DDDを実践するための手引き(リポジトリパターン編)
以前DDDの入門記事を書いたのですが、ここではリポジトリパターンについて深掘って取り上げます。続編ぽいタイトルですが、そんなにつながりはないのでコレ単体で読めます。
はじめに
リポジトリパターンは、DDDで有名になった、ドメインモデルの永続化のためのデザインパターンです。
今やいろいろなところで「Repository」という名前を冠するクラスを目にするようになりましたが、誤解されたり誤用されることも多くあります。
ここではリポジトリパターンの意図や本質を理解することを目指します。リポジトリパターンには役立つ考え方が詰まっているので、このパターンを採用しなくても知っておくときっと役に立つと思います。
なお実装例はKotlinで書きますが、オブジェクト指向の言語であればだいたい同じ感じです。
リポジトリ(Repository)とは?
日本語訳は「保管庫」です。オブジェクトを保管しておき、必要なときに取り出せるという役割を持ったコンポーネントのことで、データベースへのアクセスを隠蔽します。
よくわかりませんね。噛み砕いて説明していきます。
まずざっくりとしたイメージ
リポジトリはこういう感じでオブジェクトの出し入れを担うやつです。
// オブジェクトを保存
val user: User = ...
userRepository.save(user)
// 保存したオブジェクトを取得
val user = userRepository.findById(userId)
User というモデルに対して、その保管庫として UserRepository を用意しています。UserRepository は 「User の集合(コレクション)」を抽象化した概念で、Userを保管したり取り出したりできます。
UserRepository の裏側にはDBなどの永続化技術がありますが、使う側に対してはその存在を意識させません。
エンティティ、リポジトリ
この User は「エンティティ (Entity)」と言われるものです。エンティティは「作成」→「変更」(* N回)→「削除」のようなライフサイクルを辿ります。その時々のエンティティをまるごと保存しておくものが「リポジトリ (Repository)」です。
集約
エンティティは必ずしもフラットなデータクラスではなく、ネストしたバリューオブジェクトや子エンティティを持っている場合があります。このエンティティを起点とするオブジェクトのまとまりを「集約 (Aggregate)」と呼び、起点となるエンティティを「集約ルート (Aggregate Root)」と呼びます。
リポジトリはこの「集約」をまるごと保存/取得/削除する役割があります。そのためリポジトリは集約ルートとなるエンティティとペアで用意します。(UserとUserRepositoryのように)
実践・リポジトリパターン
具体的な実装例を見ていきましょう。簡単なタスク管理アプリみたいなのを例に考えていきます。
前提: アーキテクチャ
DDDやクリーンアーキテクチャ的な実装では、ドメイン層(システムのコア部分)に業務ルールを凝集させていくことを目指します。そのため、その他の関心事を外側に追い出し、「ドメイン層をクリーンに保つ」という方針のアーキテクチャが採用されます。リポジトリパターンも、コア部分から永続化という関心事を分離する目的があります。
ここではレイヤードアーキテクチャ的な用語で紹介します。
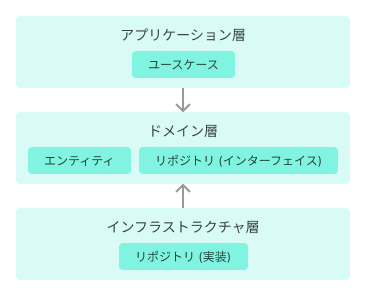
※矢印は依存の方向
※プレゼンテーション層は省略
- ドメイン層
- システムの中核
- ドメインモデル(業務ルールをピュアなモデルとして表現したもの)を置く
- エンティティ、リポジトリ(のインターフェイス)、バリューオブジェクト、ドメインサービスなど
- アプリケーション層
- アプリケーションとして成り立たせるための全体の調整役
- ドメインモデルを使ってユースケースを実現する
- インフラストラクチャ層
- 上位のレイヤを支える技術的機能(永続化、メッセージ送信など)
- リポジトリの実装はここに置く
各レイヤーはモノレポでモジュールを分けて作るのがおすすめです。(KotlinであればGradleのサブプロジェクト。依存関係や公開するインターフェイスを制御しやすいので)
ドメインモデルの実装
まずエンティティがありまして…
DDD的な設計においては、エンティティの状態が変化(作成/変更/削除)することによって基本的なビジネスロジックが実現されます。主役と言える存在です。
タスク管理アプリで「タスク」を表すエンティティはこんな雰囲気です。
package org.example.domain.task
class Task(
id: TaskId,
title: String,
completed: Boolean,
createdAt: LocalDateTime,
completedAt: LocalDateTime?,
) {
init {
require(...) // 不正な状態で作成できないようにしておく
}
// 「タスク」のプロパティ
// 本当はコンストラクタで引数に「val」「var」をつけたいが、Setterをprivateにしたいので冗長に定義
val id: TaskId = id
val title: String = title
var completed: Boolean = completed; private set // 不正な状態にさせないようにsetterを公開しない
val createdAt: LocalDateTime = createdAt
var completedAt: LocalDateTime? = completedAt; private set
/** タスクを完了する */
fun complete() { // setterを公開しない代わりに、モデルができることをメソッドとして公開
completed = true
completedAt = LocalDateTime.now()
}
companion object {
fun create(title: String) = Task(
id = TaskId(),
title = title,
completed = false,
createdAt = LocalDateTime.now(),
completedAt = null,
)
}
}
このエンティティは他の集約の一部ではないので集約ルートです。
「エンティティ」と聞くとRDBのテーブルを想起してまう人がいると思いますが、一旦RDBのことを忘れて、業務上の概念を正確に表現するためにモデルとしてどうあるべきかを先に考えましょう。
次にリポジトリがありまして…
集約ルートとなるエンティティを作ったらリポジトリも作ります。
TaskRepository は Task の保管庫であり、「Task の集合」を抽象化した概念です。インターフェイスのイメージとしてはこんな感じです。
package org.example.domain.task // エンティティと同じパッケージ(ディレクトリ)に置くのがおすすめ
interface TaskRepository {
// 保存(同一IDのエンティティが既に存在すれば置き換える。add/updateのようにメソッドを分けてもOK)
fun save(task: Task)
// 削除
fun delete(id: TaskId)
// 取得
fun findById(id: TaskId): Task? // getById,forId,taskOfIdのような命名のやり方もある。統一されていることが大事
fun findCompleted(): List<Task>
...
}
※ ここでは永続化指向なリポジトリとしてモデリングをしています(後で説明)
※ 実装のことは後で考えます。まずインターフェイスが大事
- save
- 受け取ったエンティティを保存する
- find〜
- 保存したエンティティを(保存時と全く同じ状態で)取り出す
- delete
- 保存したエンティティを削除する
基本的には必要なメソッドだけが定義されるのが望ましいとされています。
エンティティとリポジトリを使ってユースケースを実現
アプリケーション層ではこのような感じでユースケースが実現されます。
- エンティティを新規作成したり、エンティティの振る舞いを呼び出すことにより状態が変わる
- そのときの状態をリポジトリによって保存しておく
// タスクを新規作成
fun createTask(title: String) {
val task = Task.create(title)
taskRepository.save(task)
}
// タスクを完了する
fun completeTask(taskId: TaskId) {
val task = taskRepository.findById(taskId)
task.complete()
taskRepository.save(task)
}
リポジトリのインスタンスは(DIとかによって)コンストラクタとかから渡される想定です。ユースケースのロジックを書くときにはリポジトリの実装を意識する必要はありません。
リポジトリの実装
ここまででユースケースを実現するコードが書けました。あとはリポジトリの実装を作り、DIなどで差し込めば完成です。
素直な実装
先程の TaskRepository の実装を考えます。
このインターフェイスの意図を素直に表現するならこんな感じのイメージです。
// エンティティをメモリ上(インスタンス変数)に置いておく実装
class InMemoryTaskRepository: TaskRepository {
private val tasks = mutableMapOf<TaskId, Task>() // エンティティをインスタンス変数に持っておく
override fun save(task: Task) {
tasks[task.id] = task
}
override fun delete(id: TaskId) {
tasks.remove(id)
}
override fun findById(id: TaskId): Task? {
return tasks[id]
}
override fun findCompleted(): List<Task> {
return tasks.values.filter { it.completed }
}
}
できました! …が、これでは実用には耐えられません。
- 永続化されていないので、アプリケーションを落とせば消えてしまう
- 保持するエンティティの数が多いとメモリ上に乗り切らない
RDBを使用する実装
この問題を解決するために、エンティティをメモリ上ではなく、外部に永続化する実装を考えてみます。永続化先としてはRDBのテーブルを使う場合が多いですが、エンティティを永続化&復元できればNoSQLでもNewSQLでもなんでもOKです。
↓はRDB + Exposedを使った実装のイメージです。
class ExposedTaskRepository : TaskRepository {
override fun save(task: Task) {
Tasks.upsert { // upsertメソッドはExtensionで生やした
it[id] = task.id.value
it[title] = task.title
it[completed] = task.completed
it[createdAt] = task.createdAt
it[completedAt] = task.completedAt
}
}
override fun delete(id: TaskId) {
Tasks.deleteWhere { Tasks.id eq id.value }
}
override fun findById(id: TaskId): Task? {
return Tasks.select { Tasks.id eq id.value }.firstOrNull()?.toDomainModel()
}
override fun findCompleted(): List<Task> {
return Tasks.select { Tasks.completed eq true }.map { it.toDomainModel() }
}
private fun ResultRow.toDomainModel(): Task {
return Task(
TaskId(this[Tasks.id]),
this[Tasks.title],
this[Tasks.completed],
this[Tasks.createdAt],
this[Tasks.completedAt],
)
}
}
大事なポイント
設計のポイントについて深掘っていきます。
関心(関心事)の分離
リポジトリパターンが生まれたモチベーションは、ドメイン層をクリーンに保つために「永続化の手段」という関心事をその外側に追い出すということにあります。
- ドメイン層はシステムの中核であり、ドメインの問題に集中したい(本質的な複雑さ)
- 永続化や問い合わせの実装は複雑になりがち(付随的な複雑さ)
- なのでドメイン層から「永続化」という本質ではない複雑な関心事を追い出したい
リポジトリ=「エンティティの集合」という抽象化をすることにより、その具体的な手段や実装については「あとで考えればいい」(=ドメイン層の関心事ではない)という構造になります。
集約単位での取得・保存
リポジトリはエンティティ(集約)の部分的な保存・取得をしてはいけません。集約をまるごと保存し、まるごと取り出します。責務を「エンティティの出し入れ」だけに限定することによって、リポジトリの実装側に業務ロジックが入りこむ余地がなくなります。
interface TaskRepository {
// 保存の引数は集約ルートとなるエンティティ(またはそのコレクション)のみ
fun save(task: Task)
fun save(tasks: List<Task>)
// 取得の戻り値も集約ルートとなるエンティティ(またはそのコレクション)のみ
fun findById(id: TaskId): Task?
fun findCompleted(): List<Task>
}
もし仮に updateTitleById(id: TaskId) のようなメソッドをリポジトリに作ってしまうと、
- 個別のビジネスロジックがリポジトリの実装(具体的にはSQLのUPDATE文など)に漏れ出てしまう
- エンティティの状態の整合性を保証するのはエンティティの責務だが、SQLで個別に更新するとそれを破壊する可能性がある
同様の理由で、エンティティの更新日時をリポジトリの実装やDB側で自動で設定する、みたいなのもNGです。テーブルの列定義の DEFAULT 句などの利用も避けましょう。
考え方としては「リポジトリがエンティティの状態を更新する」のではなく、「エンティティ自身のふるまいによって状態が変更され、そのときの状態をリポジトリを使ってセーブしておく」という感じです。
オブジェクトがメモリ上にあるかのように見せかける
「エリック・エヴァンスのドメイン駆動設計」ではリポジトリの説明として以下のように述べられています。
あるオブジェクトを生成し、その型のすべてのオブジェクトで構成されるコレクションが、メモリ上にあると錯覚させることができるようにすること。
Eric Evans. エリック・エヴァンスのドメイン駆動設計 (Japanese Edition) (Kindle の位置No.3556-3557). Kindle 版.
実際には、リポジトリは渡されたエンティティの中身をDBのテーブルにマッピングして永続化し、取得するときにはテーブルから読みだした内容からエンティティを再構築して返しています。
が、使う側からすると、あたかもエンティティのインスタンスそのものがリポジトリに保管されていて、必要なときにそのまま取り出して使える、というように見えます。
依存性逆転の原則 (Dependency Inversion Principle)
「依存性逆転の原則」(または「依存関係逆転の原則」)はSOLID原則の一つで、「Clean Architecture」によると次のように定義されています。
上位レベルの方針の実装コードは、下位レベルの詳細の実装コードに依存すべきではなく、逆に詳細側が方針に依存すべきであるという原則。
Robert C.Martin,角 征典,高木 正弘. Clean Architecture 達人に学ぶソフトウェアの構造と設計 (Japanese Edition) (Kindle Locations 1142-1144). Kindle Edition.
「上位」というのはクリーンアーキテクチャの例のあの同心円で言うと、より内側にあるもののことです。
リポジトリパターンはこの原則を体現しています。
もしリポジトリをインターフェイスと実装に分けずに普通に実装したら、リポジトリ(ドメイン層)は永続化の具体的な技術(RDB, ORMなど)に依存することになります。
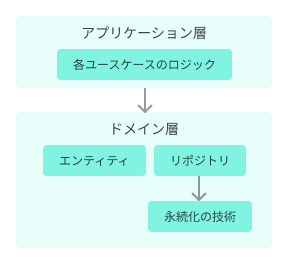
※ 矢印は依存の方向
ドメイン層をとにかくクリーンに保ちたい(=永続化の技術に依存しないようにしたい)…と考えたときに、リポジトリのインターフェイスの部分だけをドメイン層に置いて、そのインターフェイスを使った実装はドメイン層の外側に置くという方法を取ります。

ドメイン層とインフラストラクチャ層の間の依存の方向が先ほどとは逆になっています。これが依存性の逆転です。
ドメイン層から永続化技術への依存を排除するために、リポジトリのインターフェイスにその実装が依存するようにしています。要するに 「重要なもの(上位、方針、本質的)」に「重要でないもの」(下位、詳細、副次的)が依存する ようにしなさいということです。
この考え方はフレームワークやライブラリを作るときにも有用です。
例えばロギングライブラリを作るときに、ロギングのコアとなるAPI部分は何にも依存しないようにクリーンに作って、具体的なログ出力の実装はAPI部分によって定義されたインターフェイスに依存するように作る、とかです。
// ロガーのコア部分 ===========
class Logger(private val appender: LogAppender) {
fun debug(message: String) = appender.append(message, Level.DEBUG)
fun info(message: String) = appender.append(message, Level.INFO)
fun warn(message: String) = appender.append(message, Level.WARN)
fun error(message: String) = appender.append(message, Level.DEBUG)
}
enum class Level {
DEBUG, INFO, WARN, ERROR
}
interface LogAppender {
fun append(message: String, level: Level)
}
// 具体的な出力方法の実装 ===========
// コンソールに出力する実装
class ConsoleAppender : LogAppender {
override fun append(message: String, level: Level) = println("$level: $message")
}
// ファイルに出力する実装
class FileAppender(private val file: File) : LogAppender {
override fun append(message: String, level: Level) = file.appendText("$level: $message\n")
}
// クラウドストレージに出力する実装
class CloudStorageAppender(private val bucketName: String, private val objectName: String) : LogAppender {
...
}
一般的にI/Oからの距離が遠いほど安定、近いほど不安定になります。リポジトリパターンでもロギングライブラリでも、コア部分がI/Oの実装に依存しないように、抽象化して分離しているという点で同じ構造です。
- コア部分:
- 本質的、安定、方針、I/Oを含まない
- なるべくクリーンに作る
- 具体的な出力部分:
- 副次的、不安定、詳細、I/Oを含む
- DBへのアクセス、ファイル出力、外部APIの呼び出し、など
Advancedなノウハウ
複雑な構造の集約を扱う
例えば先程の Task に reminders という項目を足したとしましょう。
class Task(...) {
val id: TaskId
val title: String
val reminders: List<TaskReminder> // 🆕
...
}
/** リマインダの設定 */
data class TaskReminder(
/** リマインド日時 */
val datetime: LocalDateTime,
/** リマインドを繰り返す周期 */
val repeatFrequency: RepeatFrequency,
) {
enum class RepeatFrequency { NEVER, HOURLY, DAILY, WEEKLY }
}
reminders は既存のプロパティと比べて、複雑な構造を持っていますが、reminders も含めてひとまとまりの Task という概念だと捉えるのは自然です。
このような場合でも、リポジトリは集約単位で保存・取得します。
リポジトリの実装としてRDBを使うならreminders の部分は正規化して保存するのが良さそうです。必ずしも1つの集約が1つのテーブルに永続化されるとは限らないのが味噌です。
どういうテーブル構造で保存するかは永続化技術の都合であり、使う側から見たときに集約をまるごと出し入れでき、集約の部分に直接アクセスさせないというのが大事です。
なお、 TaskReminder を独立したエンティティ(集約ルート)としてモデリングし、IDを通して関連付けるというやり方もあると思います。
Repositoryの2つの抽象化方針
ヴォーン・ヴァーノン氏の「実践ドメイン駆動設計」では、リポジトリのインターフェイスの抽象化の形として「永続化指向」「コレクション指向」の2つのやり方が紹介されています。主にオブジェクトへの保存の挙動に違いがあります。
永続化指向(Persistence-oriented)
今までの実装例で見てきたものはこちらです。
コレクション指向と比べたときの特徴としては、「リポジトリから取り出したオブジェクトの状態を変更するたびに保存しなくてはならない」というところです。
コレクション指向(Collection-oriented)
コレクションのように振る舞うインターフェイスを提供します。
具体的には、JavaやKotlinで言うとSetを模倣します。(同じIDを持つエンティティは1つしか存在しないという点で、Set に近いため)
-
Setのようにaddやremoveのなどのメソッドを持っている - リポジトリから取得したオブジェクトの状態を変えたときに書き戻す必要がない
- つまりリポジトリから取り出したオブジェクトの状態を変更したときに、それを改めて
addしなくても、次に取得したときに変更後の状態のオブジェクトを取得できる
- つまりリポジトリから取り出したオブジェクトの状態を変更したときに、それを改めて
interface TaskRepository {
fun add(task: Task) // Set<Task> に寄せた命名
fun remove(task: Task) // Set<Task> に寄せた命名
// 取得系のメソッド
...
}
// 使う側 ==========
// タスクを新規作成
fun createTask(title: String) {
val task = Task.create(title)
taskRepository.add(task)
}
// タスクを完了する
fun completeTask(taskId: TaskId) {
val task = taskRepository.findById(taskId)
task.complete()
// 永続化指向の場合と違って、リポジトリに書き戻す必要がない
// (Setから取り出したオブジェクトの状態を変更してもaddし直す必要がない、という挙動を完全に真似る)
}
「書き戻さなくていい」という特徴を実現するために、リポジトリから取り出したオブジェクトの変更をトラッキングし、裏側で自動的に永続化するという仕組みが必要になります。実装の差し替えも難しくなるということもあり、個人的にはあまりおすすめしません。
エンティティのIDの生成はどこでやる?
いくつかのやり方がありますが、大きく分けて「エンティティ作成時にIDを発行する」派と「エンティティ保存時にIDを発行する」派があります。
エンティティ作成時にIDを発行する派
ヴォーン・ヴァーノン氏の「実践ドメイン駆動設計」ではリポジトリにIDを生成するメソッドを持たせる実装例が紹介されています。ID生成はインフラストラクチャ側の都合と言えるので、妥当な方法と言えるでしょう。
// ドメイン層 ==========
interface TaskRepository {
// 保存・取得などのメソッド
// ...
fun nextIdentity(): TaskId
}
// インフラストラクチャ層 ==========
class TaskRepositoryImpl: TaskRepository {
// UUIDを使った実装
override fun nextIdentity() = TaskId(UUID.randomUUID())
}
// アプリケーション層 ==========
// Taskを新規作成する
val task = Task.create(
id = taskRepository.nextIdentity(),
titile = title,
)
個人的にはわざわざリポジトリに持たせるのは面倒なので、エンティティのファクトリ内で生成してしまいたい派です。(ID生成知識がドメイン層に入ってしまいますが、ファクトリーメソッド内に閉じているし許してほしい…)
class Task(...) {
...
companion object {
fun create(title: String) = Task(
id = TaskId(UUID.randomUUID()), // もしくはTaskId側に新規生成のファクトリメソッドを作る
title = title,
completed = false,
...
)
}
}
エンティティ保存時にIDを発行する派
DB側に生成を任せたい場合で、具体的には SEQUENCE や AUTO_INCREMENT などで生成した値を使います。
テーブルにINSERTするまでIDが発番されないので、リポジトリのsaveメソッドの実装内で、テーブルへのINSERTによって発番されたIDをエンティティに書き込むということをします。
// ドメイン層 ==========
class Task(...) {
// IDはnullableにしてSetterを公開しておく
// 保存のタイミングでRepositoryによってsetされる
var id: TaskId?
companion object {
fun create(title: String) = Task(
id = null, // エンティティ作成時にはnullにしておく
title = title,
...
)
}
}
// インフラストラクチャ層 ==========
// Exposedを使った実装例
class ExposedTaskRepository : TaskRepository {
override fun save(task: Task) {
if (task.id == null) {
// 新規作成時
val idValue = Tasks.insert {
it[title] = task.title.value
it[completed] = task.completed
it[createdAt] = task.createdAt
it[completedAt] = task.completedAt
} get Tasks.id
task.id = TaskId(idValue) // DBによって発行された値をエンティティに書き込む
} else {
// 更新時
}
}
デメリットが大きいので基本的にはあまり良くないと思います。
- エンティティのIDを書き込む責務をリポジトリが負ってしまう
- IDのSetterを(リポジトリの実装クラスに対して)公開しなくてはならない
- 実際に保存されるまでの間、IDにnull的なものが入るのを許容しなくてはならない
最後に
リポジトリパターン自体をそのまま採用することがなくても、「関心事をどう分離するか」「ものごとをどう抽象化して扱うか」などの考え方やテクニックはわりと汎用的に使えると思うので、是非生かしていただけたらと思います。また、「依存性逆転の原則」「集約」「クリーンアーキテクチャ」などのワードについてもさらに詳しく調べてみるとおもしろいかもしれません。
追記
リポジトリパターンはなかなか思い切った抽象化をするので、DBの機能性や利便性を享受しにくいという側面もあります。データ可視化やシンプルなCRUDが主題となるアプリケーションであればデータ中心アプローチが合うかもしれませんし、複雑な業務ルールを中心に据えるならここで紹介したような方法でドメイン層をクリーンに保つべきかもしれません。アーキテクチャはトレードオフがすべてです。
参考
Discussion