Closed4
SpeechGPT
SpeechGPT
概要
マルチモーダルの大規模言語モデルは人工一般知能(AGI)への重要な一歩と見なされ、ChatGPTの登場により大きな関心を集めています。ただし、現在の音声言語モデルは通常、カスケードパラダイムを採用しており、異なるモード間の知識転送を阻害しています。本論文では、マルチモーダルな会話能力を持つ大規模言語モデルであるSpeechGPTを提案します。これは、複数のモードのコンテンツを認識および生成する能力を持っています。離散的な音声表現を用いて、まずSpeechInstructという大規模なクロスモーダル音声指示データセットを構築します。さらに、モード適応の事前トレーニング、クロスモーダル指示の微調整、およびモード連鎖指示の微調整を含む三段階のトレーニング戦略を採用します。実験結果は、SpeechGPTがマルチモーダルな人間の指示に従う印象的な能力を持ち、1つのモデルで複数のモードを扱う可能性を示しています。デモはこちらのURLでご覧いただけます。
リポジトリ
デモ
背景
既存のマルチモーダルモデル
- GPT-4、PaLM-E、LLaVAなどのマルチモーダルモデルは、LLMがマルチモーダル情報を理解する能力を探求している
- ほとんどの現状のLLMは、マルチモーダルコンテンツを認識できるが、マルチモーダルコンテンツを生成できない
- また画像や音声などの連続的な信号は、離散トークンを受診するLLMに直接適応できない
既存の音声言語モデル
既存の音声言語モデルは、主にカスケードパラダイムを採用。LLMが独立した音声認識モデル、音声合成モデルと連携するタイプが一般的(AudioGPT、HuggingGPT)
カスケードアプローチは3つの課題がある
- LLMの知識を音声モダリティに転送できない
- 感情や抑揚などのパラ言語情報の損失が課題
- 音声を合成するだけで、その意味情報を理解していないため、真のクロスモーダル認識と生成を達成できない
提案
本論文では、SpeechGPTという、内在的なクロスモーダル対話能力を持つ大規模言語モデルを提案します。このモデルは、マルチモーダルコンテンツを認識および生成する能力を持っています。音声とテキストのモダリティを統一するために、自己教師付きトレーニングされた音声モデルを使用して音声の離散化を行います。その後、離散音声トークンはLLMの語彙に展開され、モデルに音声を認識および生成する固有の能力を付与します。
貢献
- 最初のマルチモーダル大規模言語モデルを開発しました。これはマルチモーダルコンテンツを認識および生成する能力を持っています。
- 初めての大規模音声-テキストクロスモーダル指示遵守データセットであるSpeechInstructを作成し、公開しました。
- 強力な人間の指示遵守能力と音声対話能力を持つ最初の音声対話LLM(言語モデル)を構築しました。
- 離散的表現を通じて、他のモダリティをLLMに統合することで、大きな潜在能力を示しました。
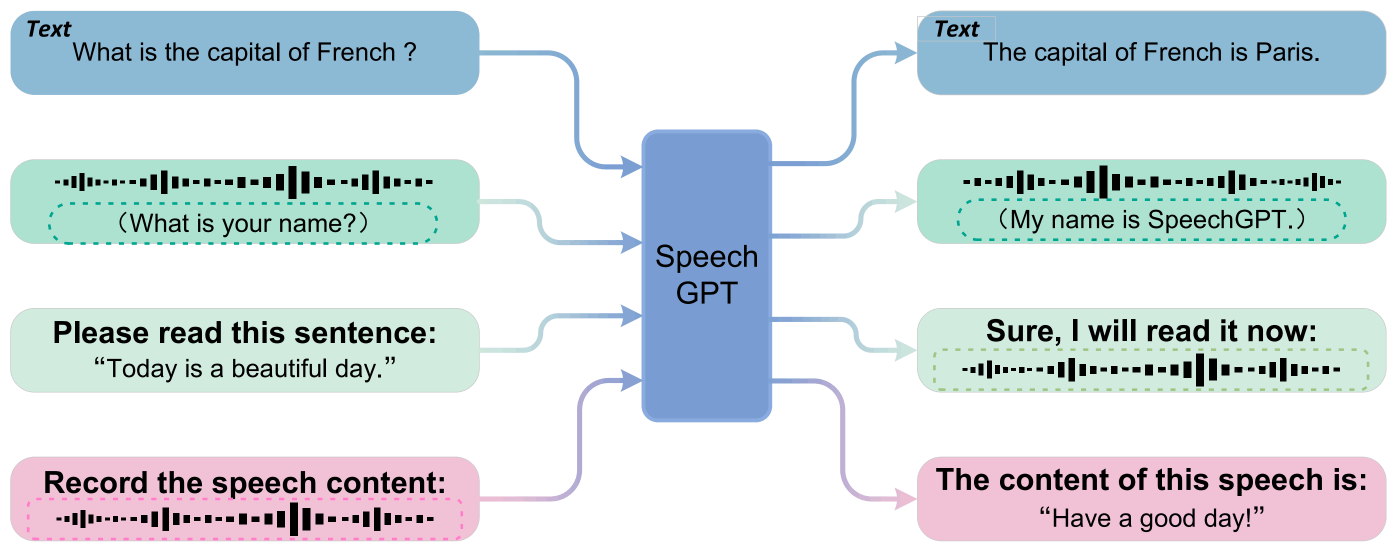
なにができる?
- テキストと音声のマルチモーダルモデル
- テキスト生成、音声認識、音声合成が1つのモデルでできる
アーキテクチャ

- Discrete unit extractor(HuBERT)連続音声を離散ユニットに変換する
- Large language model(Llama)
- Unit vocoder(HiFi-GAN)
データセット
- 音声・テキストのクロスモーダル指示に従うSpeechInstructデータセット
訓練フェーズ
- Modality Adaptation Pretraining on unpaired speech data
- ラベルなしの音声データを使ってNext Token Predictionの要領でLLMを訓練
- 音声の離散ユニットを予測できるように処理
- Cross-modal Instruction Fine-Tuning(?)
- 音声とテキストを整列させるためにペアデータを利用
- Chain-of-Modality Instruction Fine-Tuning(?)
- LoRA技術を用いてFine-tuning
このスクラップは2024/02/15にクローズされました