NewSQLでベクトル検索!? RAGの新たな選択肢。TiDB Serverlessにベクトル列の追加が発表。
はじめに
今年、2024/2/1にPingCAP(TiDB)より発表されたTiDB ServerlessにてMySQL互換なデータベースかつNewSQLデータベースにおける組み込みのベクトル検索ができる機能が追加されました。
今回は、このベクトル検索機能についてを実際に試し、まとめていきます。
※本機能は、TiDB Serverlessにて追加されたもので、現時点ではプライベートβという扱いとなっております。もし、検証されたい場合は、下記のWait Listより申し込みいただければと思います。
TiDB Serverlessにおけるベクトル検索
TiDBにおけるベクトル検索の対応というのは、要は、TiDBのデータベース上のテーブルにVectorカラムを作成できるようになったアップデートとなります。
その為、既存のデータと共存する形で生成AIなどで利用するEmbeddingしたベクトルデータを保存したり、テキスト、画像、ビデオ、オーディオ、あらゆる種類のデータのセマンティック検索や類似検索を実装する際に利用することができます。

なぜMySQL互換のデータベースでベクトル検索が必要なのか?
現在、OpenAIを筆頭に生成AIのビジネス利用については、IT業界だけではなく様々な業界が注目、活用しています。
その中でも自社のデータや、大規模学習モデルが学習していない、もしくは自分好みに、ビジネス利用に寄せる用途で**RAG(Retrieval-Augmented Generation)**が注目されています。
RAGを簡単に説明するのであれば、ユーザーのクエリに対して外部(LLMが学習していない)知識を検索させ、そのデータとLLMが学習しているデータを含めてLLMに回答を生成させる手法を指します。
そこで使われるデータストアというのが、Vector Storeと呼ばれるものです。
現時点においてVector Storeを提供しているサービスは数多く存在しています。
実際にRAGを組んだり、LLMを使ったアプリケーションを作成する際によく利用されるフレームワークにLangchainと呼ばれるものが存在します。
そのLangchainに対応しているVector Storeについては、下記のリンクを見ると一覧を見ることができます。
Vector Storeを単体でサービスとして提供しているものもあれば、既存のデータベースにVectorカラムとして対応したものの存在しています。
もちろんTiDBにおいてもLangchainでは公式に対応しており、利用することができます。
では、なぜ、Vector Storeを単体でサービスとして提供しているもののある中で、TiDBのような既存のデータベースにVectorカラムを追加するような機能追加をしたのでしょうか?
最近ですと、AWSが提供しているRDS(Amazon Relational Database Service for PostgreSQL)にて、pgvectorをサポートしたというものがありました。
こちらも既存のRDS(PostgreSQLに限る)にて、ベクトル検索をさせることができるものになっています。
このアップデートも、今回のTiDBのアップデートも、ベクトル検索が既存のデータベースの中でできることで、クトル検索機能を備えたリレーショナルデータベースとして、データと埋め込まれたベクトルデータをまとめて1つのデータベースに保存することができることが一番大きなポイントなのではないでしょうか。
これらを異なる列を使用して同じテーブルに保存したり、別のテーブルに分割して後でVector SearchクエリやJOINを使用して取得したりできるので、他のVector Storeサービスとは違い、よりサービス、ビジネスロジックに近いところでLLMの利活用を進めることができると考えています。これが、既存のVector Storeとは大きく異なることですね。
実際にやってみよう
では実際にやってみましょう!
今回は3部構成で、TiDBデータベースの作成から、基本的な動作をし、その後、Amazon Bedrockで提供されているembedding モデルを使用し、langchainから、TiDBとBedrockを使用して検証します。最後に、LlamaIndexとTiDB Serverlessを使ったRAGアプリケーションを構築し、動作させることをしていきます。
1: 基本の動作
基本の動作からやっていきましょう。
基本動作については下記のLangchainのDocsで公開されている内容を進めていきます。
TiDB ServerlessのDBクラスターを作成
まずは、TiDBコンソール画面にて、ベクトル検索ができるデータベースを作成していきます。

TiDBサーバレスのデータベースクラスターが作成できましたね!
そうしたら、右上のConnectから接続していきます。
この際、Generate Passwordをすると、接続する際のパスワードが自動生成されます。

TiDBへMySQLクライアントを通し接続
過去の記事でも取り上げているように、TiDBはMySQL互換のNewSQLデータベースです。
そのため、ローカルから接続する際にMySQLクライアントのツールから接続することができます。
mysql --comments -u 'xxxxx' -h xxxxx.eu-central-1.prod.aws.tidbcloud.com -P 4000 -D 'test' --ssl-mode=VERIFY_IDENTITY --ssl-ca=/etc/ssl/cert.pem -p'xxxxxxx'

基本的な操作
まずは、5次元ベクトルフィールドを含むテーブルを作成し、5つのレコードを挿入します。
> CREATE TABLE vector_table(embedding VECTOR);
> INSERT INTO vector_table VALUES ('[5.3, 6.2, 4.7, 9.4, 3.2]'),('[7.4, 8.3, 3.6, 9.5, 1.5]'),('[1.6, 5.3, 3.9, 4.9, 3.4]'),('[4.6, 6.2, 2.9, 5.5, 2.4]'),('[8.2, 2.7, 5.9, 4.5, 1.1]');
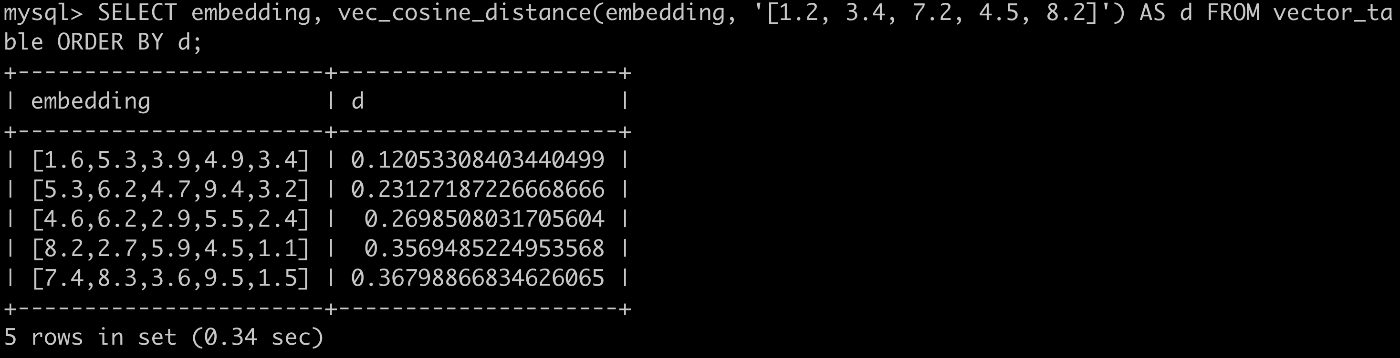
作成できたVectorカラムを含むテーブルに、コサイン距離によってベクトルの最近傍を取得します。
SELECT embedding, vec_cosine_distance(embedding, '[1.2, 3.4, 7.2, 4.5, 8.2]') AS d FROM vector_table ORDER BY d;
Vector Index(HNSWインデックス)を作成してみましょう。
HNSWインデックスは、ベクトル検索に適したインデックスとなります。
HNSWインデックスを作成すると、テーブルを定義するときにベクトル検索クエリを高速化させることができます。
たとえば、コサイン距離を使用してHNSWインデックスを作成するには、次のように設定します。
CREATE TABLE vector_table_with_index (id int PRIMARY KEY, doc TEXT, embedding VECTOR(3) COMMENT "hnsw(distance=cosine)");
TiDBにおいて現時点でできるベクトル距離関数
- Cosine Distanceを求める関数です。
SELECT vec_cosine_distance('[1,1,1]', '[1,2,3]');

- Manhattan Distanceを求める関数です。
SELECT vec_l1_distance('[1,1,1]', '[1,2,3]');

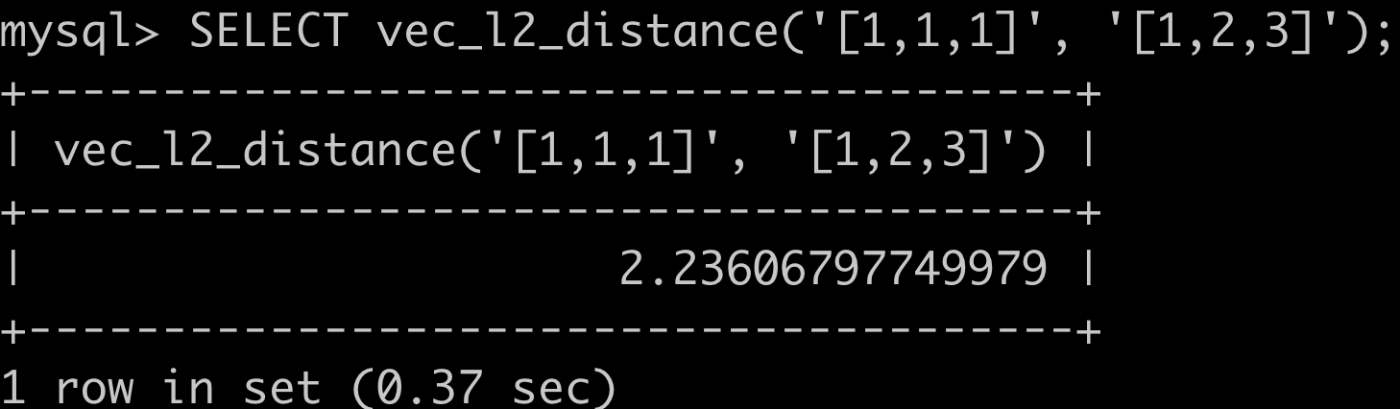
- Squared Euclideanを求める関数です。
SELECT vec_l2_distance('[1,1,1]', '[1,2,3]');
- Negative Inner Productを求める関数です。
SELECT vec_negative_inner_product('[1,1,1]', '[1,2,3]');

2: Amazon Bedrockと組み合わせて使ってみよう
次は、Embeddingするモデルについてを、Amazon Bedrockの中でTitan Embeddings G1を使用していきます。

まずは必要なライブラリをインストールしていきます。
pip install langchain
pip install pymysql
pip install tidb-vector
pip install boto3
ファイル構成は下記のような形で、用意します。

[vector-test.py]
# Here we useimport getpass
import getpass
import os
## 下記には、実際に接続するTiDBクラスターの情報を記載します。
###############################################
tidb_connection_string = "mysql+pymysql://xxユーザ名xx.root:xxパスワードxxxx@gateway01.eu-central-1.prod.aws.tidbcloud.com:4000/test?/etc/ssl/cert.pem&ssl_verify_cert=true&ssl_verify_identity=true"
###############################################
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import TiDBVectorStore
from langchain_community.embeddings import BedrockEmbeddings
loader = TextLoader("./state_of_the_union.txt")
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = BedrockEmbeddings(
region_name="us-east-1",
model_id='amazon.titan-embed-text-v1'
)
TABLE_NAME = "vector_table2"
db = TiDBVectorStore.from_documents(
documents=docs,
embedding=embeddings,
table_name=TABLE_NAME,
connection_string=tidb_connection_string,
distance_strategy="cosine", # default, another option is "l2"
)
query = "What did the president say about Ketanji Brown Jackson"
docs_with_score = db.similarity_search_with_score(query, k=3)
for doc, score in docs_with_score:
print("-" * 80)
print("Score: ", score)
print(doc.page_content)
print("-" * 80)
docs_with_relevance_score = db.similarity_search_with_relevance_scores(query, k=2)
for doc, score in docs_with_relevance_score:
print("-" * 80)
print("Score: ", score)
print(doc.page_content)
print("-" * 80)
[state_of_the_union.txt]には、下記のテキストを利用しました。
Madam Speaker, Madam Vice President, our First Lady and Second Gentleman. Members of Congress and the Cabinet. Justices of the Supreme Court. My fellow Americans.
Last year COVID-19 kept us apart. This year we are finally together again.
Tonight, we meet as Democrats Republicans and Independents. But most importantly as Americans.
With a duty to one another to the American people to the Constitution.
And with an unwavering resolve that freedom will always triumph over tyranny.
Six days ago, Russia’s Vladimir Putin sought to shake the foundations of the free world thinking he could make it bend to his menacing ways. But he badly miscalculated.
He thought he could roll into Ukraine and the world would roll over. Instead he met a wall of strength he never imagined.
He met the Ukrainian people.
・
・
・
では、このコードが何をしているのでしょうか。
解説していきましょう。
まず、TiDBでは、コサイン距離('cosine')とユークリッド距離 ('cosine'、'l2') の両方をサポートしており、'cosine' がデフォルトの選択です。
今回は、cosineを使いました。
注目いただきたいのは下記のコードで、これは、上記で読み込ませたテキストデータをTiDBのvectorカラムに入れた後に、similarity_search_with_scoreという関数を使用し、コサイン距離が小さいほど類似性が高いことを示すスコアを表示させることをしていました。
その後の、さらに、similarity_search_with_relevance_scores メソッドを使用することで、関連性スコアを取得することもできます。
query = "What did the president say about Ketanji Brown Jackson"
docs_with_score = db.similarity_search_with_score(query, k=3)
for doc, score in docs_with_score:
print("-" * 80)
print("Score: ", score)
print(doc.page_content)
print("-" * 80)
docs_with_relevance_score = db.similarity_search_with_relevance_scores(query, k=2)
for doc, score in docs_with_relevance_score:
print("-" * 80)
print("Score: ", score)
print(doc.page_content)
print("-" * 80)
[実行結果]
> python3 vector-test.py
--------------------------------------------------------------------------------
Score: 0.6762022576520199
Tonight, I’m announcing a crackdown on these companies overcharging American businesses and consumers.
And as Wall Street firms take over more nursing homes, quality in those homes has gone down and costs have gone up.
That ends on my watch.
Medicare is going to set higher standards for nursing homes and make sure your loved ones get the care they deserve and expect.
We’ll also cut costs and keep the economy going strong by giving workers a fair shot, provide more training and apprenticeships, hire them based on their skills not degrees.
Let’s pass the Paycheck Fairness Act and paid leave.
Raise the minimum wage to $15 an hour and extend the Child Tax Credit, so no one has to raise a family in poverty.
Let’s increase Pell Grants and increase our historic support of HBCUs, and invest in what Jill—our First Lady who teaches full-time—calls America’s best-kept secret: community colleges.
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Score: 0.684098958154944
Vice President Harris and I ran for office with a new economic vision for America.
Invest in America. Educate Americans. Grow the workforce. Build the economy from the bottom up
and the middle out, not from the top down.
Because we know that when the middle class grows, the poor have a ladder up and the wealthy do very well.
America used to have the best roads, bridges, and airports on Earth.
Now our infrastructure is ranked 13th in the world.
We won’t be able to compete for the jobs of the 21st Century if we don’t fix that.
That’s why it was so important to pass the Bipartisan Infrastructure Law—the most sweeping investment to rebuild America in history.
This was a bipartisan effort, and I want to thank the members of both parties who worked to make it happen.
We’re done talking about infrastructure weeks.
We’re going to have an infrastructure decade.
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Score: 0.6912720469121771
And for our LGBTQ+ Americans, let’s finally get the bipartisan Equality Act to my desk. The onslaught of state laws targeting transgender Americans and their families is wrong.
As I said last year, especially to our younger transgender Americans, I will always have your back as your President, so you can be yourself and reach your God-given potential.
While it often appears that we never agree, that isn’t true. I signed 80 bipartisan bills into law last year. From preventing government shutdowns to protecting Asian-Americans from still-too-common hate crimes to reforming military justice.
And soon, we’ll strengthen the Violence Against Women Act that I first wrote three decades ago. It is important for us to show the nation that we can come together and do big things.
So tonight I’m offering a Unity Agenda for the Nation. Four big things we can do together.
First, beat the opioid epidemic.
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Score: 0.3237977423479801
Tonight, I’m announcing a crackdown on these companies overcharging American businesses and consumers.
And as Wall Street firms take over more nursing homes, quality in those homes has gone down and costs have gone up.
That ends on my watch.
Medicare is going to set higher standards for nursing homes and make sure your loved ones get the care they deserve and expect.
We’ll also cut costs and keep the economy going strong by giving workers a fair shot, provide more training and apprenticeships, hire them based on their skills not degrees.
Let’s pass the Paycheck Fairness Act and paid leave.
Raise the minimum wage to $15 an hour and extend the Child Tax Credit, so no one has to raise a family in poverty.
Let’s increase Pell Grants and increase our historic support of HBCUs, and invest in what Jill—our First Lady who teaches full-time—calls America’s best-kept secret: community colleges.
--------------------------------------------------------------------------------
--------------------------------------------------------------------------------
Score: 0.31590104184505596
Vice President Harris and I ran for office with a new economic vision for America.
Invest in America. Educate Americans. Grow the workforce. Build the economy from the bottom up
and the middle out, not from the top down.
Because we know that when the middle class grows, the poor have a ladder up and the wealthy do very well.
America used to have the best roads, bridges, and airports on Earth.
Now our infrastructure is ranked 13th in the world.
We won’t be able to compete for the jobs of the 21st Century if we don’t fix that.
That’s why it was so important to pass the Bipartisan Infrastructure Law—the most sweeping investment to rebuild America in history.
This was a bipartisan effort, and I want to thank the members of both parties who worked to make it happen.
We’re done talking about infrastructure weeks.
We’re going to have an infrastructure decade.
Bedrockを使用して実際に検証してみましたが、ちゃんと動作していることが分かりますね。
3: LlamaIndex と TiDB Serverlessを使ったRAGアプリケーション
最後に、LlamaIndex と TiDB Serverlessを使ったRAGアプリケーションを実行していきます。
コードは下記になるので、利用してみてください。
> git clone https://github.com/pingcap/tidb-vector-python.git
> cd tidb-vector-python/examples/llamaindex-tidb-vector-with-ui
> python3 -m venv .venv
> source .venv/bin/activate
> pip install -r requirements.txt
> export OPENAI_API_KEY="sk-*******"
> export TIDB_HOST="gateway01.*******.shared.aws.tidbcloud.com"
> export TIDB_USERNAME="****.root"
> export TIDB_PASSWORD="****"
では起動してみましょう。下記のコマンドを実行するとローカルサーバが立ち上がりUIが表示されます。
# prepare the data
python app.py prepare
# runserver
python app.py runserver
今回は、私が以前書いたTiDBに関するブログを読み取り、RAGアプリケーションを作成していきます。
def do_prepare_data():
logger.info("Preparing the data for the application")
documents = SimpleWebPageReader(html_to_text=True).load_data(
["https://zenn.dev/koiping/articles/79e8c4161b991b"]
)
tidb_vec_index.from_documents(documents, storage_context=storage_context, show_progress=True)
logger.info("Data preparation complete")
実際のコード
[app.py]
import os
import sys
import json
import logging
import click
import uvicorn
import fastapi
import asyncio
from enum import Enum
from sqlalchemy import URL
from fastapi.encoders import jsonable_encoder
from fastapi.responses import StreamingResponse, HTMLResponse, JSONResponse
from fastapi.templating import Jinja2Templates
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.core.base.response.schema import StreamingResponse as llamaStreamingResponse
from llama_index.vector_stores.tidbvector import TiDBVectorStore
from llama_index.readers.web import SimpleWebPageReader
logging.basicConfig(stream=sys.stdout, level=logging.INFO)
logger = logging.getLogger()
class EventType(Enum):
META = 1
ANSWER = 2
logger.info("Initializing TiDB Vector Store....")
tidb_connection_url = URL(
"mysql+pymysql",
username=os.environ['TIDB_USERNAME'],
password=os.environ['TIDB_PASSWORD'],
host=os.environ['TIDB_HOST'],
port=4000,
database="test",
query={"ssl_verify_cert": True, "ssl_verify_identity": True},
)
tidbvec = TiDBVectorStore(
connection_string=tidb_connection_url,
table_name="llama_index_rag_test",
distance_strategy="cosine",
vector_dimension=1536, # Length of the vectors returned by the model
drop_existing_table=False,
)
tidb_vec_index = VectorStoreIndex.from_vector_store(tidbvec)
storage_context = StorageContext.from_defaults(vector_store=tidbvec)
query_engine = tidb_vec_index.as_query_engine(streaming=True)
logger.info("TiDB Vector Store initialized successfully")
def do_prepare_data():
logger.info("Preparing the data for the application")
documents = SimpleWebPageReader(html_to_text=True).load_data(
["https://zenn.dev/koiping/articles/79e8c4161b991b"]
)
tidb_vec_index.from_documents(documents, storage_context=storage_context, show_progress=True)
logger.info("Data preparation complete")
# https://stackoverflow.com/questions/76288582/is-there-a-way-to-stream-output-in-fastapi-from-the-response-i-get-from-llama-in
async def astreamer(response: llamaStreamingResponse):
try:
meta = json.dumps(jsonable_encoder(list(vars(node) for node in response.source_nodes)))
yield f'{EventType.META.value}: {meta}\n\n'
for i in response.response_gen:
yield f'{EventType.ANSWER.value}: {i}\n\n'
await asyncio.sleep(.1)
except asyncio.CancelledError as e:
print('cancelled')
app = fastapi.FastAPI()
templates = Jinja2Templates(directory="templates")
@app.get('/', response_class=HTMLResponse)
def index(request: fastapi.Request):
return templates.TemplateResponse("index.html", {"request": request})
@app.get('/ask')
async def ask(q: str):
response = query_engine.query(q)
return StreamingResponse(astreamer(response), media_type='text/event-stream')
@click.group(context_settings={'max_content_width': 150})
def cli():
pass
@cli.command()
@click.option('--host', default='127.0.0.1', help="Host, default=127.0.0.1")
@click.option('--port', default=3000, help="Port, default=3000")
@click.option('--reload', is_flag=True, help="Enable auto-reload")
def runserver(host, port, reload):
uvicorn.run(
"__main__:app", host=host, port=port, reload=reload,
log_level="debug", workers=1,
)
@cli.command()
def prepare():
do_prepare_data()
if __name__ == '__main__':
cli()
入力されている内容が質問を理解し、適切な回答を作成してくれていますね!

TiDBならではの機能
ここからは、TiDBでベクトル検索をした際に得られる恩恵の話をしていきましょう。
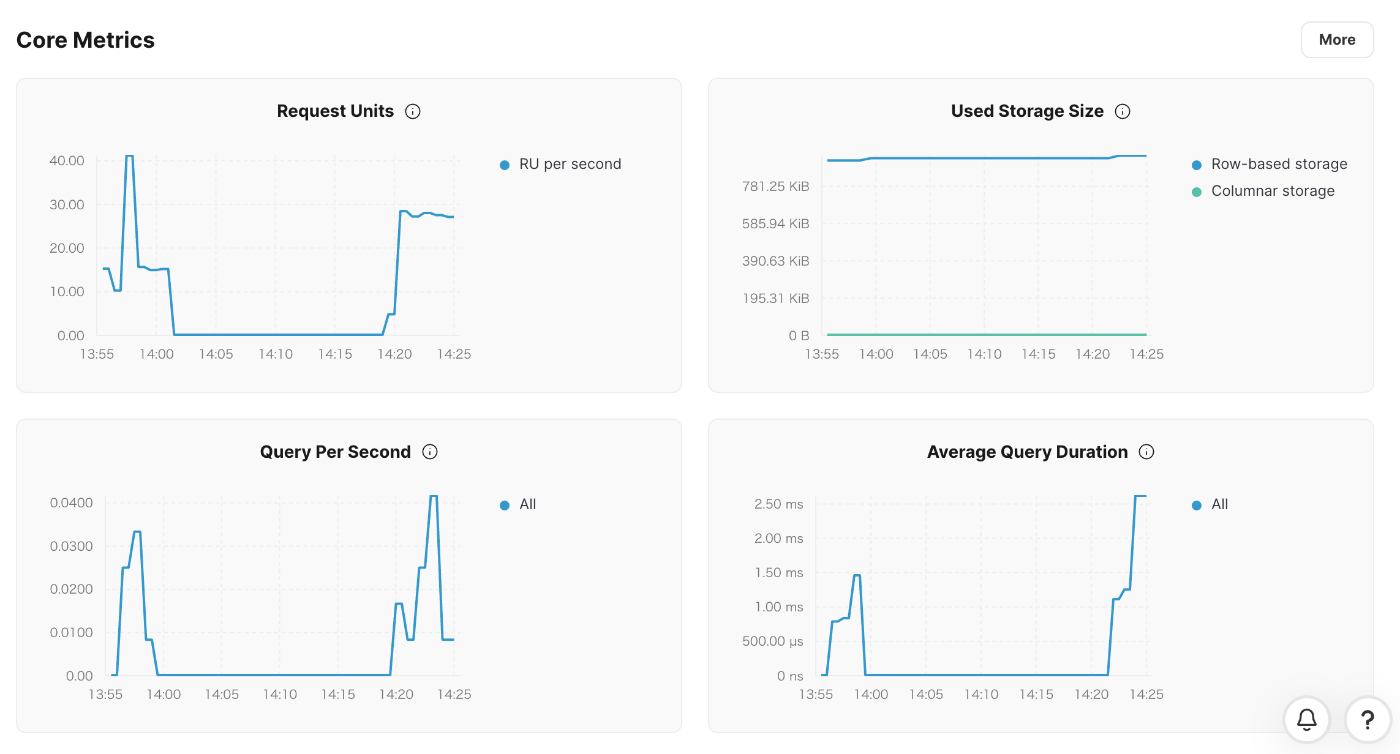
例えば、下記のようにこれまで検証してきたベクトル検索の検証について、TiDBコンソール上でのメトリクスを確認することはもちろんできます。
また、実行されたSQLのslow queryを検索することもできますし、実際に実行されたSQLステートメントも確認することができます。
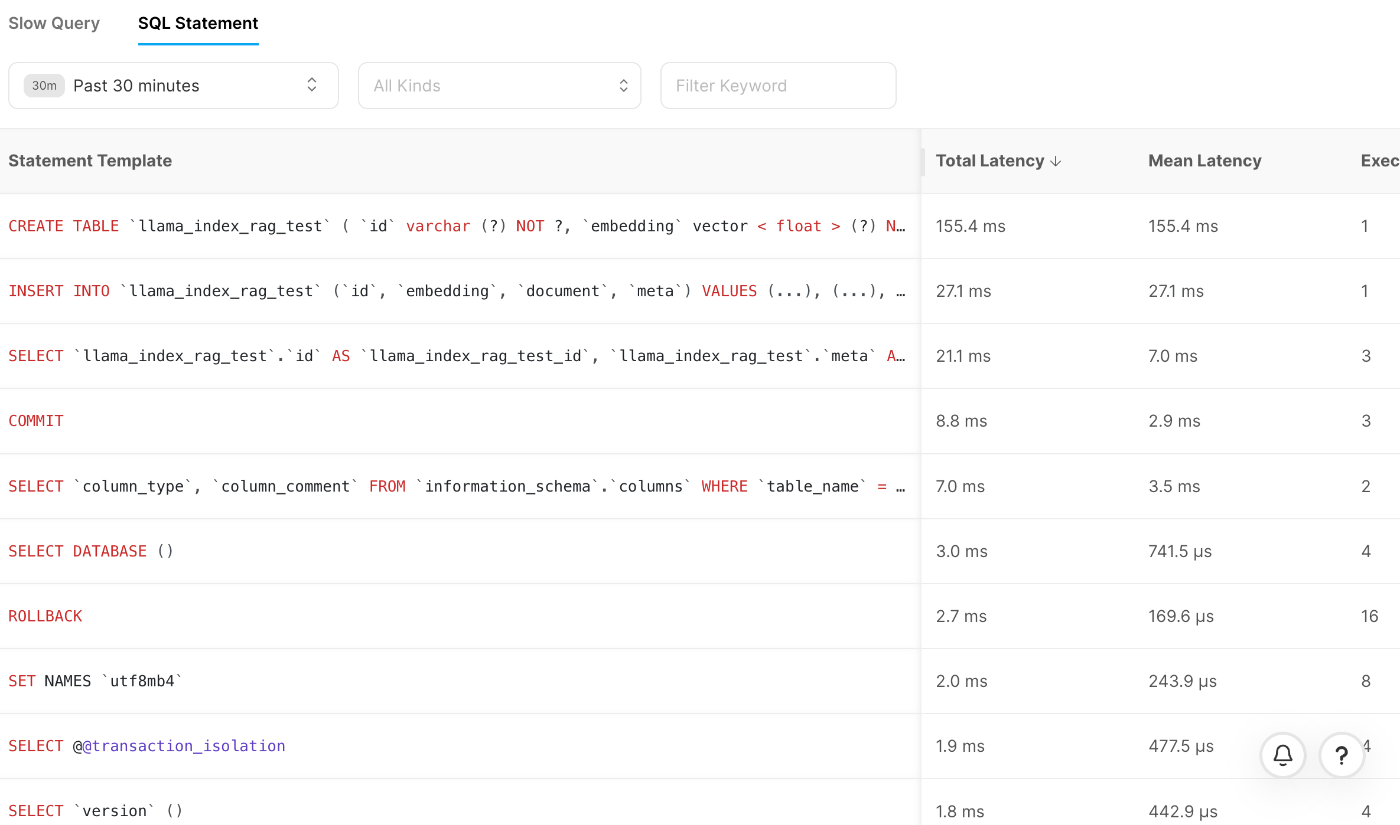
SQLステートメントの詳細を確認すれば下記のようにどのSQLステートメントがどれくらい時間がかかっていたのかなども分かります。
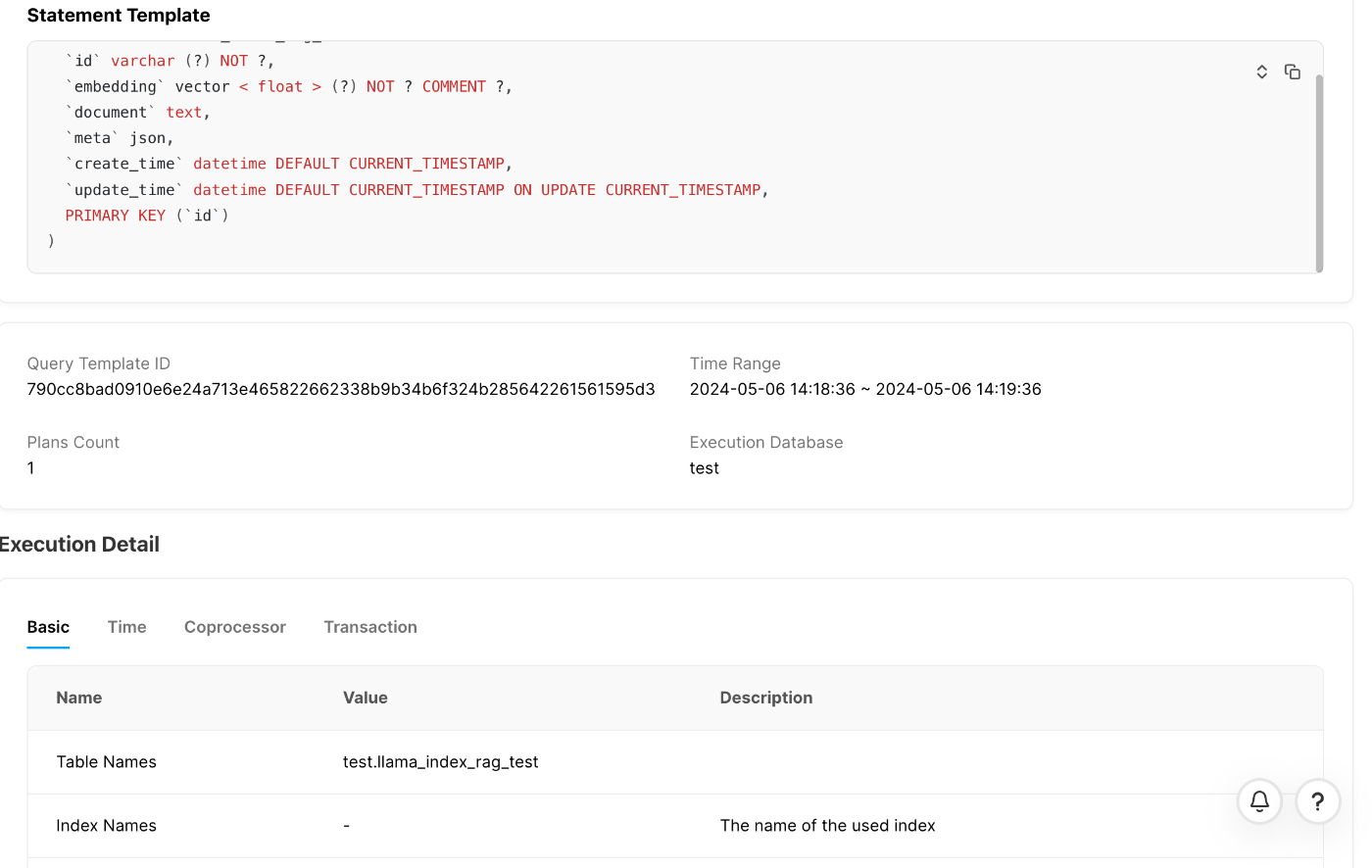
下記のように実行計画の中も見ることももちろんできます。

ちょっとした実験
例えば、今検証してきたデータに対し、下記のようなクエリを実行します。
TiDBでは、どうやら実行計画を見るとVectorカラムのデータはTiKVノードに描かれる基本のTiDBの動作と変わらないことが分かります。
> SELECT * FROM `llama_index_rag_test`;

では、このVectorカラムがあるテーブルに対して、TiFlashを追加するとVectorデータはレプリケーションされるのでしょうか?
やってみましょう。
下記のSQLを使用すると、ターゲットとするテーブルに対してTiFlashを追加することができます。
> ALTER TABLE `llama_index_rag_test` SET TIFLASH REPLICA 2;
下記のSQLを実行すると、TiFlashを追加したテーブルの状況を確認することができます。
> SELECT * FROM information_schema.tiflash_replica WHERE TABLE_SCHEMA = 'test' and TABLE_NAME in ('llama_index_rag_test');
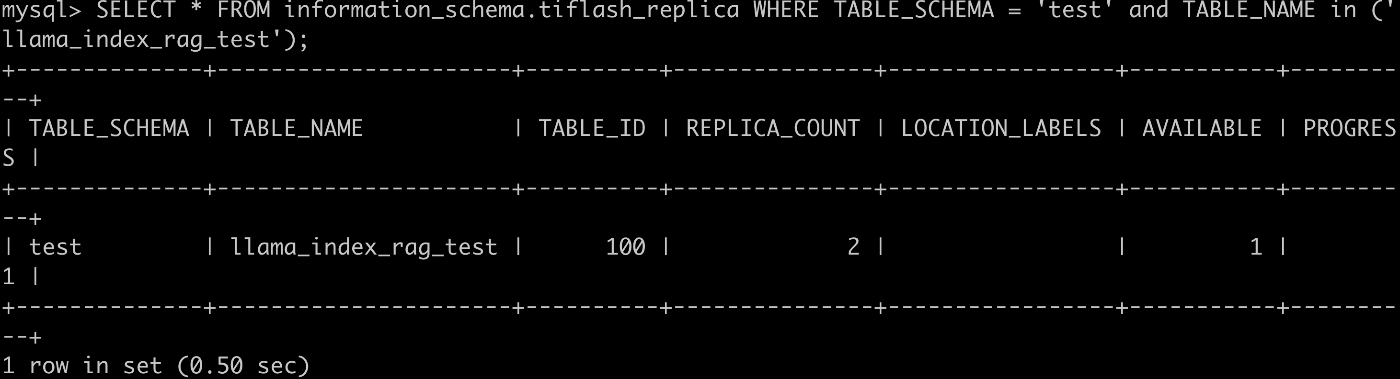
まさかのTiFlashが追加できましたね!
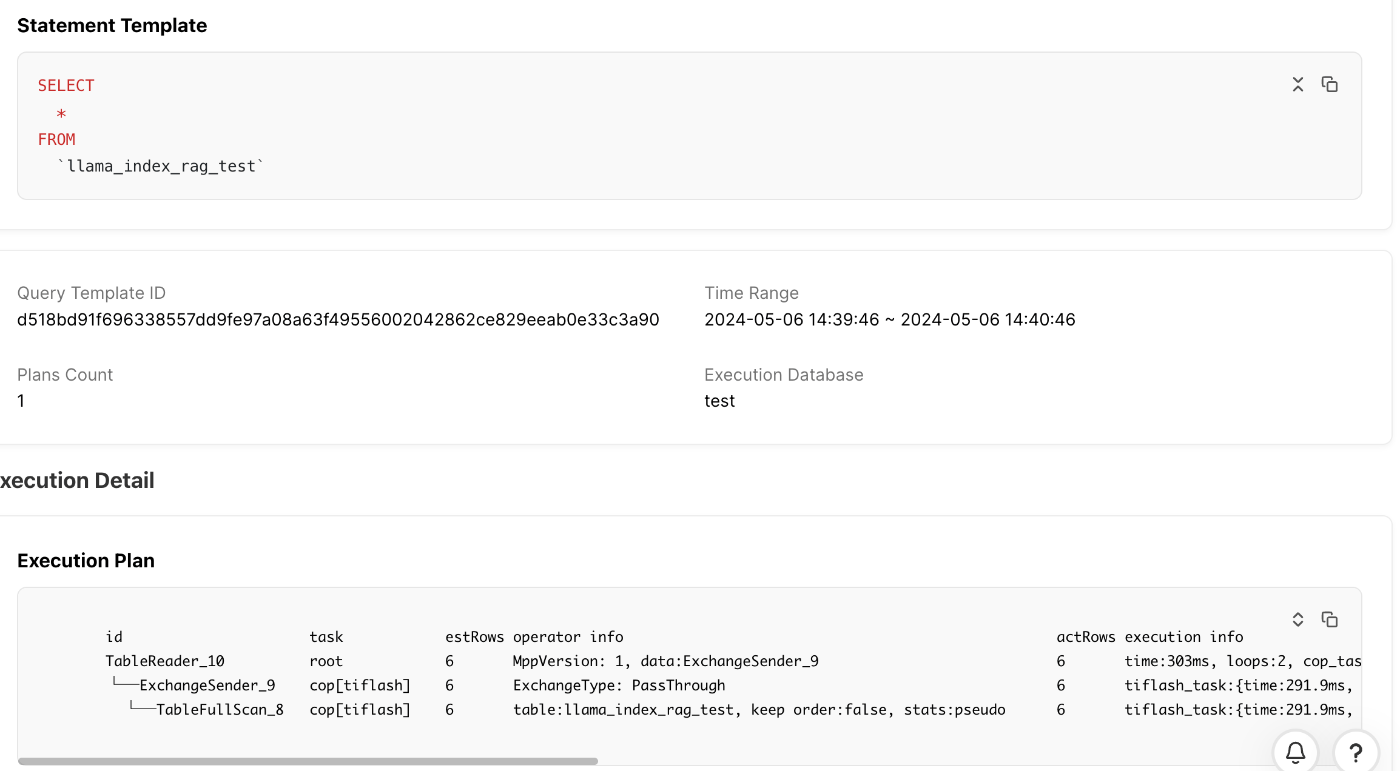
では、強制的に再度最初のSELECT分をする前に下記の設定を追加し、セッションレベルでTiFlashノードへSQLが流れるように設定しましょう。
> set SESSION tidb_isolation_read_engines = "tiflash";
さてどうなるでしょうか。
> SELECT * FROM `llama_index_rag_test`;
実行計画を見ると、データの読み先がTiKVだったものが、TiFlashになっていますね。
つまり内部的にも、TikVからTiFlashに対して、Vectorカラムを持つデータのレプリケーションができているということになります。面白いですね。
まとめ
いかがだったでしょうか?
今回発表されたベクトル検索機能について、TiDBで利用できるようになったことで、既存のビジネス、サービスに生成AIを取り入れやすくなる可能性が広がったのではないでしょうか。
ぜひ、WaitListに登録いただき試してみてください!
ありがとうございました!
資料
Discussion