AudioCraft
AudioCraft
ブログ
概要
AudioCraftは、音楽、サウンドエフェクト、生のオーディオ信号のトレーニング後の圧縮など、ジェネレーティブ・オーディオのあらゆるニーズに対応するワンストップのコードベースです。
以下の3つのリポジトリからなる
- AudioGen: 効果音生成
- MusicGen: 音楽生成
- EnCodec: 音声の圧縮(中間音響特徴量として使用)
プロのミュージシャンが、楽器を一音も弾かずに新しい作曲を探求できることを想像してみてほしい。あるいは、インディーズゲーム開発者が、わずかな予算でバーチャル世界にリアルなサウンドエフェクトやアンビエントノイズを加える。あるいは、中小企業の経営者は、最新のインスタグラム投稿にサウンドトラックを簡単に加えることができる。
AudioCraftは、MIDIやピアノロールとは対照的に、生のオーディオ信号でトレーニングした後、テキストベースのユーザー入力から高品質でリアルなオーディオと音楽を生成するシンプルなフレームワークです。
画像、ビデオ、テキストに対するジェネレーティブAIについては多くの興奮が見られる一方で、オーディオはいつも少し遅れているように見える。世の中にはいくつかの研究があるが、非常に複雑で、あまりオープンではないため、人々は気軽に遊ぶことができない。
AIで首尾一貫した音楽を生成するためには、MIDIやピアノロールのような記号的表現がしばしば用いられてきた。しかし、これらのアプローチでは、音楽に見られる表現上のニュアンスや様式的要素を完全に把握することはできない。
- 生の波形を対象とした技術
- 音楽は局所的、長期的、階層的なパターンであるため生成がもっとも困難
- 音響特徴量としてメルスペクトログラムも使わない
- EnCodecという技術で抽出した音響特徴量を使う
- 音声がどれほど難しいか?
- 数分の音楽 ⇒ 44.1kHzで数百万ステップ
- テキスト ⇒ 1文章あたり数千ステップ(サブワードトークン)
Audio Language Model
- EnCodecによって音楽に離散的なAudio Token(NLPの語彙に当たる)を実現する
- あとはLLMのようにEnCodec Decoderが次のAudio TokenをAutoregressiveに生成する
アーキテクチャ
MusicGenとAudioGenは、圧縮された離散音楽表現(トークン)のストリーム上で動作する単一の自己回帰言語モデル(LM)で構成される。
- AudioGenもMusicGenもアーキテクチャは同じか? ⇒ NO
- MusicGenに特徴的なところはどこか?
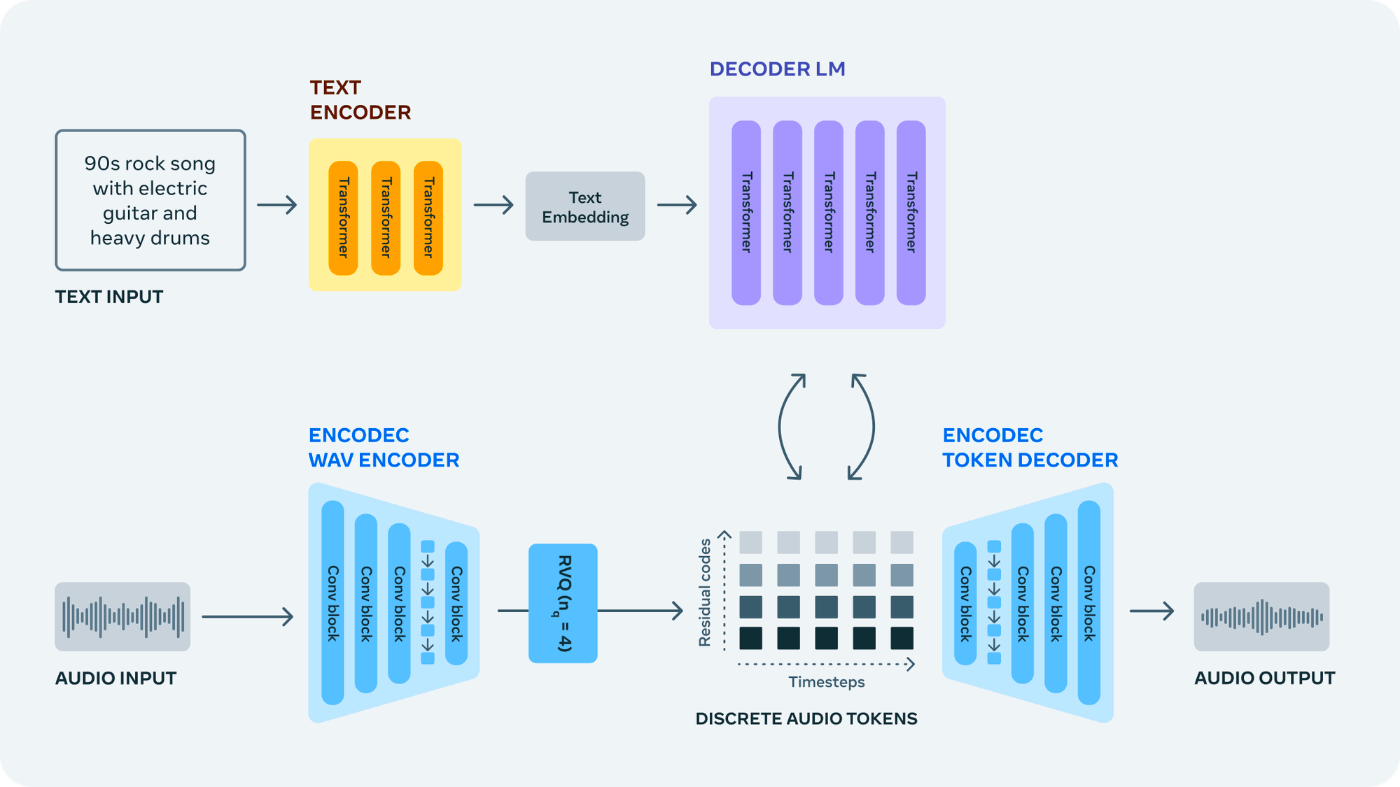
生成手順
- 我々のモデルはEnCodecニューラル・オーディオ・コーデックを活用して、生の波形から離散的なオーディオ・トークンを学習する(EnCodec Wav Encoder)
- EnCodecは音声信号を1つまたは複数の離散トークンの並列ストリームにマッピングする(Discrete Audio Tokens)
- 次に、1つの自己回帰言語モデルを使用して、EnCodecからのオーディオ・トークンを再帰的にモデル化する(Decoder LM)
- 生成されたトークンはEnCodecデコーダーに送られ、オーディオ空間にマッピングされ、出力波形が得られます(EnCodec Token Decoder)
- 最後に、テキストから音声へのアプリケーションのために事前に学習されたテキストエンコーダを使用するなど、生成の制御にさまざまな種類の条件付けモデルを使用することができる(Text Encoder)
AudioGen
サンプル音声
Text-to-Sound Generation
従来研究
一番近い従来研究はDiffSound
- Audio Codesは、メルスペクトログラム上でVQ-VAEを訓練して抽出
- Audio Codesからの波形生成にはDiffusion Modelを使用
- Transformerも試したがDiffusionに及ばず
AudioGenの特徴
- メルスペクトログラムではなく生の波形上
- 複雑なテキストから音声を生成するためのAugmentation手法
- Classifier Free Guidance (CFG)
- テキストで条件付けされた自己回帰モデルが高品質な音を生成できることを示す
アーキテクチャ
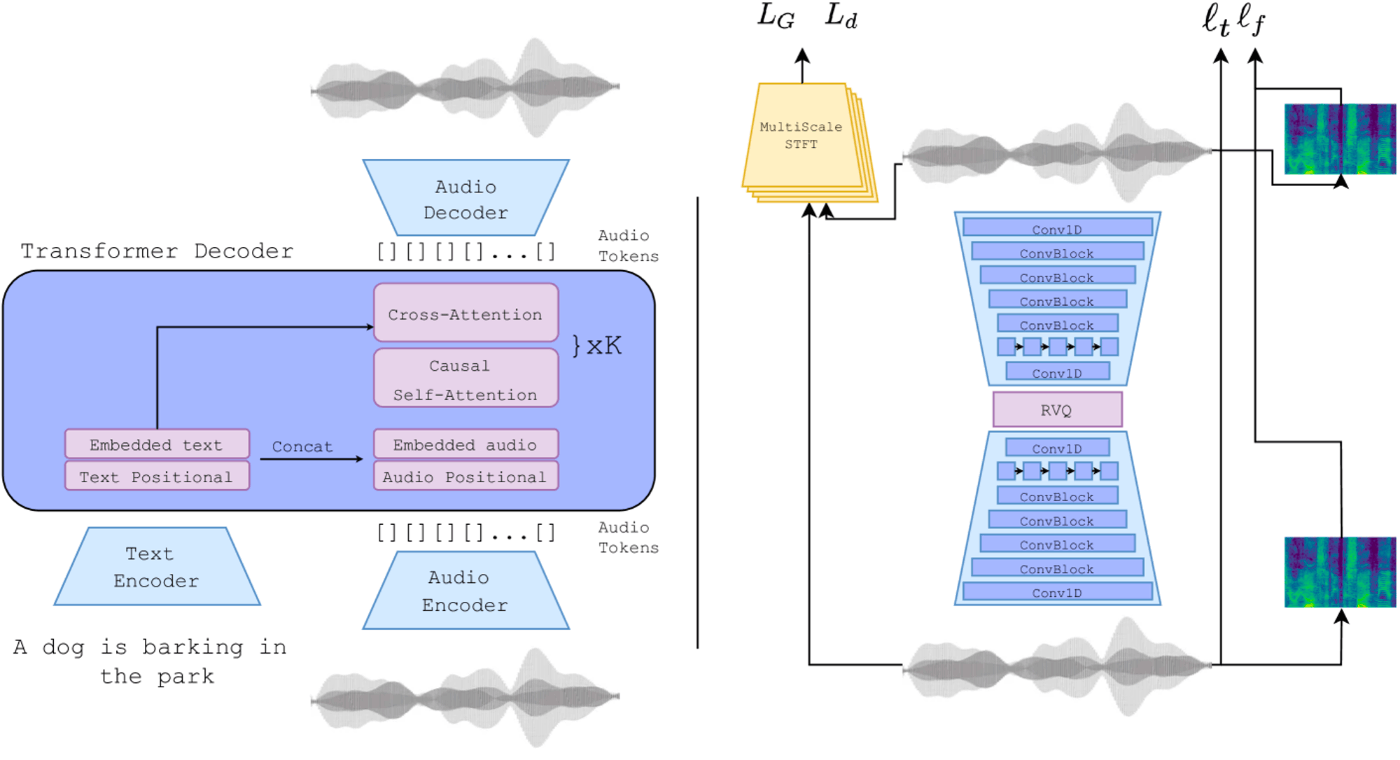
- Audio Representation: Audio EncoderとAudio Decoderはreconstructionで訓練(右図)
- 時間領域のL1Loss
- 周波数領域のL1Loss + L2Loss
- MultiScale STFT adversarial loss + feature matching loss
- Audio Language Modeling: 左の図の青がLLMと同じTransformer(Diffusionではない!)
- Audio EncoderとAudio Decoderは右のアーキテクチャで訓練したものを使う
- Text Encoderは事前訓練されたT5を使う
- 次のAudio Tokenを予測 cross entropy loss
- 自己回帰モデルなので新しいAudio Tokenを出力したら入力に入れて次のAudio Tokenを生成
- 1ステップ分のAudio Tokenを生成したらそこまでで波形に戻す?Audio Encoderが波形入力になっている
- テキストと音は系列長が異なるのでCross-Attentionを使う
データセット
波形
- AudioSet
- BBC sound effects
- AudioCaps
- Clotho v2
- VGG-Sound
- FSD50K
- Free To Use Sounds
- Sonniss Game Effects
- WeSoundEffects
- Paramount Motion - Odeon Cinematic Sound Effects
すべて16kHz
テキスト
- タグがあるデータセットはタグを連結
dog, bark, park ⇒ dog bark park - キャプションがあるデータセットは前処理して合わせる
a dog is barking at the park ⇒ dog bark park - speechタグが圧倒的に多かったためクラスバランスを取るためにspeechはすべてフィルタリング
評価
- Fréchet Audio Distance (FAD)
MusicGen
サンプル音声
Text-to-Music Generation
MusicGenは、テキスト記述とメタデータとともに、Metaが所有する、またはこの目的のために特別にライセンスされた20,000時間の音楽に相当する、およそ400,000の録音で学習されました。
楽曲のライセンスの問題はクリア
私たちは、モデルの学習に使用したデータセットに多様性が欠けていることを認識しています。特に、使用した音楽データセットには洋楽の割合が多く、テキストとメタデータが英語で書かれた音声とテキストのペアしか含まれていません。
楽曲ジャンルにバイアスがある
MusicGenは、さらに多くのコントロールが可能になれば、シンセサイザーが初めて登場したときのように、新しいタイプの楽器になると考えています。
- テキストによる条件付け
- メロディによる条件付け
- メロディラインは同じで異なる音楽が生成できる
データセット
MusicGenの学習には、20K時間のライセンス音楽データセットを使用する。
- 1万曲の高品質音楽トラックからなる社内データセット
- ShutterStockの音楽データコレクション 2万5000曲
- Pond5の音楽データコレクション 36万5000曲
いずれのデータセットも、32kHzでサンプリングされたフルレングスの音楽で構成される。メタデータはテキストの説明と、ジャンル、BPM、タグなどの追加情報。
ベースライン手法
- Riffusion
- Moussai
- MusicLM
- Noise2Music
EnCodec
EnCodecは、残差ベクトル量子化ボトルネックを持つオートエンコーダで構成され、一定の語彙を持つ音声トークンの複数の並列ストリームを生成する。異なるストリームは音声波形の異なるレベルの情報をキャプチャするため、すべてのストリームから忠実度の高い音声を再構成することができる。
- あらゆる音を圧縮するNeural Codecの一種
- 入力した音を圧縮し、元に戻すように訓練される(Autoencoder)
- 量子化されたボトルネックを持つ
- ボトルネックは複数のストリームから成る
アーキテクチャ

- 最初のvector quantization
- codebookの中から一番近いベクトルのindexに置き換える
- 引き続くvector quantization
- residual vector quantization (RVQ)
- 入力のベクトルからcodebookのベクトルを引いた残差ベクトルをに対して同様にVQする
- 入力の1フレームの128次元ベクトルが4つのindexで表される
- 入力音声をcodebookのindexに圧縮できる
- indexはdiscrete space
- reconstruction lossとadversarial lossの2つで訓練する
- 音声圧縮で使う場合は、Encoder / Decoderの重みをお互いに共有する必要がある
- 圧縮したものを復元するにはquantizeされたindexベクトルのみでOK
解説記事
解説動画
効果音・楽曲生成の関連研究
Metaとほぼ同等のモデルを提案しているがOSSではない
- AudioLM
- MusicLM
- AudioStream
その他のText-to-Audioの研究
- DiffSound
- AudioClip
- Bark
効果音・楽曲生成のWebサービス
Encodecの実験
- デフォルトはbandwidth=1.5
- [1.5, 3.0, 6.0, 12.0, 24.0] がサポートされている
- 12.0でくらいで元の音質に近い
AudioGenの実験
MuscGenの実験