AudioLM
デモ
ブログ
概要
入力で与えた音声や音楽の続きを生成できる。テキストの続きを生成する言語モデルのアナロジー。
私たちは、長期的な一貫性を持つ高品質なオーディオ生成のためのフレームワークであるAudioLMを紹介します。AudioLMは、入力オーディオを離散的なトークンのシーケンスにマッピングし、この表現空間でのオーディオ生成を言語モデリングのタスクとして扱います。既存のオーディオトークナイザーが再構築品質と長期的な構造の間で異なるトレードオフを提供する方法を示し、両方の目標を達成するためのハイブリッドなトークナイゼーションスキームを提案します。すなわち、私たちは、長期的な構造を捉えるためにオーディオで事前訓練されたマスク付き言語モデルの離散化された活性化を利用し、高品質な合成を達成するためにニューラルオーディオコーデックによって生成された離散コードを使用します。大規模な生オーディオ波形のコーパスでのトレーニングにより、AudioLMは短いプロンプトが与えられた際に、自然で矛盾のない続きを生成することを学びます。話し言葉にトレーニングされたAudioLMは、どんな書き起こしや注釈もなく、構文的および意味的に妥当な話し言葉の続きを生成し、未知の話者に対しても話者のアイデンティティと抑揚を維持します。さらに、音楽の象徴的表現なしでトレーニングされたにもかかわらず、連続的なピアノ音楽を生成することで、私たちのアプローチが話し言葉を超えて拡張されることを示します。
Unofficial PyTorch実装
- 訓練コードのみ
- 訓練済みのモデルは公開されていない
- SoundStreamの代わりにEnCodecやHuBERT?を使う実装もある
- AudioLMからVALL-Eへの派生にも言及
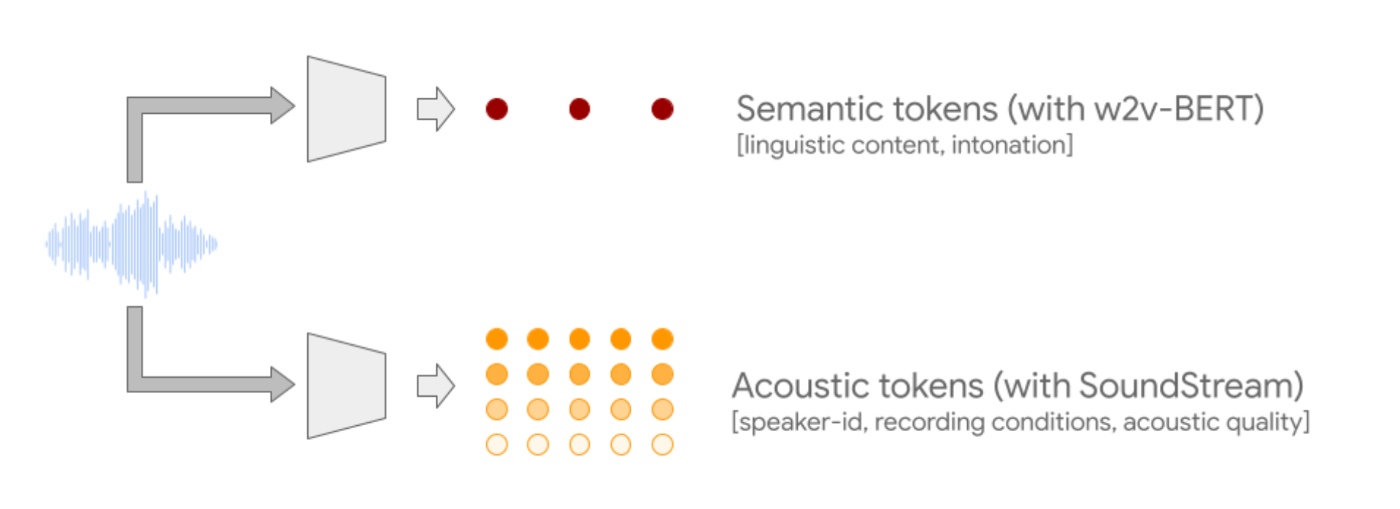
2種類のオーディオトークンを利用
-
意味的トークン(w2v-BERT):長いシーケンスのモデリングを可能にするためにオーディオ信号を大幅にダウンサンプリングします
-
音響トークン(SoundStream):音声波形の詳細(話者の特性や録音条件など)を捉える音声ストリームニューラルコーデックによって生成される
訓練方法
ステージ1

AudioLMは、音声や音楽のテキストや記号的表現なしに訓練される純粋な音声モデルです。AudioLMは、いくつかの段階ごとに1つのTransformerモデルを連鎖させることで、セマンティックトークンから細かい音響トークンまで、階層的にオーディオシーケンスをモデル化します。各段階は、過去のトークンに基づいて次のトークンの予測を行うように、テキスト言語モデルを訓練するのと同様に、訓練されます。最初の段階では、このタスクをセマンティックトークンに対して行い、オーディオシーケンスの高レベルの構造をモデル化します。
ステージ2

次の段階では、セマンティックトークンの完全なシーケンスと、過去の粗い音響トークンを結合し、両方を条件として粗い音響モデルに供給し、そのモデルは未来のトークンを予測します。このステップでは、音声における話者の特性や音楽における音色などの音響特性をモデル化します。
ステージ3

第三段階では、粗い音響モデルで処理された粗い音響トークンを、さらに詳細を加える細かい音響モデルで処理します。最後に、音響トークンをSoundStreamデコーダーに供給して、波形を再構築します。