Closed4
RAG from Scratchのまとめ
Q&A with RAG

1. Load Documents
# Load Documents
import bs4
from langchain_community.document_loaders import WebBaseLoader
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
# ここで指定したclassの要素のみ読み込む
class_=("post-content", "post-title", "post-header")
)
)
)
docs = loader.load()
2. Split
# Split
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
3. Embed
# Embed
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
vectorstore = Chroma.from_documents(documents=splits, embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
4. Prompt
# Prompt
from langchain import hub
prompt = hub.pull("rlm/rag-prompt")
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
質問応答タスクのアシスタントです。質問に答えるために、以下の取得したコンテキストを使用してください。答えがわからない場合は、わからないと言ってください。最大3文を使用し、回答を簡潔に保ってください。
Question: {question}
Context: {context}
Answer:
5. Chain
# LLM
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# contextとquestionはpromptで指定されているinput_variables
# retrieverの出力はDocumentのリストなので文字列としてプロンプトに渡せるようにformat_docsで展開する
# RunnablePassthrough()はchainの引数がそのまま渡される
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
rag_chain.invoke("What is Task Decomposition?")
RAGを改善するテクニック1: Multi Query
- ユーザが入力するクエリが貧弱だとほしいドキュメントにマッチしないという課題がある
- クエリを異なる手法で拡張することでマッチさせる
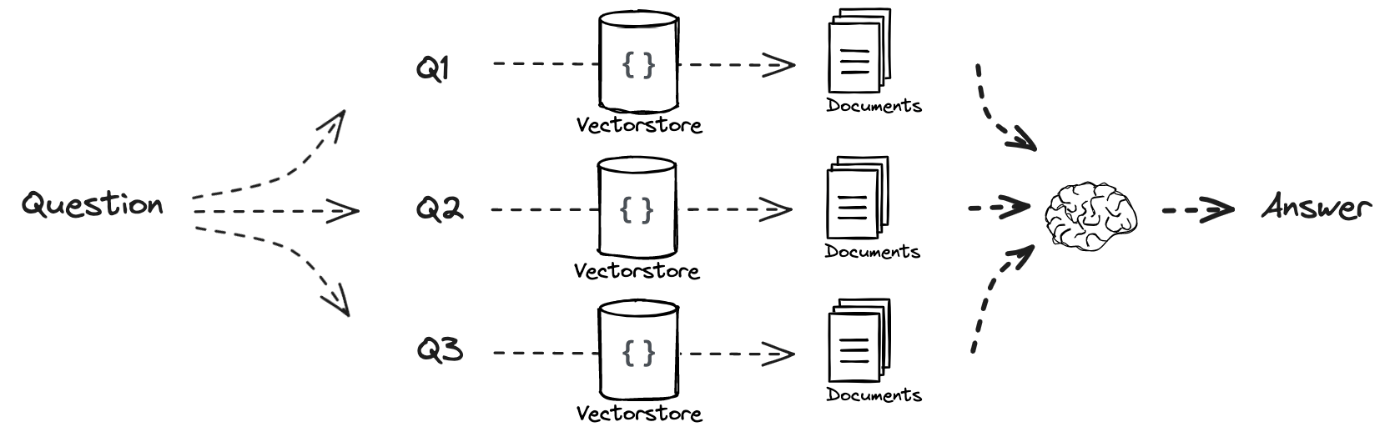
クエリ拡張に使われるプロンプト
あなたはAI言語モデルアシスタントです。与えられたユーザーの質問の異なるバージョンを5つ生成して、ベクトルデータベースから関連文書を取得することがあなたのタスクです。ユーザーの質問に対する複数の視点を生成することで、距離ベースの類似検索の制限のいくつかを克服するのがあなたの目標です。これらの代替質問を改行で区切って提供してください。
LangChainで書くと
from langchain.prompts import ChatPromptTemplate
# Multi Query: Different Perspectives
template = """You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}"""
prompt_perspectives = ChatPromptTemplate.from_template(template)
generate_queries = (
prompt_perspectives
| ChatOpenAI(temperature=0)
| StrOutputParser()
| (lambda x: x.split("\n"))
)
from langchain.load import dumps, loads
# 同じドキュメントが検索されるかもしれないので重複を除去する
def get_unique_union(documents: list[list]):
flattened_docs = [dumps(doc) for sublist in documents for doc in sublist]
unique_docs = list(set(flattened_docs))
return [loads(doc) for doc in unique_docs]
# map()によって5つの質問に対してそれぞれ4つずつ文書が検索される
retrieval_chain = generate_queries | retriever.map() | get_unique_union
from operator import itemgetter
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(temperature=0)
final_rag_chain = (
{"context": retrieval_chain,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"question": question})
RAGを改善するテクニック2: RAG Fusion
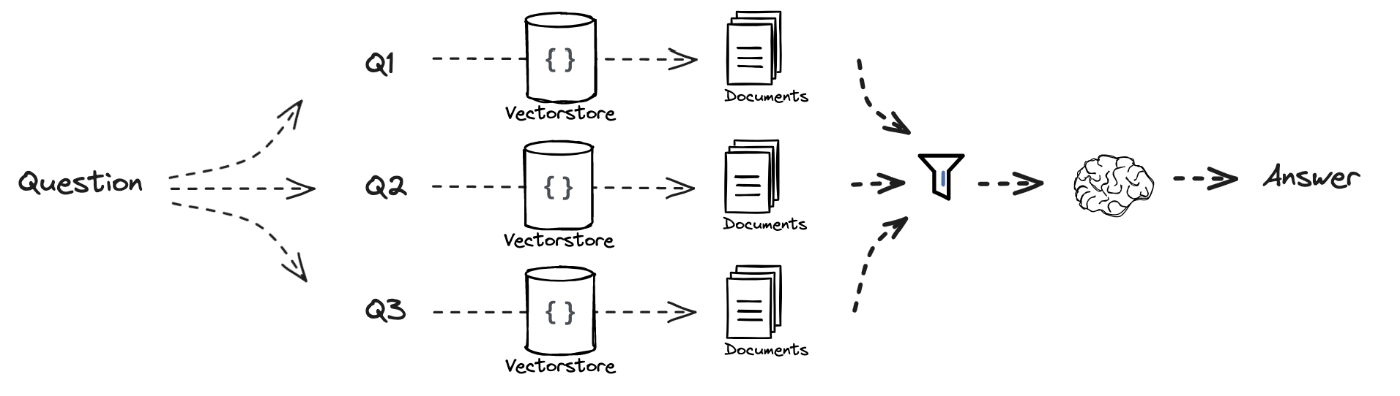
- 各クエリで検索された文書はReciprocal Rank Fusion (RRF)でつけられたスコアによってソートされる
def reciprocal_rank_fusion(results: list[list], k=60):
fused_scores = {}
# Reciprocal Rank Fusion (RRF): ランク付けされた複数の結果の検索スコアを評価して、統合された結果セットを生成するアルゴリズム
for docs in results:
for rank, doc in enumerate(docs):
doc_str = dumps(doc)
if doc_str not in fused_scores:
fused_scores[doc_str] = 0
previous_score = fused_scores[doc_str]
fused_scores[doc_str] += 1 / (rank + k)
ranked_results = [(loads(doc), score) for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)]
return ranked_results
retrieval_chain_rag_fusion = generate_queries | retriever.map() | reciprocal_rank_fusion
このスクラップは2024/02/27にクローズされました