初めてのGo言語
第1章
go run
go runの仕組みとしては、
-
go run hoge.goでバイナリファイルがビルドされ一時ディレクトリにおかれる - そのファイルを実行する
- プログラムの終了後、そのファイルが削除される
go build
go runで作成される一時的なバイナリファイルを再利用できるようにしたい場合は、go build hoge.goで実行形式ファイルが同じディレクトリに生成される
go mod
go modでgo.modファイルが生成される
パブリックなモジュールを作成したい場合は github.com/{module_name} とする必要がある
go mod tidyで .go ファイルを自動的に解析して、サードパーティーのライブラリのダウンロードや不要になったファイルの削除などを行ってくれる
go install
他人が公開しているソースを go install コマンドでインストールすることができる
コードの公開方法は多くの言語とは異なり、ソースコードのリポジトリ(GitHub etc.)を介して共有する
go install github.com/hoge/fuga@latest で $GOPATH/bin または go/bin の下にバイナリがインストールされる
go fmt
書いたGoのソースコードを標準の形式にフォーマットしてくれる
第2章
基本型
- 宣言されたが値が割り当てられていない変数にはデフォルトのゼロ値が割り当てられる
- ダブルクオート(
")とシングルクオート(')で囲まれた文字の扱いが異なる-
'はruneリテラル(文字)を、"は文字列リテラルを表す -
"で生成された文字列リテラルは、0個以上のruneリテラルのスライス
-
浮動小数点数型
-
float32とfloat64の2種類がある - 浮動小数点リテラルのデフォルトの方は
float64なので、よっぽど特別な場合を除きfloat64を使うのを推奨されている
第3章 合成型
スライス
- golangにおいて、配列は制約が多すぎるため使わない
- その代わり、可変長の配列とも言えるスライスを使う
// [n] あるいは [...] と書くと配列になる
// 下記のように書くだけでスライスを定義できる
x := []int{10,20,30}
- スライスのゼロ値は
nil- スライス同士の比較はできない
- スライスと比較ができるのは nil のみ
- スライスはキャパシティ(容量)を持っており、あらかじめ一定個の連続する領域が確保されている
- スライスのlenがキャパシティに達するとそれ以上の値を記憶できなくなる
- すると Go のランタイムがより大きなキャパシティを持つスライスの領域を自動的に確保する
- 自動でキャパシティを増やしてくれるのは悪いことではないが、あらかじめキャパシティがわかっている場合は指定した方が効率的(領域を余分に確保してしまうのと、コピーに時間がかかるようになってくる)
- キャパシティの指定方法は
make関数でできる
append
- スライスの要素を増やすには
append関数を使う- 第一引数に値を入れたいスライスを、第二引数にその値を指定する
x := []int{10,20,30}
x = append(x, 40) // これにより x には 10, 20, 30, 40 の値が入る
x = append(x, 50, 60, 70) // 複数の値も指定可能
- 演算子
...を使うことで、スライスの個々の値を展開することができ、スライス同士の結合も行うことができる
x := []int{10,20,30}
y := []int{100,200,300}
x = append(x, y...) // x には 10, 20, 30, 100, 200, 300 が入る
make
- 以下のように、スライスの型と長さおよびキャパシティを指定できる
x := make([]int, 5) // 長さとキャパシティが5のスライスが作成される
- makeで作成したスライスに
appendを使って要素を追加するのは "誤り"- 以下のようなコードだと、作成したスライスの末尾に要素が追加されてしまい、意図せずキャパシティが増えてしまう
x := make([]int, 5)
x = append(x, 10) // x = [0, 0, 0, 0, 0, 10] になってしまい、capacityも10に増える
-
makeで作成したスライスにappendで要素を追加したい場合は、makeでキャパシティも指定してあげる必要がある
x := make([]int, 0, 10) // 長さが0, キャパシティが10 のスライス
x = append(x, 1, 2, 3) // x = [1, 2, 3] になり長さは3、キャパシティは10のまま
- golangでは文字列を表現するのにバイト列を扱っている
- 絵文字や漢字などを使っている場合は 注意が必要
-
len関数を使っても 意図した文字列の長さを得られない
var s string = "Hello ☀"
fmt.Println(len(s)) // 7 ではなく、9 が出力される
- int を型変換によって、stringに変換することもできない
- int値がバイトとして認識され、それに対応する文字列になってしまうため
var x int = 65
var y = string(x)
fmt.Println(y) // 65 ではなく、A と出力される
4章 ブロック、シャドーイング、制御構造
変数のシャドーイング
以下のような関数を実行した場合、1行目に10、2行目に5、3行目に10が出力される
func main() {
x := 10
if x > 5 {
fmt.Println(x)
x := 5
fmt.Println(x)
}
fmt.Println(x)
}
5行目にあるような変数x(これをシャドーイング変数という)があると、外側のブロックの変数(隠蔽された変数)にはアクセスできなくなる
シャドーイング変数のあるブロックを抜けると、隠蔽されていた変数にアクセスすることができるようになる
こういったシャドーイングが発生していることを検知してくれるリンターツールがある
if文
大まかに他の言語と同じ(goではifの後に(...)は必要ない)
他の言語と違って、goの便利なところは以下のように if と else の両方のブロックで有効な変数を宣言することができる
func main() {
rand.Seed(time.Now().Unix())
if n := rand.Intn(10); n == 0 { // nはelseのブロックまで有効になる
fmt.Println("少し小さすぎます:", n)
} else if n > 5 {
fmt.Println("大きすぎます:", n)
} else {
fmt.Println("いい感じの数字です:", n)
}
// fmt.Println(n) をここで書くとnは未定義のため、エラーになる
}
この場合、変数nは if/else を抜けると未定義となる
for-range
for-rangeで注意が必要なのは、繰り返し処理が行われる際の合成型の各要素の値は変数にコピーされる点
コピーされた変数の値を変更しても、元々の値は変わらない
evanVals := []int{2, 4, 6, 8, 10}
for _, v := range evanVals {
v += 2 // v は evanVals の各要素のコピー
}
fmt.Println(evanVals) // 2, 4, 6, 8, 10 と出力される
5章 関数
- Goは静的型付けの言語なので、引数の型の指定は必須
- 同じ型の引数を複数渡す場合は、以下のように書くことができる
func div(numerator, denominator int) int { // numeratorのあとのintを省略
戻り値の無視
- 呼び出した関数が複数の戻り値を返しても、そのうちの一つ以上を読み込む必要がない場合は以下のように書ける
result, _ := divAndRemainder(5,2) // 使わない戻り値は _ (ブランク識別子)に代入する
名前付き戻り値
- 戻り値を変数として定義する場合はシャドーイングが起こっていないか注意する
- Goの重大な欠陥である
ブランクreturnに気を付ける- 名前付き戻り値を使うと、戻り値を指定せずに return だけを書くことができる
- ただ、何が返り値となるのかが分かりづらくなる(結果コードを遡ることになる)
- この本では、
関数が値を返すなら、絶対にブランクreturnを使ってはならないと推奨している
無名関数
以下のように関数内で別の関数を定義することができる
deferやgoroutineなどで役に立つ
func main() {
for i := 0; i < 5; i++ {
func(j int) {
fmt.Println("無名関数の中で", j, "を出力")
}(i) // ここで引数jにiを渡している
}
}
クロージャ
- 関数 f からしか呼び出されないが、関数 f から何度も呼び出されるような関数 g があるとき、その関数 g を他の関数から隠すために 関数内の関数(クロージャ)が使われる
- また、ローカル変数を参照するクロージャを作成して、そのクロージャを別の関数に渡すことで、局所変数を外でも使えるようになる
6章 ポインタ
ポインタとは
- ある値が保存されているメモリ内の位置(アドレス)を表す変数
- どの変数も、1byteもしくは連続した数byteのメモリ領域に保存されている
- 変数の型によって、保存に必要なメモリの量が異なる
- ポインタのゼロ値は
nil- ポインタで実装されている slice、map、関数といった型のゼロ値も
nilとなる
- ポインタで実装されている slice、map、関数といった型のゼロ値も
- アドレス演算子
&を変数の前につけるとその変数のアドレスを返す- その返された値はポインタ型になる
x := "hello"
pointerX := &x // pointerX の型は ポインタ型
- ポインタ型の変数の前に
*をつけると、そのポインタ型の変数が示すアドレスに保存されている値を取得することができる(これをデリファレンスという)- nil のポインタをデリファレンスすると、パニックエラーになってしまうので、必要であれば nil チェックを入れる
x := 10
pointerX := &x
fmt.Println(pointerX) // アドレスが出力される
fmt.Println(*pointerX) // デリファレンスされて、10が出力される
- ポインタ型の変数を var を使って宣言する場合は、
そのポインタが指す領域に保存される値の型の前に*をつける- デリファレンスされる値の型を指定するので、
*をつける必要がある
- デリファレンスされる値の型を指定するので、
x := 10
var pointerX *int
pointerX = &x
- 定数をポインタに変換する場合はヘルパー関数を使うようにする
ポインタを使うメリット
- そもそもとしてGoは値渡し言語
- 呼び出された関数の引数は参照ではなく値のコピーが渡されるので、引数の値を操作したい場合や、複数の関数で一つのオブジェクトを共有したい場合はポインタを渡さなければいけない
- ポインタはアドレス値を保存しているだけで比較的軽い(8byte)ので、大きな構造体を引数に渡すことも可能になる。値渡しの場合、大きな構造体のコピーを作成するのにリソースを消費してしまうため、引数に構造体を渡す場合はポインタを使うことが推奨されている
参考:https://qiita.com/y-kaanai/items/f397bb4a539cfae6112b
7章 型、メソッド、インターフェース
- Goでは継承(inheritance)ではなく、合成(composition)を推奨している
- 最近のソフトウェア工学のトレンドらしい
Goの型
- Goで使われる全ての型は、抽象型か具象型のいずれかに分けられる
- 型を使うメリット
- 変数の型を指定することで、その変数に代入できる値を限定し、間違った操作を行わないようにする
- 演算の対象を特定の型に限定することで、間違った値を演算の対象とすることを防ぐ
- 特定の型に対して共通して行われる操作(メソッド)を記述することで、その型を統一的に扱えるとともに、対象外の値や変数に対してその操作を行なってしまうことを防ぐ
メソッド
- 以下のように、特定の型に紐づく関数(操作)をメソッドとして定義できる
-
funcと メソッド名 の間に(p Person)という形でレシーバを指定する - これによって、メソッドがレシーバで指定した特定の型
Personに紐づく
-
- オーバーロードできない
- 特定の型に紐づくメソッドは全て違う名前にしないといけない
-
コードが何をしているかはっきりさせるというGoの哲学に則っている
type Person struct {
LastName string
FirstName string
Age int
}
func (p Person) String() string {
return fmt.Sprintf("%s %s:年齢%d歳", p.LastName, p.FirstName, p.Age)
}
ポインタ型レシーバと値型レシーバ
- 関数内で引数の値が変更される可能性がある場合は、ポインタ型の引数を指定する
- これはメソッドのレシーバについても同じ
- レシーバと渡し方にも ポインタレシーバ と 値レシーバ がある
- どちらをどの状況で使うかのルールは以下の通り
- メソッドがレシーバを変更するなら ポインタレシーバを使わなければいけない
- メソッドが
nilを扱う必要があれば ポインタレシーバを使わなければいけない - メソッドがレシーバを変更しないなら、値レシーバを使うことができる
- 型にポインタレシーバのメソッドが一つでもあれば、レシーバを変更しないものも含めて全てのメソッドにポインタレシーバを使って形式を揃えるのが一般的なルール
- さっきの
Person型に対して、ポインタレシーバを持つメソッドは以下のようになる
func (p *Person) GetOld() {
p.Age++
}
- main関数などでメソッドを呼び出す場合は以下のようになる
func main() {
var p Person
fmt.Println(p.String())
p.GetOld() // (&p).GetOld() と書かなくても良い
fmt.Println(p.String())
}
- コメント部分について
- ポインタレシーバに対してポインタではない値型のローカル変数を渡すと、Goは自動的に変数をポインタ型に変換してくれる
- ただ、関数に値を渡す際のルールは依然として適用される
- 関数にポインタ型ではない引数を渡して、その値を使ってポインタレシーバのメソッドを呼び出すのは間違い
func doGetOldWrong(p Person) { // 間違い
p.GetOld() // mainのpのコピーに対してGetOldが行われる
fmt.Println(p.String())
}
func doGetOldRight(p *Person) { // 正しい
p.GetOld() // mainのpに対してGetOldが行われる
fmt.Println(p.String())
}
func main() {
var p Person {
Age: 12
}
doGetOldWrong(p) // p.Ageは12のまま
doGetOldWrong(&p) // p.Ageは13になる
}
メソッド値とメソッド式
- メソッド値
- 以下のように、返り値があるメソッドを値として扱うことをメソッド値という
type Adder struct { // 構造体Adderの定義
start int // int型のフィールドstartをもつ
}
func (a Adder) AddTo(val int) int { // 型Adderをレシーバとするメソッドを定義
return a.start + val // フィールドstartの値に、引数の値valを足して戻す
}
myAdder10 := Adder{start: 10}
fmt.Println(myAdder10.AddTo(5))
// こういうこともできる
f1 := myAdder10.AddTo // Adder型の変数myAdder10のメソッドAddToをf1に代入
fmt.Println(f1(10)) // 20
- メソッド式
- 元になっているインスタンスのフィールドに保存されている値にアクセスできる
- そのため、以下のように型自体から関数を作成でき、これをメソッド式という
- メソッド式の場合、最初の引数はメソッドのレシーバとなる
f2 := Adder.AddTo // 型Adderをレシーバとして定義されているメソッドAddToをf2に代入
fmt.Println(f2(myAdder10, 15)) // レシーバとしてmyAdder10を指定
Goにおける型宣言と継承の違い
- オブジェクト指向の中心概念として「継承」がある(2つのクラスに継承関係があると、「親」の方の状態やメソッドが「子」の方でも使用できるなど)
- Goでも以下のように、ある型をベースに別の型を宣言すると、継承関係があるように見えるが、これは両方の方が同じ型をベースにしているというだけで、それぞれの型の間に継承関係は存在しない
- そのため、メソッドはそれぞれで定義しないといけない(EmployeeはPersonのメソッドは使えない)
type Person struct {
LastName string
FirstName string
Age int
}
type Employee Person // Person型をベースにした新たな型
「型はドキュメント」
- ユーザー定義型を宣言する、それ即ち型に対して何らかの意味・概念を持たせるということ
- コードを読む際にも、メソッドの引数に int 型 を持たせるよりも、概念が理解できる適切な名前の型を持たした方が意図がはっきりする
埋め込みによる合成
Goには継承はないが、合成(composition) や 昇格(promotion) が組み込まれている
以下のように Manager に 名前が付かない Employee 型のフィールドは 埋め込みフィールド となる
埋め込みフィールドで宣言されているフィールドおよびメソッドは、それを埋め込んでいる上位の構造体に昇格し、その構造体から直接呼び出せるようになる
type Employee struct {
Name string
ID string
}
func (e Employee) Description() string { // 従業員に関する記述
return fmt.Sprintf("%s (%s)", e.Name, e.ID)
}
type Manager struct {
Employee // 型のみ書く(埋め込みフィールド)NameとIDが加わる
Reports []Employee // 部下 Employeeのスライス
}
fmt.Println(m.ID) // Employeeが持つフィールドに直接アクセスできる
fmt.Println(m.Description()) // Employeeが持つメソッドに直接アクセスできる
埋め込みと継承の違い
- 先のコード例の場合、Manager 型の変数を Employee 型の変数に代入するようなことはできない
var e Employee = m // コンパイルエラーになる
// 正しくは var e Employee = m.Employee
- 埋め込まれたフィールドのメソッド(例の場合だと
e.Description())は上位(Manager)の構造体のメソッドセットに含まれるようになる- そのため、Manager に同名のメソッド
Description()があっても、m.Description()は Employee のメソッドを使うことになる - この内包関係はインターフェースの実装で使われる
- そのため、Manager に同名のメソッド
インタフェース
- interface とは、Goで唯一の抽象型(実装を提供しない型)で以下の2つの側面を持つ
- メソッドの集合:特定のクラスが満たすべき要件(実装するべき一群のメソッド)を示す
- 型: 変数がインタフェースを基盤とする型を持つことで、任意の型の値を代入できる変数の定義などができる
-
interface{}のようにメソッドが空の場合、「0個のメソッドが定義された型」となるため、任意の型がこの条件を満たすことになる。これにより、interface{}と宣言された変数には、任意の型の値を代入できる。Go 1.18ではanyと書けるようになったので、型として使う場合については今後はanyと書くのがいいかも。
-
interface の宣言方法
type Stringer interface { // インタフェースの宣言
String() string // 実装するメソッドのリスト
}
interfaceの名前は er で終わるものが一般的(io.Reader, io.Closer, http.Handler など)
暗黙のインタフェース
あるインタフェースIのメソッドセットを、具象型Cのメソッドセットが完全に含めていれば、具象型CはインタフェースIを実装することになる。
これにより、具象型Cの変数などはインタフェース型Iを持つを宣言された変数やフィールドに代入できる。
インターフェースとnil
interface がnilとみなされるためには、型と値の両方がnilでなければならない
interfaceは ベースとなる型へのポインタ と ベースとなる値へのポインタ の組で実装されるため、どちらかがnilでない場合は interface はnilにならない
interface がnilの場合、実装されているどのメソッドを起動してもパニックエラーになる
空インタフェース interface{} または any を使うのは出来る限り避ける
(静的型付け言語であるGoではイディオム的ではない)
依存性注入
依存性注入(Dependency Injection: DI)とは、コードが自分の仕事を行うために必要な機能を明示的に示すべきだというコンセプトのこと
例)
上位のモジュール(例えば 車)が下位のモジュール(例えば タイヤ)に依存してはいけない
下位から上位への依存は問題ないが、上位から下位への依存は禁止するべき
なぜなら、現在使用しているタイヤをスタットレスタイヤに替えたいとなった場合に、車という上位モジュールが今使っているタイヤに依存してしまっている場合は、上位モジュールである車に変更を加えないといけなくなる
上位から下位への依存が無い場合は、上位モジュールに変更を加えずに下位モジュールのみを取り替えることが出来るので、保守性が向上する
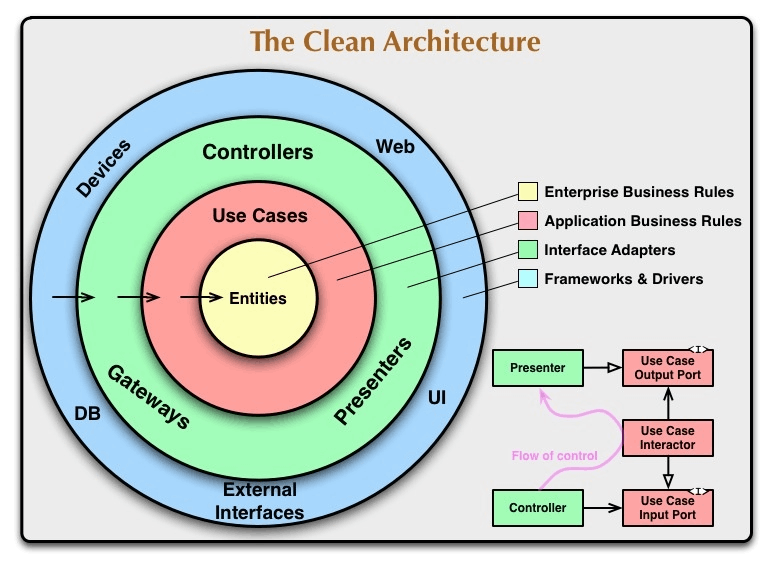
クリーンアーキテクチャでよく見るこの図
依存方向を下位から上位(図だと外側から内側)へのみに縛っていることを意味している
8章 エラー処理
エラー処理の基本
関数から error 型を戻すことによってエラーを処理する(これは絶対に破るべきではない慣習)
- 関数が期待通りに実行された場合は
errorにはnilが返却される - 関数の動作がうまくいかなかった場合は、エラーを表す値が返される
- 呼び出し側で
errorの値を nil チェックして、エラー処理を行う
何かしらのエラーを戻す場合は、他の戻り値はそれぞれの型のゼロ値に設定するべき
error 自体はinterfaceであり、以下の Error() メソッドを実装しているものが error とみなされる
( interface のゼロ値は nil であるため、エラーでない場合は error に nil が入る)
type error interface {
Error() string
}
エラーの際の文字列の利用
Goの標準ライブラリでは文字列からエラーを生成する2つの方法がある
-
errors.New関数を使って、呼び出し側で受け取ったerrorをfmt.Printlnで出力する -
fmt.Errorf関数を使って、呼び出し側で受け取ったerrorをfmt.Printlnで出力する-
fmt.Errorfは verb (%s,%d,%lなど) が使える -
%wでエラーのラップが行える- エラーフォーマット文字列の最後に
%wを追加して、呼び出し側でerrors.Unwrapでアンラップすると、エラーの文字列に加えて付帯情報を付け加えることができる
- エラーフォーマット文字列の最後に
-
センチネルエラー
エラーにより処理を開始あるいは継続できないことを示すために使われる
標準ライブラリには Err で始まる特定のエラーを表す変数があり、出力された error がそれと一致する場合に処理を中断することができる
func main() {
data := []byte("This is not a zip file")
nonZipFile := bytes.NewReader(data)
_, err := zip.NewReader(nonZipFile, int64(len(data)))
if err == zip.ErrFormat { // センチネルエラー
fmt.Println("ZIP形式ではありません")
}
}
Is と As
戻されたエラー、あるいはラップしたその他のエラーが特定のセンチネルエラーのインスタンスにマッチする場合は errors.Is を使ってそのエラーの比較ができる
func fileChecker(name string) error {
f, err := os.Open(name)
if err != nil {
return fmt.Errorf("in fileChecker: %w", err)
}
f.Close()
return nil
}
func main() {
err := fileChecker("not_here.txt")
if err != nil {
if errors.Is(err, os.ErrNotExist) {
fmt.Println("That file doesn't exist")
}
}
}
また、errors.As を使うと戻されたエラーが特定の型にマッチするかをチェックできる
err := AFunctionThatReturnsAnError()
var myErr MyErr
if errors.As(err, &myErr) {
fmt.Println(myErr.Code)
}
特定のインスタンスあるいは特定の値を探しているときは errors.Is を使います。特定の型 を探しているときは errors.As を使います。
エラー時のスタックトレースの取得
プログラムがうまくいかずにエラーになった場合、スタックトレースを取得して調査の助けとしたい。
Goはデフォルトではスタックトレースを表示しないが、サードパーティのライブラリにコールスタックを自動的に生成してくれるものがある。
有名なのは https://github.com/pkg/errors
9章 モジュールとパッケージ
Goのライブラリは リポジトリ、モジュール、パッケージ の3つの概念で管理される
リポジトリはモジュールから構成(基本的に一つのリポジトリで一つのモジュールを管理する)され、モジュールは複数のパッケージから構成される
標準ライブラリ以外のパッケージのコードを利用する場合は、自分のプロジェクトをモジュールとして宣言する必要があり、すべてのモジュールはユニークな識別子を持つ。通常はリポジトリへのパス(github.com/hoge/fuga)を使用する
go.mod
Goのソースコードの集合がモジュールとなり、ルートディレクトリに適切な go.mod ファイルが必要になる
go.mod は手動で作成・編集することはせず、go mod コマンドを使って管理する
// go.mod ファイルの作成
$ go mod init ${MODULE_PATH}
モジュールをimportする際は、相対パスは使わずに絶対パスを使用することが推奨されている
絶対パスを使ったほうが何をインポートするかが明確になる
go mod tidy でソースファイルを見て、モジュールのダウンロードを行なってくれる
モジュールの構成方法
プロジェクトの規模が大きくなると、コードを理解しやすく保守しやすくするために何らかのルールが必要になってくる。
モジュールのルートに cmd というディレクトリを作って、その中に1つの機能に対して1つのディレクトリを用意するのが一般的。( cmd の中に main.go を置くのが通例 )
以下のブログが参考になる。
以下のように同名のパッケージをインポートする必要がある場合は、パッケージ名を crand のようにオーバーライドして使うことができる
import (
crand "crypto/rand"
"encoding/binary"
"fmt"
"math/rand"
)
importブロックにて、.と_を利用することができる
.はインポートされたパッケージのなかのすべてのエクスポートされた識別子(大文字で始まるもの)を現在のnamespaceに置くことができる(参照するのにプレフィックスがいらない)。ただ、自前のパッケージで宣言した識別子なのか外部のものなのかの区別がつかなくなるので、推奨はされていない 。
また、_ を使った場合はパッケージ内のエクスポートされた識別子にアクセスできなくなる。その代わりに識別子が全く使われていなくてもエラーにならなくなる。
少なくともエクスポートされる識別子にはコメントが必要
内部パッケージ
関数、型、定数をモジュール内の複数パッケージで共有したいが、APIの一部として公開したくない場合は、内部パッケージ名(internal)を使う。ディレクトリ名も internal にする。
internal パッケージでエクスポートされた識別子は直接の親パッケージと、その親パッケージの子(同列のディレクトリにあるパッケージ)からのみアクセス可能となる。
init関数
引数なしで値を返さない init という名前の関数を宣言しておくと、そのパッケージが外部から参照されたときにinit関数を最初に実行してくれる。(パッケージの状態をセットアップしてくれる)
データベースドライバなどのパッケージはデータベースドライバの登録に init 関数を使っている。そのため、普通にドライバをimportするとそのドライバが使われていないと判断してエラーになってしまう。
そのエラーを避けるために、さっきのブランクインポート( _ でパッケージ名をオーバーライドする)を使う。
Goでは 循環参照は禁止されている 。これは高速なコンパイルと、ソースコードの理解の容易さというGoの大きなコンセプトを保つために決められている。
循環参照とは、パッケージAがパッケージBをインポートしているときに、パッケージBがパッケージAをインポートするということ。
循環参照が行われる原因はパッケージを細かく分け過ぎていることが大概なので、循環参照がされるような場合はそのパッケージ同士を一つのパッケージに合体するのが望ましい。
サードパーティのコードのインポート
標準ライブラリである fmt errors os math などは Goをインストールした時点で含まれるものなので import ブロックに追加するだけで使用することができる。
しかし、サードパーティのパッケージを使用する場合は go mod tidy を実行して、パッケージを go.mod に追加する必要がある。
Go 1.17以降では、go.mod には require ディレクティブが2つ書かれるが、1つ目の方は直接の依存先であるモジュールが記載され、2つ目の方は間接的な依存先(直接的に依存しているモジュールが依存しているモジュール)が自動で記載される。2つ目の方にはモジュール名の後に // indirect と書かれる。
10章 並行処理
そもそも、並行処理(concurrent processing)あるいは並行性(concurrency)とは ひとつの処理を独立した複数のコンポーネントに分割し、そのコンポーネント間で安全にデータを共有しながら処理を実行すること
並行と並列は全くの別物
並行処理は複数のタスクを1箇所で同時に扱うこと、並列処理は複数のタスクを複数箇所で同時に実行することです。これだと少しわかりにくいと思うのでレジを思い浮かべてください。2つ行列があって、これが処理すべき2つのタスクだとします。2つの行列(タスク)を一つのレジで順番に処理していくのが並行処理、2つの行列(タスク)を2つのレジで同時に処理するのが並列処理です。
並行性を持ったコードが並列に実行されるかどうかはハードウェアやアルゴリズムに依存する(同時に複数のCPUを使う etc.)
なので、並行性が増したとしても高速化に繋がるとは限らない
並行性を利用するべきなのは 独立に処理できる複数の操作から生成されるデータを利用する場合
また、並行に実行される時間がそこまで長くない場合は普通に書いたほうが良い。一般的にインメモリで行われるアルゴリズムは非常に速いので、並行性でのデータの受け渡しによる速度よりも並列に複数の処理を実行することで得られる速度の方が速いケースが多い。
一定の時間内に、複数の外部サービスへの呼び出し結果をインプットとして、その計算結果をアウトプットとしたいケースなどに並行性が有効。
goroutine
ゴルーチンを理解する上で必要な用語
- プロセス
- 具体的なプログラムがコンピュータのOSによって実行されているもの
- OSはコンピュータリソース(メモリなど)をプロセスと紐付け、他のプロセスがアクセスできないように制御してくれる
- スレッド
- プロセスはひとつ以上のスレッドから構成される
- スレッドは実行単位のことで、OSからその実行に許されている時間が与えられている
- ひとつのプロセス内のスレッドはリソースのアクセスを共有している
- CPUは同時に複数のスレッドを実行することができ、それらをスケジューリングすることで、すべてのプロセスが実行されることになる
ゴルーチンはGoのランタイムによって生成される軽量なスレッドであり、所謂本当のスレッドより軽量であるため、起動・生成が早く、メモリ利用やスケジューリングを最適化することができ、大量のゴルーチンを同時に動かすことが可能になっている。
チャネル
ゴルーチンでは情報のやりとりにチャネルを使う。
チャネルを生成する際は以下のように、キーワード chan とチャネルでやり取りする型を指定する。
ch := make(chan int)
チャネルはマップ同様に参照型のため、引数としてチャネルを渡すときはチャネルへのポインタを渡すことになる。また、チャネルのゼロ値は nil 。