VALL-Eを理解する
概要
テキストから音声合成(TTS)への言語モデリングアプローチを紹介します。具体的には、市販のニューラルオーディオコーデックモデルから派生した離散コードを使用してニューラルコーデック言語モデル(VALL-Eと呼ばれる)を訓練し、以前の研究での連続信号回帰とは異なり、TTSを条件付き言語モデリングタスクとみなします。プレトレーニング段階では、TTS訓練データを60K時間の英語音声に拡大し、これは既存のシステムよりも何百倍も大きいです。VALL-Eはコンテキスト内学習能力を発揮し、見たことのない話者のわずか3秒の登録録音だけで、高品質なパーソナライズされた音声を合成することができます。実験結果は、VALL-Eが音声の自然さと話者の類似性の点で、最先端のゼロショットTTSシステムを大幅に上回ることを示しています。さらに、VALL-Eは合成において、アコースティックプロンプトの話者の感情と音響環境を保持できることがわかりました。私たちの研究のデモは https://aka.ms/valle でご覧いただけます。
実装
上記のリポジトリの訓練コードを参考にマルチリンガルのVALL-E Xに拡張
アーキテクチャ

以前のパイプライン(例えば、音素→メルスペクトログラム→波形)とは異なり、VALL-Eのパイプラインは音素→離散コード→波形です。VALL-Eは、目標とする内容と話者の声に対応する音素と音響コードのプロンプトに基づいて、離散オーディオコーデックコードを生成します。
- 中間特徴量としてメルスペクトログラムを使わない
- 離散コードから音声波形を生成する Audio Codec Decoder を使う
VALL-Eは、大規模で多様でマルチスピーカーの音声データを活用する、最初の言語モデルベースのTTSフレームワークです。
- 訓練済みの言語モデル(Llama2など)は使わない?アーキテクチャが言語モデルと一緒というだけでスクラッチから訓練するのか?
我々の作業はカスケードTTS(E2Eではなく音響モデルとボコーダーを組み合わせるタイプのTTS)の流れを踏襲していますが、中間表現としてオーディオコーデックコードを初めて使用します。これは、ファインチューニング、事前設計された特徴、または複雑な話者エンコーダーを必要とせずに、GPT-3と同様の強力なコンテキスト内学習能力を持つ最初のものです。
ゼロショットTTSは、未確認の話者に対して高品質の音声を合成するモデルを要求します。この研究では、ゼロショットTTSを条件付きコーデック言語モデリングタスクとみなします
条件:
- テキスト => 音素シーケンス 𝐱
- 話者性 => 音響プロンプト行列 C
推論中に、音素シーケンスと未確認の話者の3秒の登録録音が与えられた場合、まず訓練された言語モデルによって対応するコンテンツと話者の声を持つ音響コード行列が推定されます。その後、ニューラルコーデックデコーダーが高品質の音声を合成します。
Encodec
Audio Codec EncoderとAudio Codec Decoderは、訓練済みのEncodecを使うため訓練の対象外
ARとNARによる階層学習
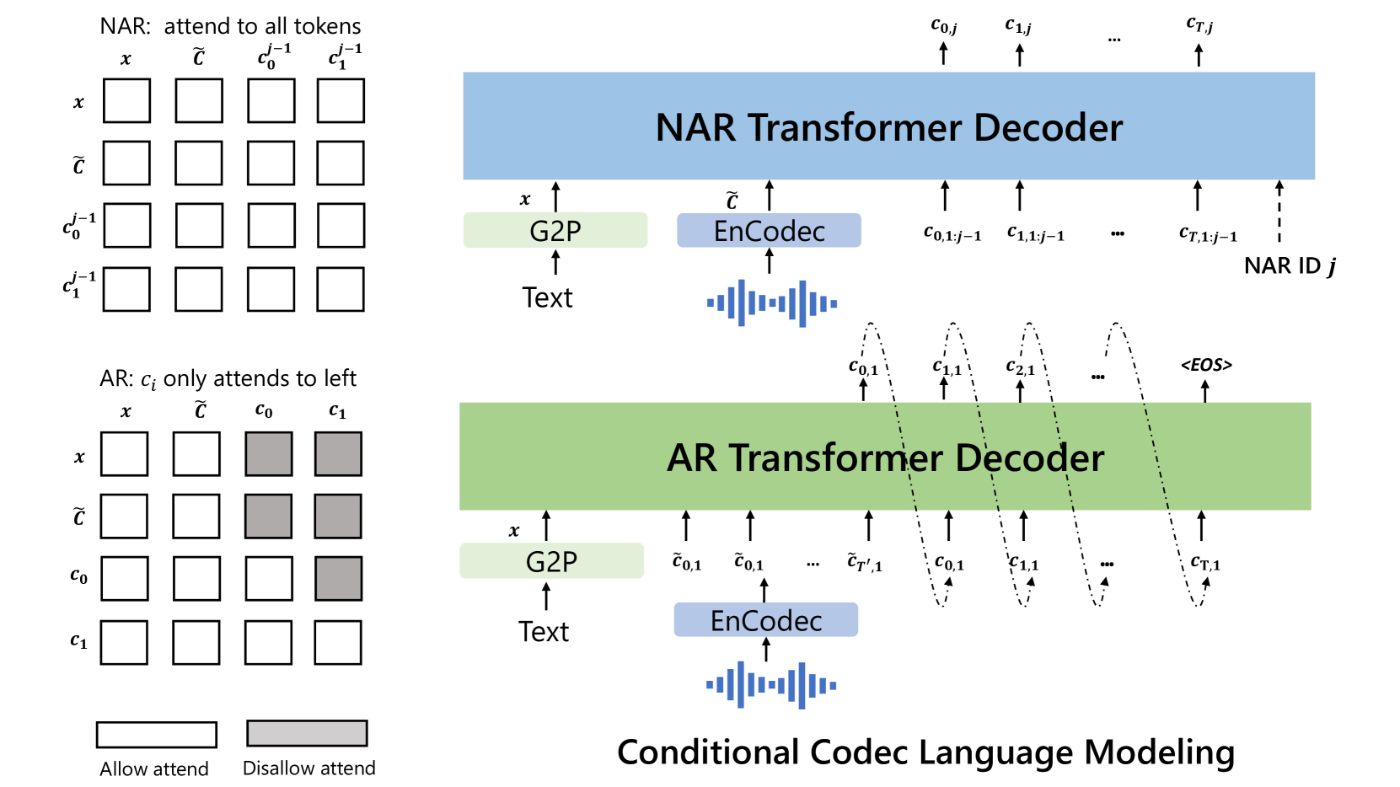
- Auto RegressiveとNon-auto Regressiveの2階層で処理する
ARモデルとNARモデルの組み合わせは、音声品質と推論速度の間で良いトレードオフを提供します。
コンテキスト内学習について
テキストベースの言語モデルの驚くべき能力であるコンテキスト内学習は、追加のパラメータ更新なしに未確認の入力に対するラベルを予測できる能力です。TTSにおいて、モデルがファインチューニングなしで未確認の話者に対して高品質の音声を合成できる場合、そのモデルはコンテキスト内学習能力を持っていると考えられます。しかし、既存のTTSシステムのコンテキスト内学習能力は強くないため、追加のファインチューニングを要求するか、未確認の話者に対して大幅に性能が低下します。
訓練データ
VALL-Eは、LibriLight(Kahn et al., 2020)を用いて訓練されます。これは、7000人以上のユニークな話者を含む60K時間の英語音声で構成されるコーパスです
LibriTTS(Zen et al., 2019)など、以前のTTS訓練データセットと比較して、私たちのデータにはより多くのノイズが含まれた音声と不正確なトランスクリプションが含まれていますが、多様な話者とプロソディを提供します。
音声量子化(Speech Quantization)
従来手法
- μ-law変換: WaveNetで使われる方式。各タイムステップの波形を256値に量子化。シーケンス長は削減されないので遅い
- vq-wav2vecやHuBERT: 自己教師あり学習で使われる。話者のアイデンティティが破棄され、再構築品質が低いという問題がある
- AudioLM: 自己教師ありモデルからのk-meansトークンとニューラルコーデックモデルからの音響トークンの両方に基づいて、音声から音声への言語モデルを訓練し、高品質の音声から音声への生成を実現している
この論文では、AudioLM(Borsos et al., 2022)に倣い、ニューラルコーデックモデルを活用して音声を離散トークンで表現します。
Audio Codecによる離散化のメリット
1)豊富な話者情報と音響情報を含み、HuBERTコードと比較して再構築時に話者のアイデンティティを維持できます。
2)離散トークンを波形に変換する既存のコーデックデコーダーがあり、スペクトラム上で操作されたVQベースの方法のようにボコーダーの訓練に追加の努力を必要としません。
3)効率のためにタイムステップの長さを減らすことができ、μ-law変換での問題に対処できます。
Encodecを採用
埋め込みは残差ベクトル量子化(RVQ)によってモデル化され、図2に示すように、1024エントリを持つ8階層の量子化器を選択します。この設定は24kHzのオーディオ再構築のための6KビットレートのEnCodecに相当します。
実験
データ
データセット:訓練データとしてLibriLightを使用します。これには、英語のオーディオブックからの60K時間のラベルなし音声が含まれています。LibriLightにおける異なる話者の数は約7000です。Kaldiレシピに従い、960時間のラベル付きLibriSpeech上でハイブリッドDNN-HMM ASRモデルを訓練します。ハイブリッドモデルが訓練されると、ラベルなし音声データはデコードされ、フレームシフトが30msである最良の音素レベルのアライメントパスに変換されます。EnCodecモデルは、60K時間のデータの音響コード行列を生成するために使用されます。
モデル
ARモデルとNARモデルは、12層、16のアテンションヘッド、埋め込み次元が1024、フィードフォワード層の次元が4096、ドロップアウトが0.1の同じトランスフォーマーアーキテクチャを持っています。LibriLightの波形の平均長さは60秒です。訓練中、波形をランダムに10秒から20秒のランダムな長さにランダムに切り取ります。その対応する音素アライメントは、音素プロンプトとして使用されます。フォースアラインメントされた音素シーケンスの連続する繰り返しを除去します。NAR音響プロンプトトークンについては、同じ発話から3秒のランダムセグメント波形を選択します。
訓練
モデルは、16台のNVIDIA TESLA V100 32GB GPUを使用して訓練され、GPUごとに6kの音響トークンでのバッチサイズで800kステップにわたって訓練されます。モデルの最適化にはAdamWオプティマイザーを使用し、最初の32kの更新で学習率をピークの5×10^−4までウォームアップし、その後リニアに減衰させます。
1枚のGPUでは訓練は不可能か?
Phoneme Conversion
- TextTokenizerとして使う
- 平文の英語のテキストを音素列に変換するライブラリ
- espeakというバックエンドが必要
セットアップ
Mac
brew install espeak
export PHONEMIZER_ESPEAK_LIBRARY=/opt/homebrew/lib/libespeak.dylib
espeak "Hello, world!"
echo Hello, world | phonemize -l en-us
Phonemizer
from phonemizer.backend import EspeakBackend
phonemizer = EspeakBackend(
"en-us",
punctuation_marks=';:,.!?¡¿—…"«»“”',
preserve_punctuation=True,
with_stress=False,
tie=False,
language_switch="keep-flags",
words_mismatch="ignore"
)
phonemized = phonemizer.phonemize(["Hello, world!", "This is a test."])
phonemized
['həloʊ, wɜːld! ', 'ðɪs ɪz ɐ tɛst. ']
from phonemizer.separator import Separator
separator = Separator(word="_", syllable="-", phone="|")
phonemized = phonemizer.phonemize(["Hello, world!", "This is a test."], separator=separator, strip=True, njobs=1)
phonemize
['h|ə|l|oʊ,_w|ɜː|l|d!', 'ð|ɪ|s_ɪ|z_ɐ_t|ɛ|s|t.']
Audio Codec Encoder
- 音声のトークン化
- Encodecを使う
-
bandwidth=6.0だとDecodeしても元の音質にはならない(劣化が明らかにわかるレベル)
from encodec import EncodecModel
import torchaudio
model = EncodecModel.encodec_model_24khz()
model.set_target_bandwidth(6.0)
import torch
wav, sr = torchaudio.load("../data/LibriTTS/train-clean-100/103/1241/103_1241_000000_000001.wav")
wav = wav.unsqueeze(0)
# encode
with torch.no_grad():
encoded_frames = model.encode(wav)
encoded_frames[0][0].shape
torch.Size([1, 8, 126])
WSL2 (Ubuntu) へのインストール
icefallという音声ライブラリに基づいているため事前準備がけっこうやっかい
以下にある説明にしたがって k2 lhotse icefall をインストール
# torch
pip install torch torchvision torchaudio
# k2
pip install https://huggingface.co/csukuangfj/k2/resolve/main/ubuntu-cuda/k2-1.24.4.dev20240223+cuda12.1.torch2.2.1-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl
# lhotse
pip install git+https://github.com/lhotse-speech/lhotse
# icefall
cd /tmp
git clone https://github.com/k2-fsa/icefall
cd icefall
pip install -r requirements.txt
export PYTHONPATH=/tmp/icefall:$PYTHONPATH
LJSpeechでの追試
VALL-Eモデルハイパラ
model = VALLE(
params.decoder_dim, # 1024
params.nhead, # 16
params.num_decoder_layers, # 12
norm_first=params.norm_first, # True
add_prenet=params.add_prenet, # False
prefix_mode=params.prefix_mode, # 1
share_embedding=params.share_embedding, # True
nar_scale_factor=params.scale_factor, # 1.0
prepend_bos=params.prepend_bos, # False
num_quantizers=params.num_quantizers, # 8
)
Number of model parameters: 367386628 (0.36B)
階層性の実装方法
- arはcodecの0次元目のみ、narはcodecの残りの次元を使う
- ar_decoderとnar_decoderという2つのモジュールがあり、ステージによって独立に学習する
- text_embeddingやpre_netなどもar用とnar用の2種類が別々にある
ar_decoder
TransformerEncoder(
(layers): ModuleList(
(0-11): 12 x TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=1024, out_features=1024, bias=True)
)
(linear1): Linear(in_features=1024, out_features=4096, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=4096, out_features=1024, bias=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(norm1): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
nar_decoder
TransformerEncoder(
(layers): ModuleList(
(0-11): 12 x TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): NonDynamicallyQuantizableLinear(in_features=1024, out_features=1024, bias=True)
)
(linear1): Linear(in_features=1024, out_features=4096, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(linear2): Linear(in_features=4096, out_features=1024, bias=True)
(dropout1): Dropout(p=0.1, inplace=False)
(dropout2): Dropout(p=0.1, inplace=False)
(norm1): AdaptiveLayerNorm(
(project_layer): Linear(in_features=1024, out_features=2048, bias=True)
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
(norm2): AdaptiveLayerNorm(
(project_layer): Linear(in_features=1024, out_features=2048, bias=True)
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
)
(norm): AdaptiveLayerNorm(
(project_layer): Linear(in_features=1024, out_features=2048, bias=True)
(norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
Cross-Entropy Lossで学習
- 推論されるAudio Codecは離散値(ラベル)のため分類のためのCross-Entropy Lossで訓練できる(言語モデルと同じ)
- Encodecでは0-1024の1025個の離散値が使われるためlogitは1025次元ベクトルになる