str, **kwargs) -> None:
self.message += token
now = time.time()
if now - self.last_send_time > self.interval:
app.client.chat_update(
channel=self.channel, ts=self.ts, text=f"{self.message}\n\nTyping..."
)
self.last_send_time = now
self.update_count += 1
# update update-interval 2x when update_count become bigger than 10x of update-interval
if self.update_count / 10 > self.interval:
self.interval = self.interval * 2
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> Any:
message_context = f"Generated by {os.environ['OPENAI_API_MODEL']}"
message_blocks = [
{
"type": "section",
"text": {
"type": "mrkdwn",
"text": self.message,
},
},
{"type": "divider"},
{
"type": "context",
"elements": [
{"type": "mrkdwn", "text": message_context},
],
},
]
app.client.chat_update(
channel=self.channel,
ts=self.ts,
text=self.message,
blocks=message_blocks,
)
def handle_mention(event, say):
channel = event["channel"]
thread_ts = event["ts"]
message = re.sub("<@.*>", "", event["text"])
id_ts = event["ts"]
if "thread_ts" in event:
id_ts = event["thread_ts"]
result = say("\n\nTyping...", thread_ts=thread_ts)
ts = result["ts"]
memory = initialize_conversation_memory(id_ts)
vector_store = initialize_vector_store()
slack_callback = SlackStreamingCallbackHandler(
channel=channel,
ts=ts,
)
llm = ChatOpenAI(
model_name=os.environ["OPENAI_API_MODEL"],
temperature=os.environ["OPENAI_API_TEMPERATURE"],
streaming=True,
callbacks=[slack_callback],
)
condense_question_llm = ChatOpenAI(
model_name=os.environ["OPENAI_API_MODEL"],
temperature=os.environ["OPENAI_API_TEMPERATURE"],
)
cr_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=vector_store.as_retriever(),
memory=memory,
condense_question_llm=condense_question_llm,
)
cr_chain.run(message)
def just_ack(ack):
ack()
app.event("app_mention")(
ack=just_ack,
lazy=[handle_mention],
)
def lambda_handler(event, context):
header = event["headers"]
logger.info(json.dumps(header))
if "x-slack-retry-num" in header:
logger.info(
f"SKIP > x-slack-retry-num: {header['x-slack-retry-num']}",
)
return 200
slack_handler = SlackRequestHandler(app=app)
return slack_handler.handle(event, context)
参考: https://github.com/yoshidashingo/langchain-book/blob/main/chapter8/app.py
依存ライブラリは以下になります。
langchain
langchain-experimental
openai
slack-bolt
boto3
tiktoken
lancedb
pandas
依存ライブラリを含めたアプリケーションのサイズがzip圧縮後の50MB制限(Lambdaの制限)を超える可能性があるのでコンテナとしてデプロイします。
FROM public.ecr.aws/lambda/python:3.10
COPY requirements.txt ${LAMBDA_TASK_ROOT}
RUN pip install -r requirements.txt
COPY lambda_function.py ${LAMBDA_TASK_ROOT}
CMD [ "lambda_function.lambda_handler" ]
データの同期とプロンプトエンジニアリング
一旦運用を開始したら、RAGで使用するデータを定期的に同期する仕組みやプロンプトエンジニアリング周りの継続的な改善などが必要になるかと思います。
これらの点についてもこれから知見をためていきたい次第です。
Discussion