医療のマスターDBを爆速で検索するWebサービスを爆速で作った
ヘンリーの Lead Architect の kohii です。
先日、医療系の個人開発サービス MediXplorer を作ったので、簡単なサービス紹介と技術的に工夫したこととかについて書きます。
作ったもの
MediXplorer は厚労省(もしくは社会保険診療報酬支払基金)から提供される 医科診療行為マスター を検索・閲覧するためのWebアプリケーションです。
医科診療行為マスターって?
日本には診療報酬制度というものがあり、病院等が医療サービスを提供した際の医療費の計算ルールが定められています。このシステムのもと、医療機関は提供した医療行為ごとに決められた点数に基づき医療費を計算し、患者や保険組合に請求します。(初診料 = 288点 みたいなやつ。1点10円で、通常そのうちの3割を会計時に支払う。)
「医科診療行為マスター」は、これらの医療行為のデータベースの一つで、列数150、行数約1万のモンスター CSV としてこちらで提供されます。各電子カルテ・レセコンのベンダーはこれを取り込んで使っていて、Henry も同様です。
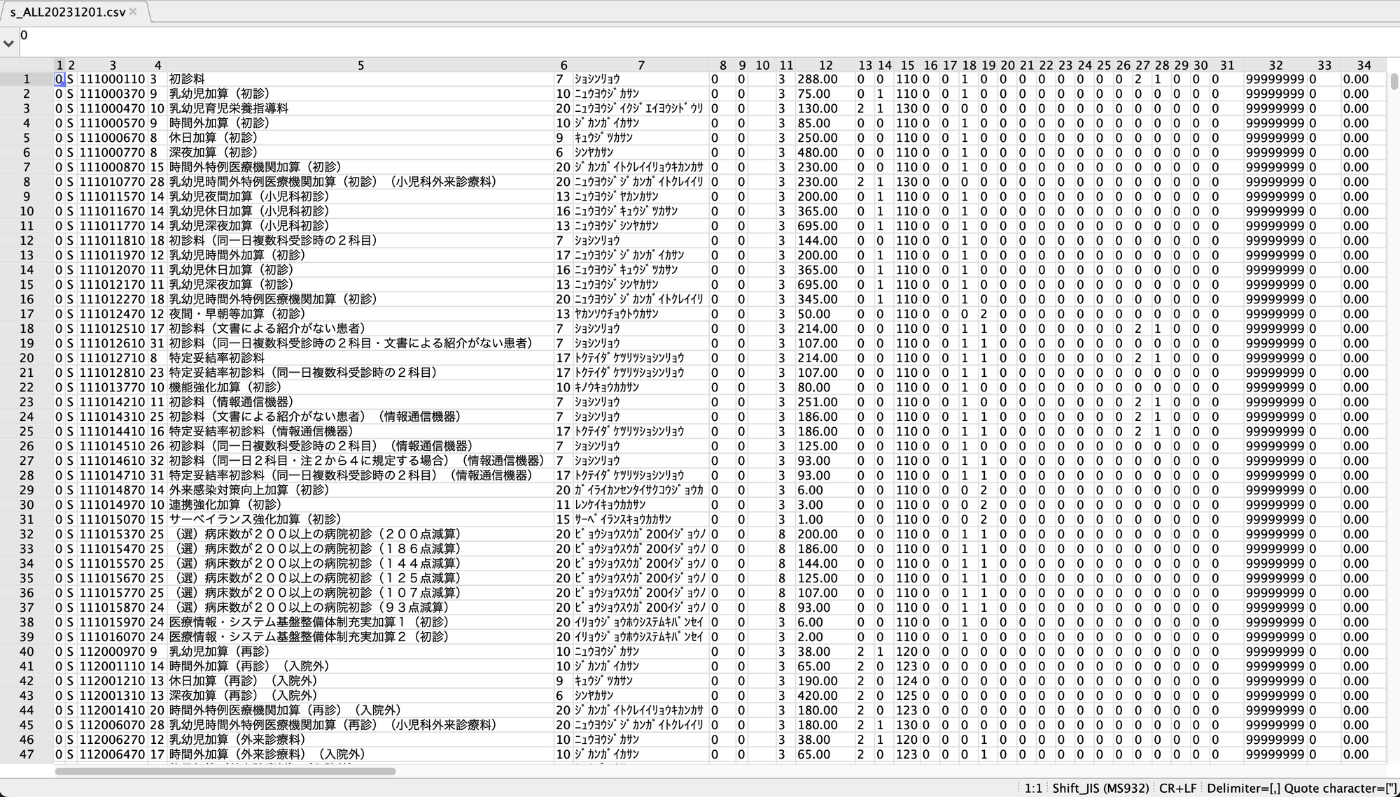
医科診療行為マスターを拙作のCSVエディタ「SmoothCSV」で開いた様子
ちなみに「歯科」診療行為マスターもあります。
MediXplorerって?
MediXplorer はこの診療行為マスターをブラウザ上でいい感じに検索・閲覧できるというシンプルなサービスです。
トップページ。検索窓があるだけ

検索結果
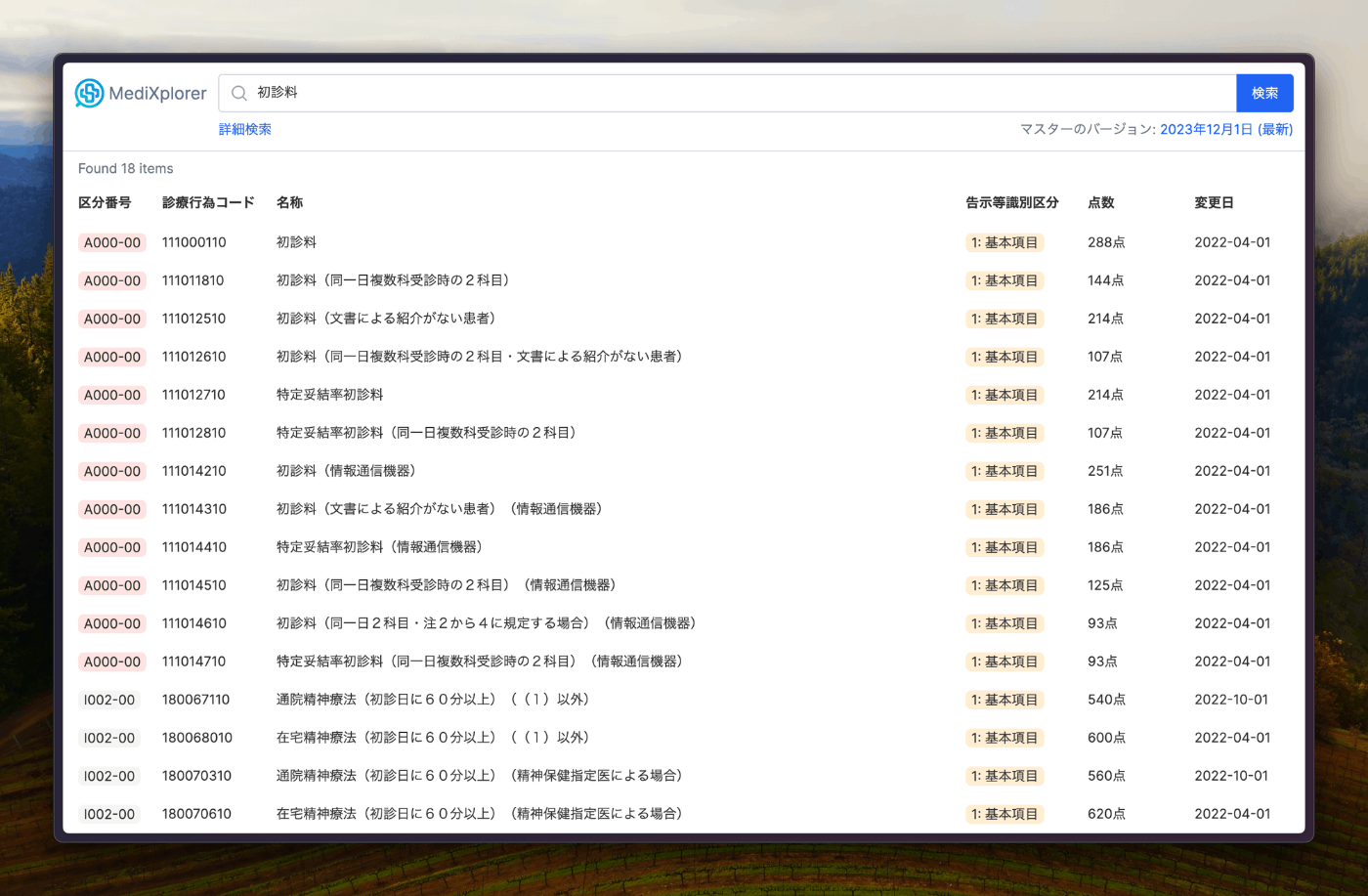
診療行為の詳細

詳細検索もできる
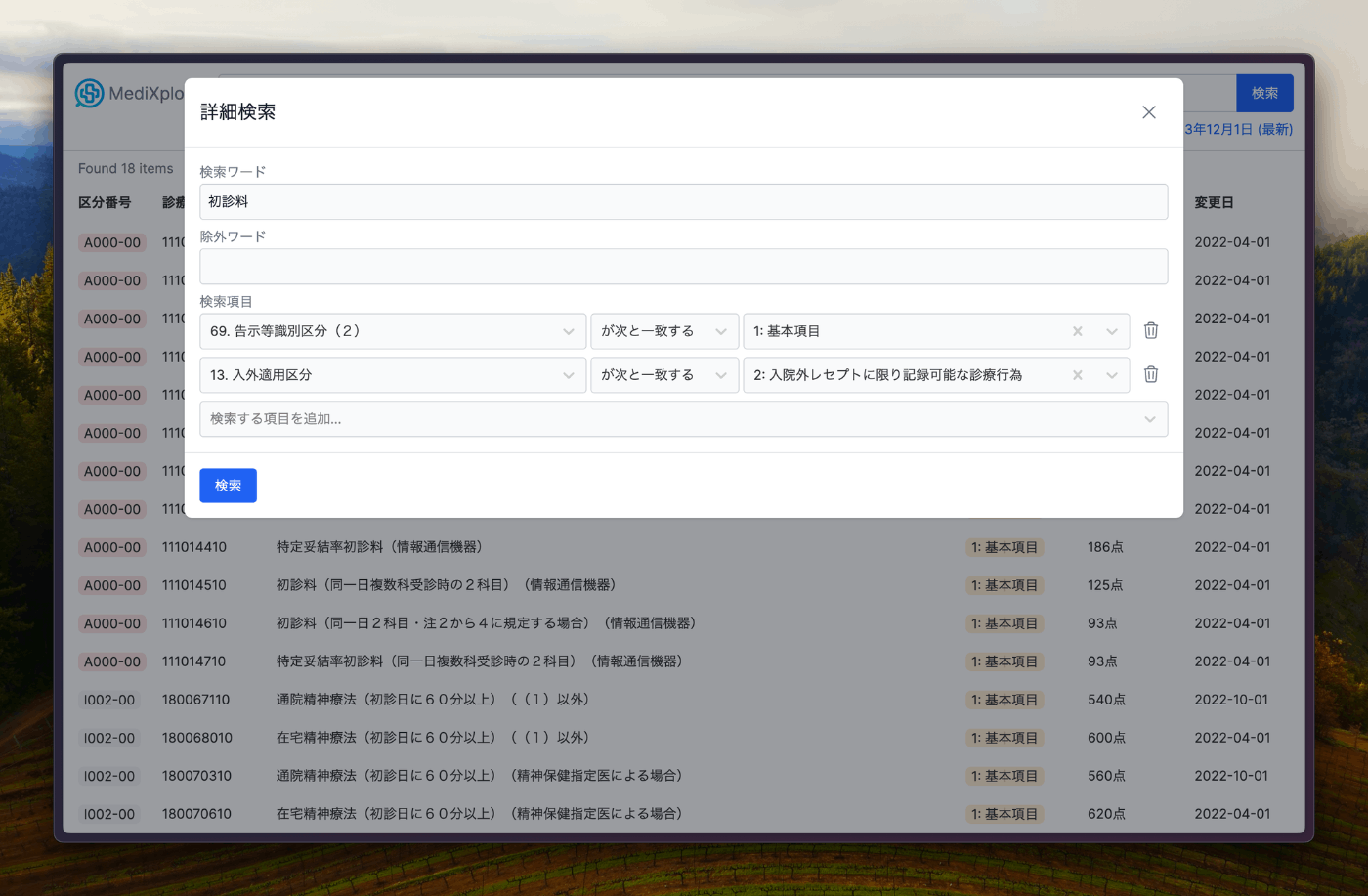
動機
先日ドメイン知識習熟のために医療事務の資格試験を受けたのですが、試験勉強中に参考書や問題集に出てくる各診療行為がマスター上でどのように表現されているかを見たくなることがありました。最初は RDB にデータを入れて SQL で検索していましたが、「これは人間の読むものじゃねえ..」という気持ちになりカッとなって作りました。
特に難解だったデータはここらへん
「きざみ値」というデータは30〜35列目に渡って記録されており、仕様書(PDF)はこんな感じです。テーブルの枠をぶち抜いて表や計算式が現れるあたりや、計算式中の「↑」や「↓」の表記に趣があります。

その後社内で共有したところ想像の10倍くらい喜んでもらえたので、フィードバックやドッグフーディングを元に改善中です。
コード
AGPL-3.0 ライセンスの下で公開しています。
社内で共有したら @Kengo_TODA さんが速攻で Contribute してくれて、さすが界隈の人だな〜と思いました。
技術構成
サーバーサイドに状態を持たないので非常にシンプルです。
-
Next.js on Cloudflare Pages
- Next.js といえば Vercel だが、Cloudflare Pages へのデプロイも 公式ガイド が用意されている
- コマンド一撃でプロジェクト作成〜デプロイまで整うのが非常に体験が良かった
- Cloudflare は個人で使う用途なら殆どのことは無料ででき、機能も充実しており、Preview 環境も付いてくるので最高
- Next.js といえば Vercel だが、Cloudflare Pages へのデプロイも 公式ガイド が用意されている
-
Tailwind CSS
- なんとなく忌避してたけど、使ってみたらもう全部これでいいやという気持ちになった
- アイコンは heroicons.com
-
GitHub Actions
- CI/CD として
- 新しいマスターデータの公開を検知・取得して Pull Request を作る Bot として
爆速な検索・閲覧体験を支える技術
MediXplorer は阿部寛さんのホームページ並に爆速な体験を実現しています。
戦略
- トップページは頑張る
- マスターデータの検索・表示はクライアントサイドで完結させる
- トップページにいる間に検索結果ページで必要なデータ等をプリフェッチしておく
一応モバイルでも使えますが、デスクトップファーストで考えています。
1. トップページ頑張る
まずトップページの PageSpeed Insights の Performance スコアを100点にします 💯
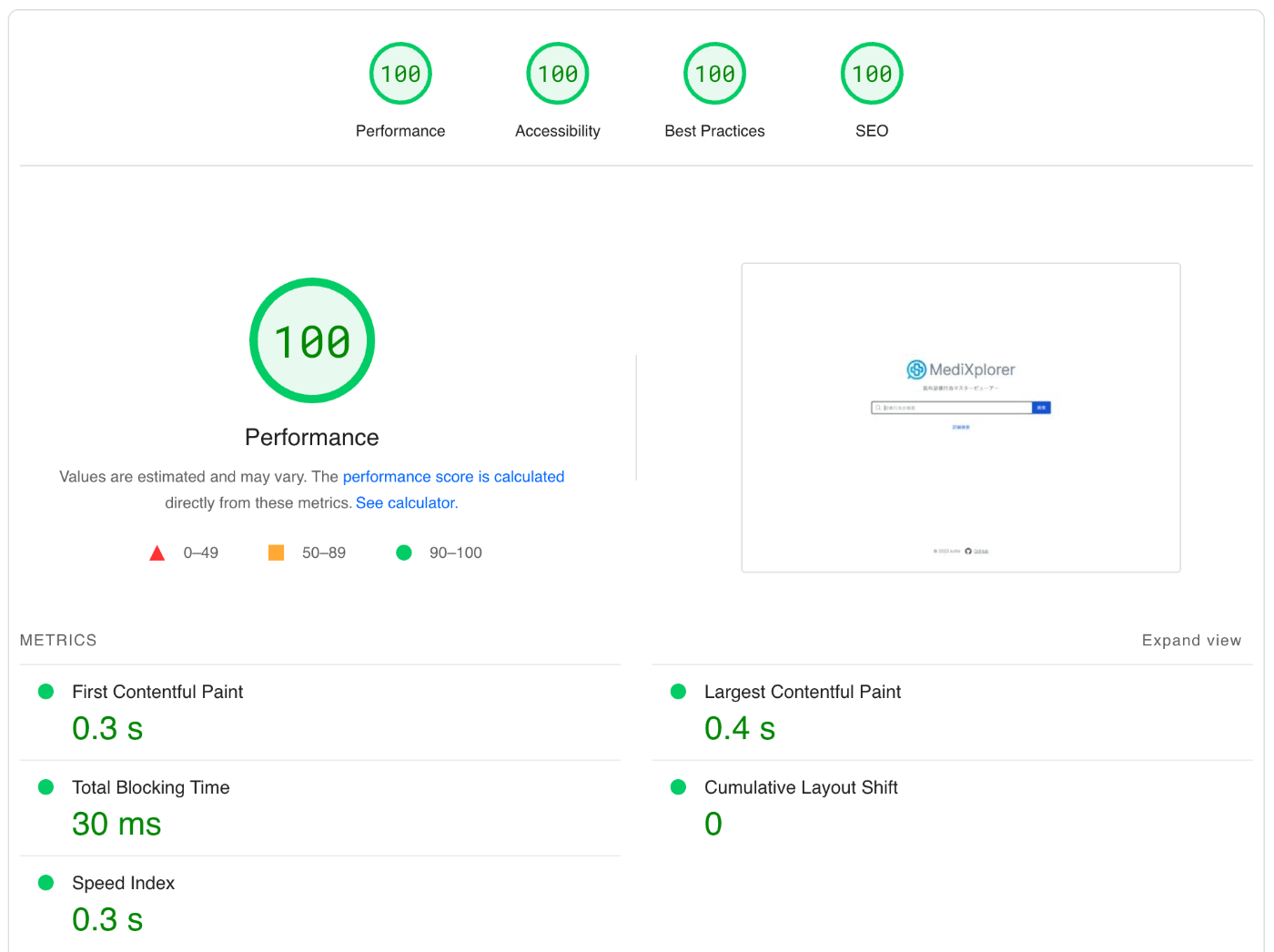
https://pagespeed.web.dev/analysis/https-medi-xplorer-com/1itrpv19ew?form_factor=desktop
以下、頑張ったポイントです。
重いライブラリをなるべく import しない
基本中の基本ですが、シンプルなページであってもなんだかんだ芋づる式に不要なライブラリやコードを巻き込んでしまうのはあるあるです。
- Bundle Analyzer で確認しながら不要な依存を切り離していく
- 初期表示で隠れているコンポーネントは Lazy Loading する
- Dialogなど、
{isOpen && <Foo />}みたいなコンポーネントはLazy loading候補
- Dialogなど、
App Router の力を活かす
- なるべく
“use client”しない or“use client”するのは枝葉の部分に絞る- トップページでは検索窓の部分だけが state や event handler を使う
-
useSearchParams を使わない or 使う場合は枝葉の部分に絞り
<Suspense>で囲む- useSearchParams を使用したコードはサーバーサイドでレンダリングできず、ページ全体がクライアントサイドでレンダリングされてしまう
-
<Suspense>で囲えばサーバーサイドでレンダリングされない範囲を限定できる
あとは Cloudflare の力で爆速にサーブします。
2. マスターデータの検索・表示はクライアントサイドで完結させる
Next.js App Router の思想と逆行しますが、大体の場合はクライアントサイドで処理する方がやはり速いことが多いです。(検索結果ページは検索エンジンにインデックスされないようにしていますし、SEO観点でもあまり気にする必要がありません。)
マスターの CSV を(ほぼ)そのままクライアントサイドに持ってきて使う
診療行為マスターの CSV をクライアントサイドに持ってきてしまい、検索・表示することで爆速な検索体験を実現しています。
そのままでも十分高速でしたが、いくつか気になった課題があり対策しました。
課題
- やはりデカい
- 未圧縮時で約6.8 MB
- 150列×約1万行ある(128列目以降は”予備”の列であり全部空文字)
- 文字コードが Shift_JIS
- JS でそのまま読めないのでデコードする必要あり
- TextDecoder でできるがちょっと重めの処理
対策
- CSV をそのまま配信せずに、ビルド時に加工しておく
- 文字コードを UTF-8 にする
- → フロントエンドでデコードする必要がなくなり、Blocking time が減った
- CSV から TSV に変換する
- → 囲み文字が不要になり容量削減
- → CSVパーサーが必要なくなり、
line.split(”\t”)でパースできる(軽量化&高速化)
- 128列目以降は不要なので削除する
- 文字コードを UTF-8 にする
- Brotli 圧縮して配信
- Brotli は高速・高効率な圧縮アルゴリズム
- 上記加工済みのTSVで約4.5 MB → Brotli圧縮で435 KB
- 圧縮/解凍は Cloudflare ↔ Browser 間で勝手にやってくれる
- ただし、デフォルトでは CSV や TSV は圧縮対象にならない
- Cloudflare はレスポンスヘッダーの Content-Type を見て圧縮するかどうか決める
- TSV ファイルを
text/plainとして配信することで圧縮対象にした
バーチャルスクロール
最大約1万行の検索結果をレンダリングするのは無茶なので、スクロールの動きに合わせて表示領域に入った部分(+前後10行)だけをレンダリングします。
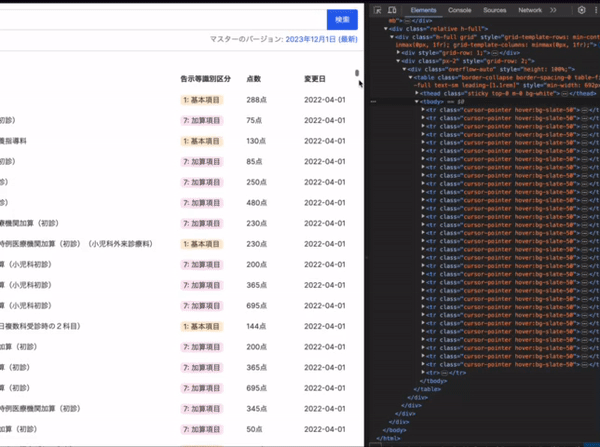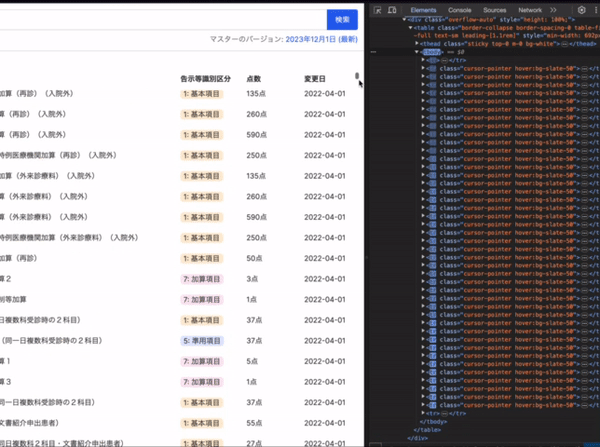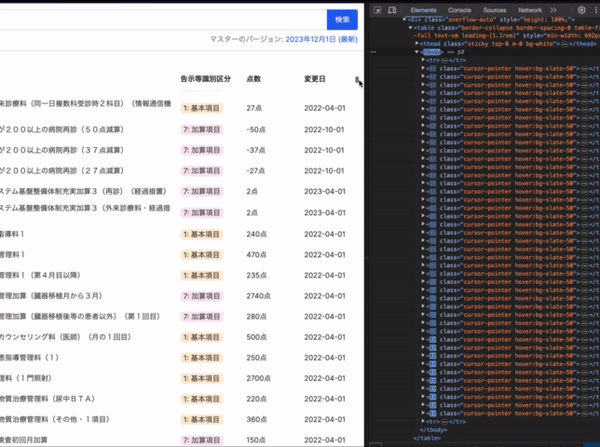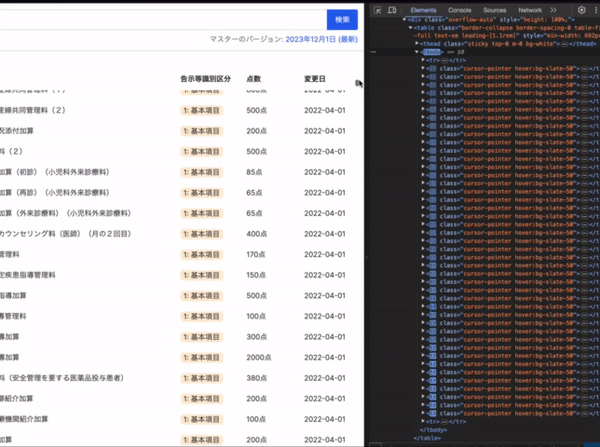
これは TanStack Table + TanStack Virtual で実現しています。どちらも Headless な UI ライブラリです。TanStack のライブラリはとてもよく出来ていて結構好きです。
大量のデータを表示する方法としてページネーションもありますが、状態が増える、画面上のパーツが増える、閲覧時の手数が増えるということでバーチャルスクロールの方がベターと判断しました。
3. トップページにいる間に検索結果ページで必要なデータ等をプリフェッチしておく
トップページ表示後、ユーザーが検索ワードを入力している間に、検索結果ページで必要なデータを prefetch しておきます。
検索結果ページの prefetch
Prefetchとは次に表示される(であろう)ページやデータを事前取得しておき、高速にナビゲーションできるようにするものです。
Next.jsでは <Link> コンポーネントがブラウザで描画された際にリンク先のページを勝手にprefetchしますが、MediXplorer のトップページから検索結果への移動はリンクによるものではありません。このような場合は router.prefetch() を使用して明示的に prefetch しておきます。
コード例
import { useRouter } from "next/navigation";
const { prefetch } = useRouter();
// トップページ表示後に、検索結果ページをprefetchする
useEffect(() => prefetch("/s"), [prefetch]);
マスターデータの prefetch
前述の通り検索はクライアントサイドで行うため、マスターデータ(TSV)も prefetch しておきます。MediXplorer では TanStack Query を使用しており、次のようなイメージで prefetch できます。
コード例
import { usePrefetchQuery } from "@tanstack/react-query";
usePrefetchQuery({
queryKey: ["..."],
queryFn: () => fetchMasterData(...), // fetchMasterDataの中でTSVのパースまで済ませてあるのですぐに使える
});
// (本当はもっと横着なことをしている...)
その他、工夫したこと
useState を極力使わず、URL に状態を反映する
検索クエリや選択中の診療行為のキーなどの情報は、useState ではなく URL に記録します。

画面の表示状態が URL に反映されるため、以下のようなメリットがあります。
- URL をコピーしてそのまま共有できる / ブックマークできる
- ブラウザの進む/戻るで状態を復元できる
最適な検索体験を提供するためのクエリー設計
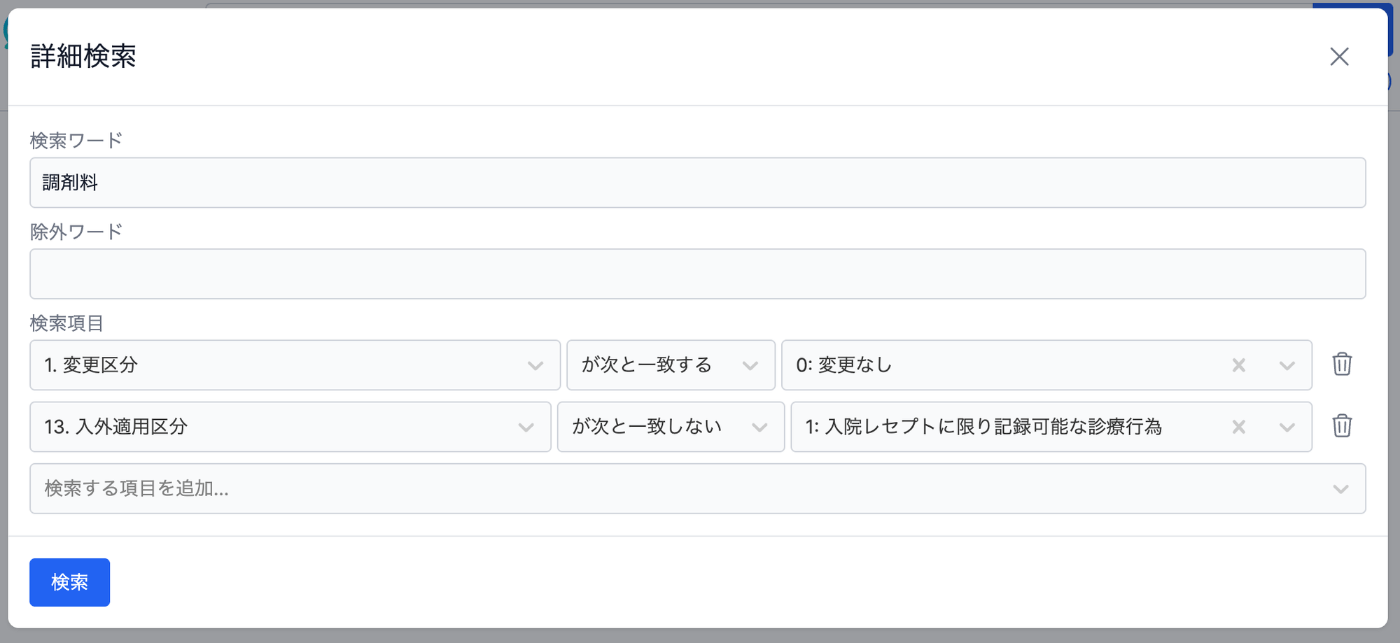
MediXplorer では ①キーワードによる検索と、②各列の値を指定した詳細な検索の両方が可能ですが、どちらも検索クエリーのシンタックスの一つとして同列に扱っています。
検索クエリーの例

「初診料」という文字列を含むものを検索

-をつけて除外できる(「初診料」を含み、かつ「情報通信」を含まないものを検索)

各列の値を指定して検索(「入外適用区分」という名前の列の値が「1」と一致するものを検索)

複数の値を指定できる(いずれかに一致するものを検索)

大小比較による検索もできる

組み合わせいろいろ。列を指定した記法はハイライトされるため区別しやすい。
詳細検索ダイアログは↑の記法を生成するものになっている
設計意図
- モードがない(e.g. 通常検索モード、詳細検索モード)
- ユーザーは単純なキーワードによる検索から始め、その後詳細な条件を追加して絞り込んでいける
- モードが増える = 実装時も利用時も手数が増える
- 検索クエリーは単なる文字列なので扱いやすい
- URLに入れやすい(
?q=初診料みたいに)
- URLに入れやすい(
- GUI(詳細検索ダイアログ)との相性が良い
- 簡単に parse/format できるため、GUI でクエリを操作する機能を作りやすい
おわりに
医療業界の方々、特に診療報酬制度と戦っている方、ぜひ MediXplorer を使ってみてください。要望歓迎です。医薬品マスターも要望があったのでそのうち対応したいと思っています。
コードも GitHub 上に公開しているのでエンジニアの方は Contribute も歓迎です。(急いで作ったのでコード汚いしテストあまりないです…
最後まで読んでいただきありがとうございました🙇♂️
Discussion