大規模音声モデル(Large Audio Models)のサーベイ
以下のサーベイ論文を中心に内容をまとめていく
この論文は、大規模言語モデルを音声信号処理に適用する最近の進展と課題について包括的な概要を提供します。音声処理は、多様な信号表現と幅広いソースによる課題を提起しますが、トランスフォーマーベースの大規模音声モデルはこの分野で効果的であり、自動音声認識から音楽生成までのさまざまなタスクで優れた能力を示しています。特に、最近の基礎となる音声モデルは、100以上の言語に対応し、タスク固有のシステムへの依存なしにユニバーサルな翻訳者としての機能を示すようになっています。この論文では、最新の手法や性能、実世界への適用性について詳細に分析し、将来の研究方向についての洞察を提供します。また、急速な発展に対応するために、関連する最新の記事とオープンソース実装を定期的に更新する予定です。
基盤モデル(Foundation Model)は、言語、画像、ビデオの分野で顕著な進歩を遂げてきた。音声ドメインはこれらの分野に比べて発展が緩やかだった。
Q. 音声ドメインの難しさとは?
Q. 大規模データセットがなかっただけ?
Q. 重要な技術マイルストンは?
- 音声データ表現とテキストトークン埋め込みの統合技術
- 自己教師あり学習(?)
他のサーベイ論文
LLMサーベイ
[14] W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y. Hou, Y. Min, B. Zhang, J. Zhang, Z. Dong et al., “A survey of large language models,” arXiv preprint arXiv:2303.18223, 2023.
音声合成
音声 x Deep Learningサーベイ
[11] H. Purwins, B. Li, T. Virtanen, J. Schlüter, S.-Y. Chang, and T. Sainath, "Deep learning for audio signal processing," IEEE Journal of Selected Topics in Signal Processing, vol. 13, no. 2, pp. 206–219, 2019.
[54] S. Liu, A. Mallol-Ragolta, E. Parada-Cabaleiro, K. Qian, X. Jing, A. Kathan, B. Hu, and B. W. Schuller, "Audio self-supervised learning: A survey," Patterns, vol. 3, no. 12, 2022.
[25] S. Karita, N. Chen, T. Hayashi, T. Hori, H. Inaguma, Z. Jiang, M. Someki, N. E. Y. Soplin, R. Yamamoto, X. Wang et al., "A comparative study on transformer vs RNN in speech applications," in 2019 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU). IEEE, 2019, pp. 449–456.
[26] S. Latif, A. Zaidi, H. Cuayahuitl, F. Shamshad, M. Shoukat, and J. Qadir, "Transformers in speech processing: A survey," arXiv preprint arXiv:2303.11607, 2023.
音楽生成
[55] J.-P. Briot, G. Hadjeres, and F.-D. Pachet, "Deep learning techniques for music generation – a survey," arXiv preprint arXiv:1709.01620, 2017.
[56] S. Ji, J. Luo, and X. Yang, "A comprehensive survey on deep music generation: Multi-level representations, algorithms, evaluations, and future directions," arXiv preprint arXiv:2011.06801, 2020.
[57] L. Moysis, L. A. Iliadis, S. P. Sotiroudis, A. D. Boursianis, M. S. Papadopoulou, K.-I. D. Kokkinidis, C. Volos, P. Sarigiannidis, S. Nikolaidis, and S. K. Goudos, "Music deep learning: Deep learning methods for music signal processing – a review of the state-of-the-art," IEEE Access, 2023.
音声ドメインにおけるアーキテクチャの変遷
初期
- 畳み込みニューラルネットワーク(CNNs)
- リカレントニューラルネットワーク(RNNs)とLSTM
- CNNsとRNNsの強みの組み合わせ
以下の2つの課題があった
- LSTMでは効率的な並列計算ができない
- 音声は非常に長い系列データであり、長期的な文脈のモデリングが難しい
Transformerの導入
- Self Attentionによる長期的な文脈の把握と高い並列性により課題が解決
- Wav2Vec、Whisper、FastPitch、MusicBERTなど多様なアーキテクチャが誕生
音声分野にTransformerが導入できたことで以下のメリットが
- LLMとの連携が可能に
- シーケンス内の文脈的な依存関係を効率的に捉えることが可能に
- 数十億パラメータを持つ大規模モデルが実現
- 音声合成のTacotron2はLSTMベース
- 音声合成のFastSpeechはTransformerベース
- 音声認識のConformerはTransformerベース
大規模言語モデル(LLM)の概要
スケーリング法則によりパラメータ数が大規模になるほど優れたパフォーマンスを発揮する。たとえば、GPT-3はGPT-2では難しかったコンテキスト内学習の能力を獲得
- BERT(3300万パラメータ)
- GPT-2(15億パラメータ)
- GPT-3(1750億パラメータ)
- PaLM(5400億パラメータ)
GPT-4
- 画像とテキストを入力とし、テキストを出力する大規模なマルチモーダルモデル
- 人間レベルのパフォーマンスを達成
- AGIへの重要な第一歩とみなされている
画像・音声・テキストを含むマルチモーダル大規模言語モデルの開発へ
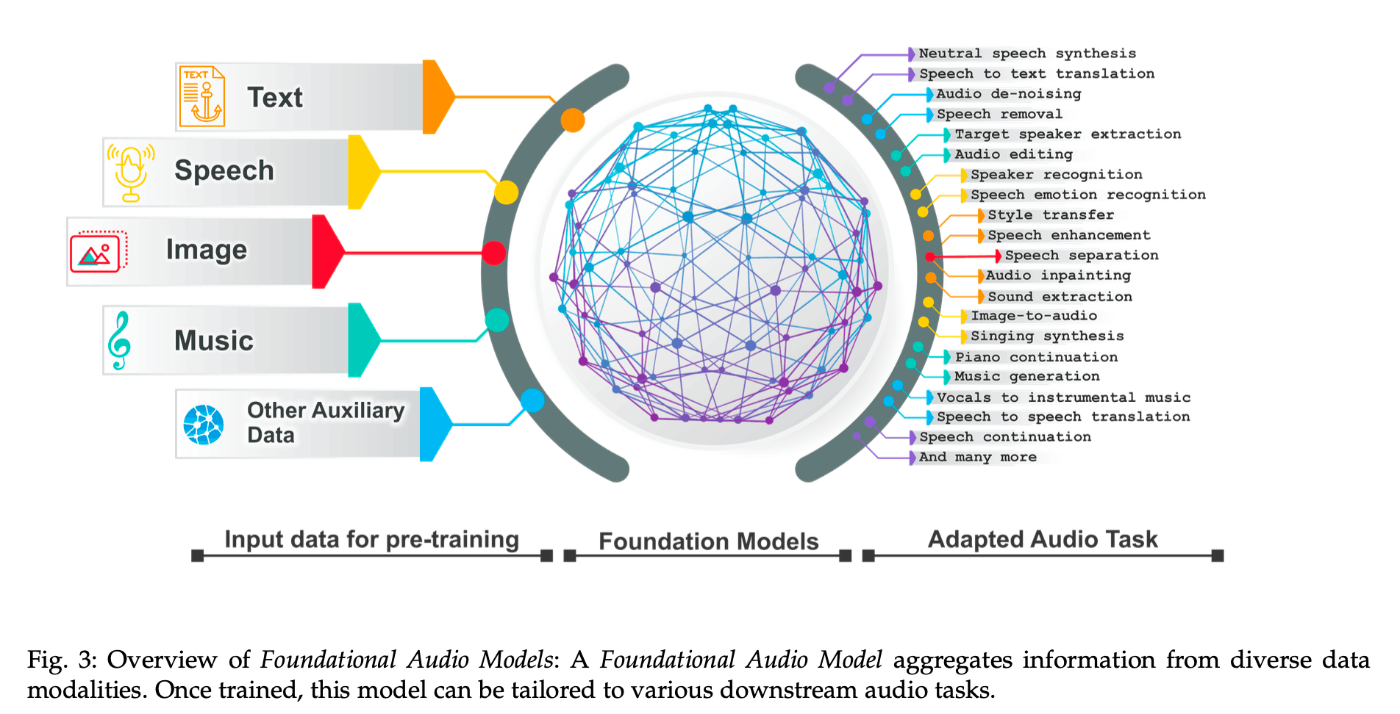
主な大規模音声モデル
- 登場年は正確か?
- 重要なモデルは抜けていないか?
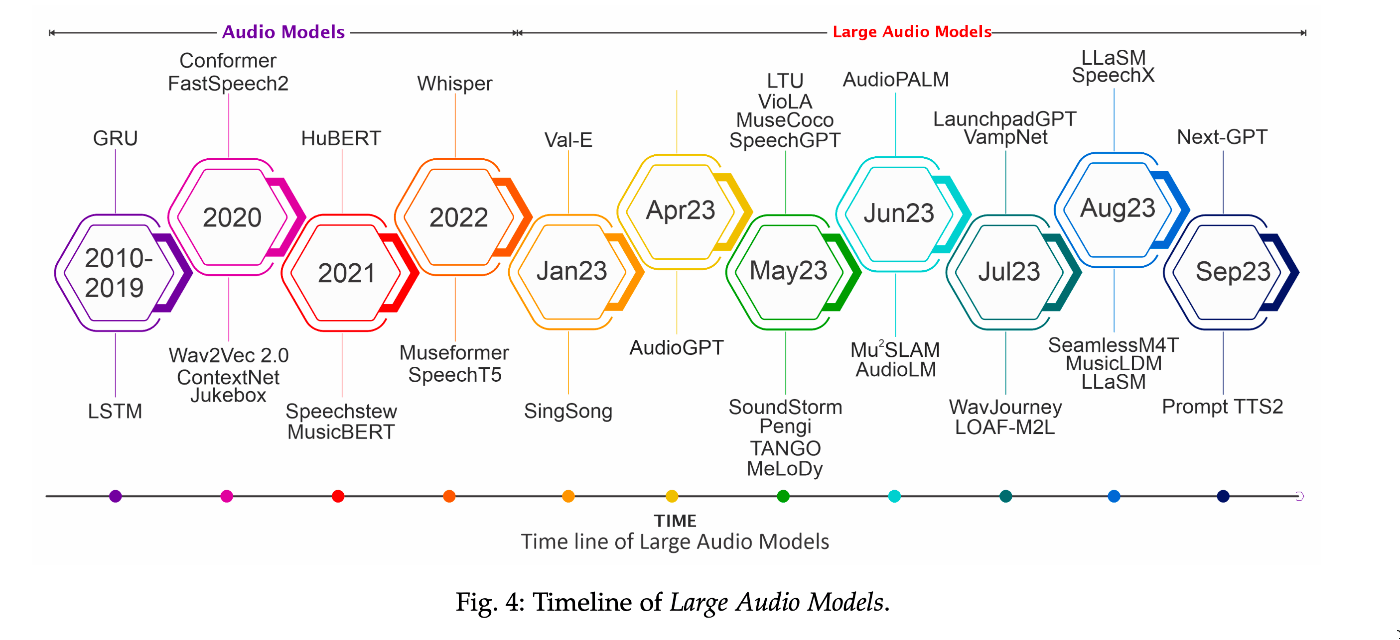
大規模音声モデルの例
- SpeechGPT
- AudioPaLM
- AudioGen
- AudioLDM / AudioLDM2
- LTU
- VioLA
- MusicGen
- MusicLM
- WavJourney
- SeamlessM4T