Closed11
GemmaのFine-tuning
HuggingFaceから使う
Gemmaのプロンプト形式に訓練データを変形していないのが気になる
Fine-tuningの例
LoRAとQLoRAのちがい
- LoRA
- 量子化はしないでFP16の基盤モデルを使う
- QLoRA
- 重みを4bit量子化したうえでLoRAを使う
- 量子化によってモデルサイズが小さくなるのでLoRAの重みをたくさんのレイヤに追加できる
- さらなる工夫として4bit NormalFloat (NF4)、二重量子化、Paged Optimizerが導入される
- どちらもFull Fine-tuningと性能は変わらない
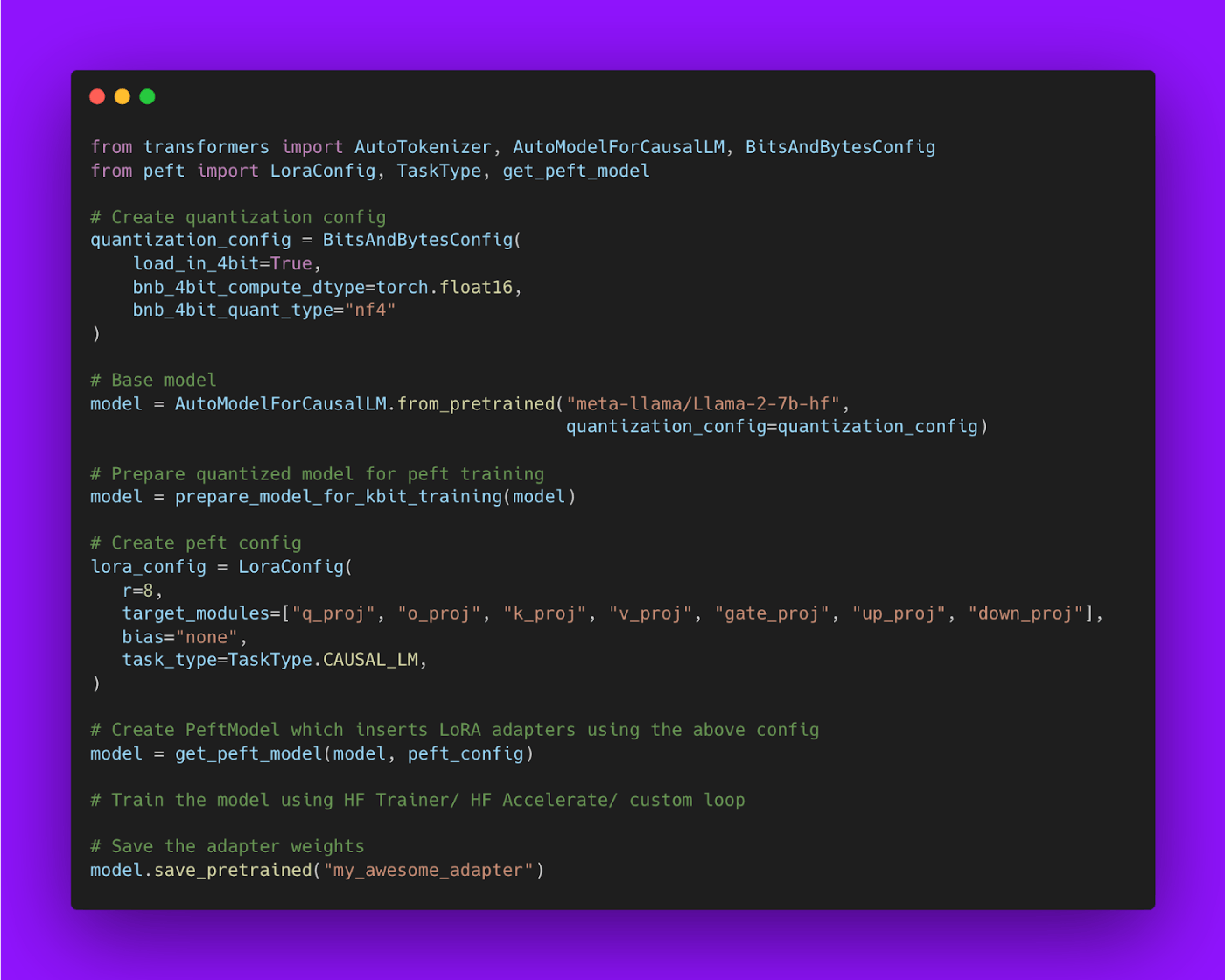
- モデルをロードするときにBitsAndBytesで4bit量子化しているのがポイント
packingとは?
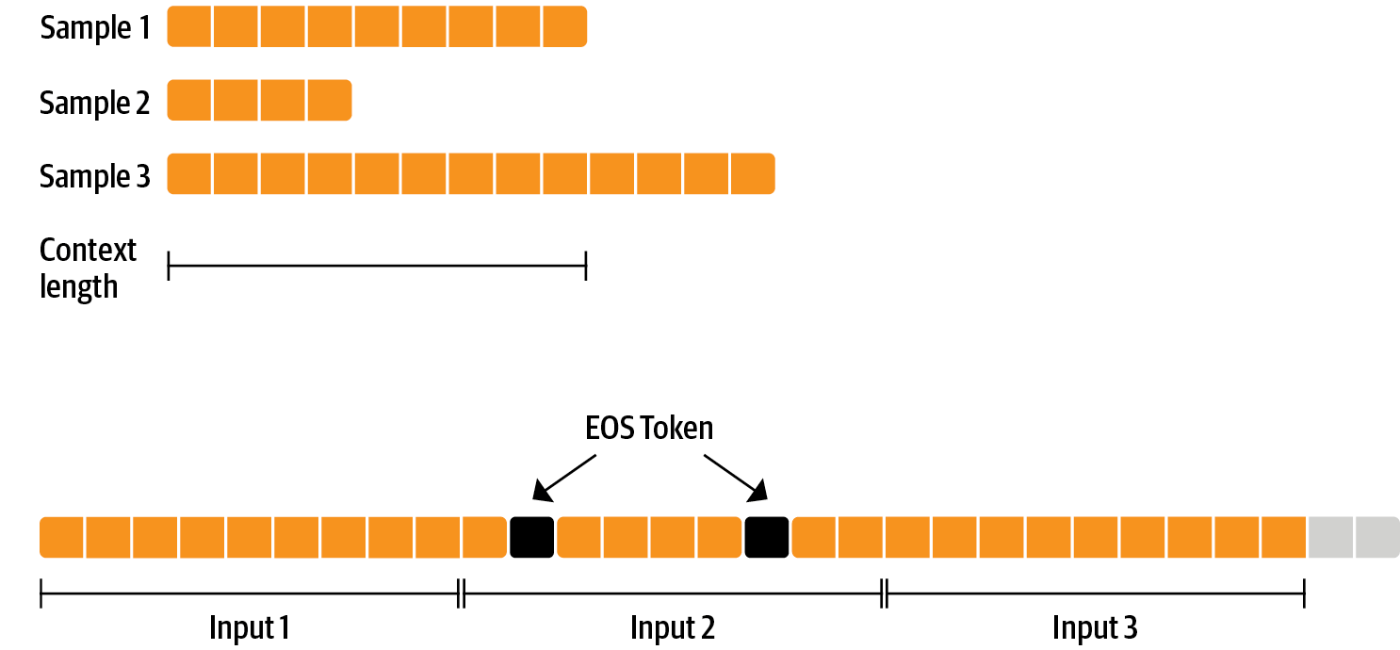
- SFTTrainerの
packing=True - 複数の文章をEOSTokenでつないでチャンクを作ることで訓練効率を向上させる手法
サンプルコード
- Llama2をUltraChatデータでFine-tuning
- GPUメモリは10GB程度に抑えられる
- UltraChatは
gemma-7b-itのSFTでも使われている
日本語でのFine-tuning例
- Gemmaのプロンプト形式に整形してからチューニングに使っている
-
examples/scripts/sft.pyを修正して使っているためSFTTrainerに合わせて書き直してみる
import torch
import transformers
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import LoraConfig
from trl import SFTTrainer
model_id = "google/gemma-1.1-7b-it"
tokenizer = AutoTokenizer.from_pretrained(
model_id,
use_fast=True
)
# TODO: examples/scripts/sft.py#110 これはなに?
tokenizer.pad_token = tokenizer.eos_token
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype="float32"
)
model_kwargs = dict(
revision="main",
trust_remote_code=False,
attn_implementation=None,
torch_dtype=None,
use_cache=True,
device_map=None,
quantization_config=quantization_config
)
peft_config = LoraConfig(
r=64,
lora_alpha=16,
lora_dropout=0.1,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj"],
task_type="CAUSAL_LM",
)
training_args = transformers.TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=1,
learning_rate=2e-4,
optim="adamw_torch",
save_steps=50,
logging_steps=50,
max_steps=500,
report_to="wandb",
output_dir="outputs",
)
trainer = SFTTrainer(
model=model_id,
model_init_kwargs=model_kwargs,
args=training_args,
train_dataset=train_dataset,
dataset_text_field="text",
max_seq_length=512,
tokenizer=tokenizer,
packing=False,
peft_config=peft_config,
)
trainer.train()
- ドイツ語から日本語への翻訳
- チューニング用のデータをGemmaのプロンプトに変換していない
- Gemmaにはシステムプロンプトに相当するものがない
- userとmodelのみ
- userの冒頭にシステムプロンプトを追加する
このスクラップは2024/04/22にクローズされました