pulumiについてメモ
pulumiのドキュメントなどを読んだ感想、メモを書いていく。
まず、pulumiには
- OSSとして公開されているIaCソフトウェア
- SaaSとしてpulumiをmanageするソフトウェア
の2つが存在する。
ひとまず、OSSの方を見ていく。
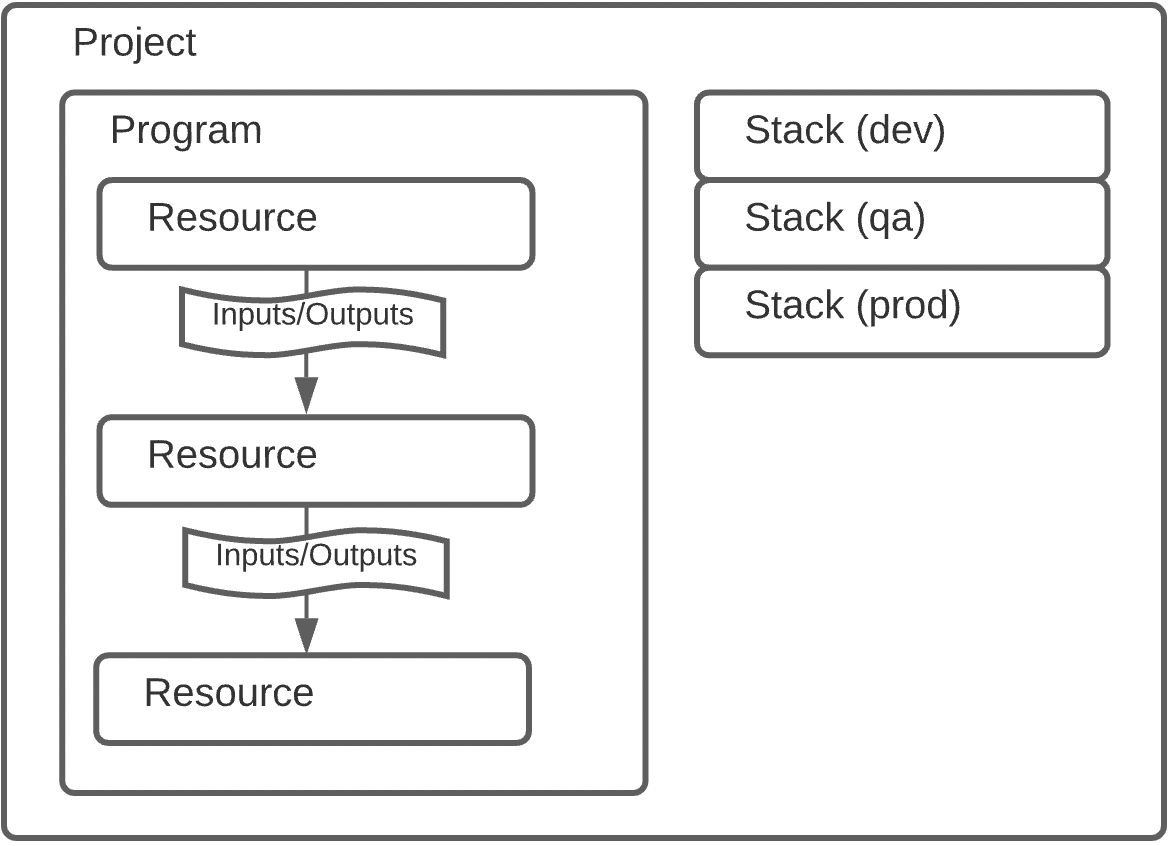
↑の図が紹介されている。
StackはおそらくTerraformでいうところのtfstateみたいなやつ。だと思ったけど、違いそう。
Programはリソースがあるべき姿を記述するためのもの。
ProjectはProgramとProgramを実行するためのMetadataを含んでいる。
ResourceはおそらくProgram内の一要素に過ぎなそう。ec2オブジェクトとかそういうやつ?
基本的に動作はTerraformっぽい。
プログラムを書いて理想状態のStackを記述し、現在のStackとの比較があれば、実際のインフラを更新する。
リソースの命名にユニークとなるようにsuffixが付与されるらしいのが気になる。既存のリソースをインポートした時に便利設定が外れてしまいそう。
Resources
ResourceはEC2, S3, k8s clusterなどのインフラを構成するための基礎的なユニットのことである。
Resourceは2種類ある。
- CustomResource
- AWSなどのresource providerによって提供されるResource
- ComponentResource
- コンポーネントリソースとは、他のリソースを論理的にグループ化し、その実装の詳細をカプセル化した、より大きな、より高いレベルの抽象化を作成するものである。(deepl)
Inputs and Outputs
Outputは非同期で値が分かる。
それらをいい感じに扱うために
- apply
- all
- lifting
- interpolation
関数がある。
Secrets
const cfg = new pulumi.Config()
const param = new aws.ssm.Parameter("a-secret-param", {
type: "SecureString",
value: cfg.requireSecret("my-secret-value"),
});
stateにシークレット値がハードコーディングされないように↑のように書ける。
valueキーの値を環境変数で設定するようにすれば、git管理しやすそう。
.envファイルだけ別途管理する必要があるけど。
Assets and Archives
ファイルやリモートから取得したリソースなどを扱うためにAssetsとArchivesという概念がある。
Assetsはファイル、Archivesはzipなどの圧縮されたファイルを扱う概念。
Function Serialization
Lambdaにデプロイするコードをpulumi上でインラインに記述することができる?
ドキュメントを流し読みした限りだとかなり便利そう。
pulumiのimport、めちゃくちゃ便利そう。
jsonを使って一括インポート & インポート後は自動でコードを生成してくれるらしく、めちゃくちゃ良さそう。
pulumiでどういうディレクトリ構成で進めるか
terraformはworking directory直下のtfファイルは全て実行するみたいな感じだったけど、pulumiはentry pointが決まっていて、それのみを実行するスタイルっぽい。
複数stack(環境)に対してソースコードは1つという構成。
getStack関数で選択中のstackを取得できて、それを使ってソースコード中で分岐するのが良さそう。
index.ts内で
if "prod" == getStack() {
updateProdStack()
} else if "stg" == getStack() {
updateStgStack()
} else {
throw new Expection()
}
みたいなことをして、それぞれのstackに適用するprogramを書いていくのが良さそう。
この感じだとStackReferenceをグローバルステートとして扱うのが良いのか、、っていう気持ちになる。
ただそれをするには、StackOutputにデータを登録するための術がないと厳しい。
疑問点
- どうしてaws.ec2.SecurityGroupのプロパティは全てreadonlyなのか?