バレントロピー (varentropy) について
バレントロピー (varentropy) について
はじめに
最近話題になったEntropixですが、バレントロピーに馴染みがないので例の4象限がいまいちピンと来ませんでした。ということでバレントロピーの性質について調べてみたいと思います。
Entropix
Entropixについてはいろいろ記事が出ていますが、EntropixplainedはLLMの基本から書かれていて良いと思います。
まずはエントロピー (entropy) について復習
確率変数
例としてA国の大統領選に2人の候補T氏とH氏がいて、それぞれ当選確率が50%だとします。この場合どちらの候補の勝利の自己エントロピーも
そして、エントロピーは自己エントロピーを各事象の生起確率で加重平均したもの
先ほどの例で計算すると、A国の大統領選のエントロピーは
さて、先ほどからシレっと2を底とした対数
バレントロピー
バレントロピーは自己エントロピーの分散であり、
バレントロピーは分散なので非負となりますが、自己エントロピーが100%エントロピーと等しくなる場合は
それでは
from typing import Optional, Callable
import numpy as np
from numpy.typing import NDArray
from scipy.optimize import minimize
from einops import rearrange, repeat, pack
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
def init_p(n: int, k: Optional[int]=None, perturbation: float=0) -> NDArray[np.float64]:
if k is None:
p = np.ones(n)
if perturbation > 0:
p += np.exp(np.random.normal(0, perturbation, n))
p /= p.sum()
return p
else:
p = np.zeros(n)
p[k] = 1
return p
eps = 1e-10
def binary_entropy(p: NDArray[np.float64]) -> float:
positive_mask = p > 0
pp = p[positive_mask]
return -(pp*np.log2(pp + eps)).sum()
def binary_varentropy(p: NDArray[np.float64]) -> float:
positive_mask = p > 0
pp = p[positive_mask]
return (pp*(-np.log2(pp + eps) - binary_entropy(pp))**2).sum()
n = 10
p0 = init_p(n, perturbation=1)
def loss_fn(p: NDArray[np.float64]) -> float|NDArray[np.float64]:
return -binary_varentropy(p)
result = minimize(loss_fn, bounds=[(0, 1)]*n, constraints=({"type": "eq", "fun": lambda x: x.sum() - 1}), x0=p0, tol=1e-10)
print(result.x)
# [0.02378818 0.02378821 0.78590655 0.02378819 0.02378819
# 0.02378826 0.02378793 0.0237882 0.02378814 0.02378815]
(追記: einops.repeatとeinops.packを使って書換えたらとてもシンプルになりました。すみません、einopsニワカなもので)
step = 0.01
p_0 = np.arange(1/n, 1 + step, step)
p_r = (1 - p_0) / (n - 1)
num_cases = p_0.shape[0]
# p_mat = rearrange(
# [p_0] + [
# x for x
# in rearrange(p_r, 'c -> 1 c')*np.ones((n-1, num_cases))
# ],
# "n c -> c n"
# )
p_mat, _ = pack([p_0, repeat(p_r, "c -> c r", r=n-1)], "c *")
vs = np.array([binary_varentropy(p) for p in p_mat])
fig = plt.figure()
ax = fig.add_subplot(111)
sns.lineplot(x=p_0, y=vs, ax=ax)
ax.set_xlabel("p_0")
ax.set_ylabel("Varentropy")

Entropixの4つの象限は典型的にはそれそれどういう場合なのか?
これまでに得られた知見を踏まえて、Entropixの4象限の図を眺めてみましょう。
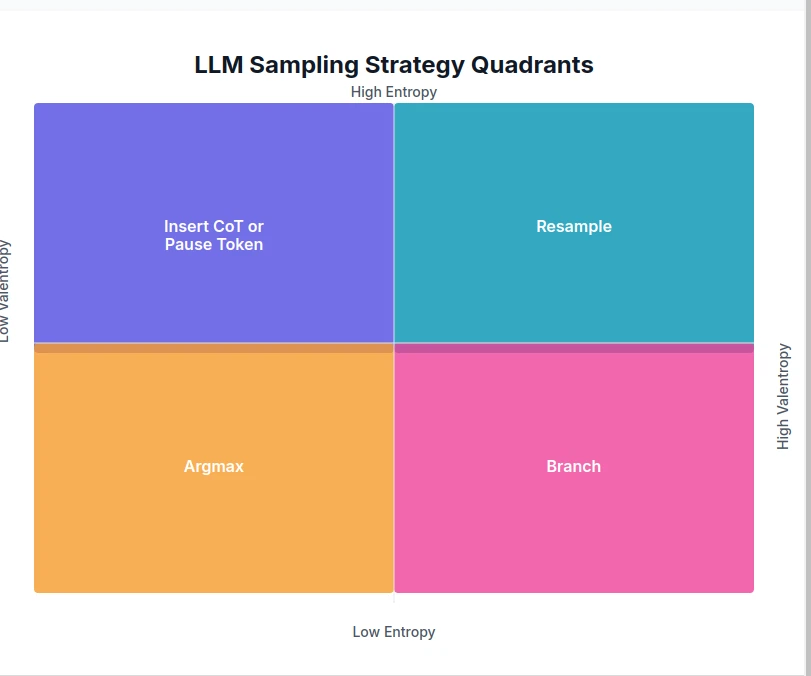
- バレントロピーが低い場合というのは、先ほど作った
p_0 - varentropy - そのうち、エントロピーが高いつまり左上の象限はプロットでいうと左端付近、すなわち各事象の確率が
1/n - 一方でプロットの右端付近、つまりほぼ確定的な状況ではエントロピーが
0 - バレントロピーが高いのはプロットの右の方の山のてっぺんあたりですが、このあたりではエントロピーは低いですから、右下の象限というのは典型的にはこのプロットのてっぺんあたりと考えることができるでしょう。この場合はBranchというアクションが取られます。
エントロピーもバレントロピーも高い状況というのはちょっとわかりにくいです。上でscipy.optimize.minimize()を使って
w_array = np.linspace(0, 1, 11)
print(w_array)
# [0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1. ]
p_list = list()
for w in w_array:
def loss_fn(p: NDArray[np.float64]) -> float|NDArray[np.float64]:
return -w*binary_entropy(p) - (1 - w)*np.sqrt(binary_varentropy(p))
result = minimize(loss_fn, bounds=[(0, 1)]*n, constraints=({"type": "eq", "fun": lambda x: x.sum() - 1}), x0=p0, tol=1e-10)
p = np.sort(result.x)
p_list.append(p)
p_mat = rearrange(p_list, "w n -> w n")
p_df = pd.DataFrame(np.log2(p_mat), index=[f"{w:.1f}" for w in w_array])
sns.heatmap(p_df)

グラデーションがわかりやすいように
Discussion