Prometheus Up and Runningのメモ
すべてのイベントのすべてのコンテキストを持つことは、デバッグや、技術的およびビジネス的な観点からシステムのパフォーマンスを理解するために素晴らしいことですが、そのような量のデータを処理して保存することは現実的ではありません。そのため、データ量を実用的なものに減らすアプローチとして、プロファイリング、トレース、ロギング、メトリクスの4つの方法があります。
モニタリングには
- プロファイリング
システム・プロファイラとは、コンピュータにインストールされているソフトウェアや接続されているハードウェアに関する詳細な情報を提供することができるプログラムである。
https://en.wikipedia.org/wiki/System_profiler
- トレース
分散トレースは、アプリケーションのリクエストがフロントエンドのデバイスからバックエンドのサービスやデータベースに流れるのを追跡する方法です。
https://www.datadoghq.com/knowledge-center/distributed-tracing/
- ロギング
ロギングは、動詞としても名詞としても使われ、エラーや変更をロギングすること、あるいは、収集されたアプリケーショ ン・ログを指します。ロギングの目的は、アプリケーションイベントの継続的な記録を作成することです。
https://www.appdynamics.com/product/how-it-works/application-analytics/log-analytics/monitoring-vs-logging-best-practices
- メトリクス
メトリクスはコンテクストをほとんど無視し、代わりにさまざまなタイプのイベントの経時的な集計を追跡する。リソースの使用量をまともに保つためには、追跡される異なる数値の量を制限する必要がある:プロセスあたり10,000件が妥当な上限である。
例えば、HTTPリクエストの受信回数、リクエスト処理に費やされた時間、現在処理中のリクエストの数などです。 コンテキストに関するいかなる情報も除外することで、データ量と必要な処理は合理的に保たれます。
引用リンク
がある。
Prometheusはメトリクスのために作られている。
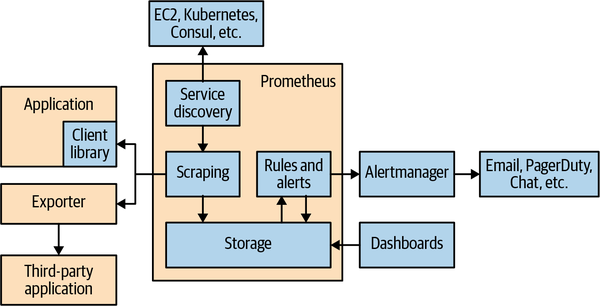
client library
Goならこれ https://pkg.go.dev/github.com/prometheus/client_golang/prometheus
exporter
エクスポータは、メトリクスを取得したいアプリケーションのすぐそばに配置するソフトウェアです。Prometheusからのリクエストを受け取り、アプリケーションから必要なデータを収集し、正しい形式に変換して、最後にPrometheusにレスポンスとして返します。
引用元
service discovery
モニタリング対象のサービスがどこにあるのか知るためのレイヤー
scraping
モニタリング対象にhttpリクエストを飛ばして、メトリクスを収集する
そのhttpリクエストをscrapeと呼んでいる
storage
やっぱりここがprometheusの一番面白そうなところ。コードを読んでみよう。
Prometheusが得意とすることはひとつ。シンプルかつ強力なデータモデルとクエリ言語を持っており、アプリケーションやインフラストラクチャのパフォーマンスを分析することができます。Prometheusは、メトリクスの領域外の問題を解決しようとせず、より適切な他のツールに任せています。
引用元
こういう一つの目的に特化したアプリケーションをいくつか作り込んで、モニタリングを可能とさせるGrafana社はかっこいいなーと思った。
prometheus.ymlの説明とかはこの辺見ると良さそう。
- https://prometheus.io/docs/prometheus/latest/configuration/configuration/
- https://github.com/prometheus/prometheus/blob/release-2.47/config/testdata/conf.good.yml
アラートには2つのパートがある。まず、Prometheusにアラートルールを追加し、アラートを構成するロジックを定義します。 2つ目は、アラートマネージャがアラートを電子メール、ページ、チャットメッセージなどの通知に変換することです。
引用元
こういうのも良いソフトウェアだよなぁ。
特定のページャーシステム(pager duty or メール or チャットなど)に変換する処理をprometheusに持たせない。変換する層を設ける。通知は他のサービスに任せる。責務が別れていていい感じそう。
prometheusのクエリに追加できるのはメトリクス名。
# HELP python_gc_objects_collected_total Objects collected during gc
# TYPE python_gc_objects_collected_total counter
python_gc_objects_collected_total{generation="0"} 396.0
python_gc_objects_collected_total{generation="1"} 0.0
python_gc_objects_collected_total{generation="2"} 0.0
# HELP python_gc_objects_uncollectable_total Uncollectable objects found during GC
# TYPE python_gc_objects_uncollectable_total counter
python_gc_objects_uncollectable_total{generation="0"} 0.0
python_gc_objects_uncollectable_total{generation="1"} 0.0
python_gc_objects_uncollectable_total{generation="2"} 0.0
# HELP python_gc_collections_total Number of times this generation was collected
# TYPE python_gc_collections_total counter
python_gc_collections_total{generation="0"} 40.0
python_gc_collections_total{generation="1"} 3.0
python_gc_collections_total{generation="2"} 0.0
# HELP python_info Python platform information
# TYPE python_info gauge
python_info{implementation="CPython",major="3",minor="10",patchlevel="12",version="3.10.12"} 1.0
# HELP process_virtual_memory_bytes Virtual memory size in bytes.
# TYPE process_virtual_memory_bytes gauge
process_virtual_memory_bytes 1.94551808e+08
# HELP process_resident_memory_bytes Resident memory size in bytes.
# TYPE process_resident_memory_bytes gauge
process_resident_memory_bytes 2.1532672e+07
# HELP process_start_time_seconds Start time of the process since unix epoch in seconds.
# TYPE process_start_time_seconds gauge
process_start_time_seconds 1.69798593778e+09
# HELP process_cpu_seconds_total Total user and system CPU time spent in seconds.
# TYPE process_cpu_seconds_total counter
process_cpu_seconds_total 0.13
# HELP process_open_fds Number of open file descriptors.
# TYPE process_open_fds gauge
process_open_fds 8.0
# HELP process_max_fds Maximum number of open file descriptors.
# TYPE process_max_fds gauge
process_max_fds 1024.0
これはPythonのクライアントライブラリのやつ。
これにたいしてこんなクエリを書ける。
python_info
こんな感じでカウンター型のメトリクスを追加できる。
カウンターはシステム内であるイベントが何回起きたのかを表す
ゲージはシステム内のスナップショットである
具体例は以下の通りらしい
- キュー内のアイテム数
- メモリーキャッシュの使用量
- アクティブなスレッド数
- レコードが最後に処理された時間
- 直近1分間の1秒あたりの平均リクエスト数
ヒストグラムはパーセンタイルを表すメトリクス?
メトリクスタイプの説明はこれが公式ドキュメントのようだ。
バケットという概念が分からん
ネイティブ・ヒストグラムという機能があるらしく、それを使うと古いヒストグラムの問題が解消されるらしい。
生成したメトリクスを利用可能にするプロセスをExpositionと呼ぶ。
PrometheusはExpositionをhttp経由で行う。/metricsのやつ。
/metricsの形式はPrometheus Text Format or OpenMetricsがある。
Batchのメトリクスを収集するためにPushgatewayという仕組みがある。
Batchは終了間際にメトリクスをPushgatewayにプッシュする。
Pushgatewayは最後にプッシュされたメトリクスを保持しておき、Prometheusはこれをスクレイプする。
PrometheusのクライアントライブラリはPrometheus以外のために、メトリクスを吐き出すことができる。
そのPrometheus以外のために吐き出す仕組みをBridgeと呼ぶ。
Parsersを使うと、Prometheus Metricsを他の監視システム(Datadog, influxDBなど)に与えることができる。こうすることで、Prometheusサーバを建てずに、Prometheusエコシステムの恩恵に預かることができる。
閑話休題
prometheus packageのドキュメントを読む。
Package prometheus is the core instrumentation package. It provides metrics primitives to instrument code for monitoring. It also offers a registry for metrics. Sub-packages allow to expose the registered metrics via HTTP (package promhttp) or push them to a Pushgateway (package push). There is also a sub-package promauto, which provides metrics constructors with automatic registration.
metricsのためのregistryを提供するって書いてあるけど、registryが何なのかは分かってない。
sub packageは以下がある。
- promhttp
- http経由(/metrics)で登録されたメトリクスを公開する
- push
- 登録されたメトリクスをPushgatewayにpushする
- Pushgatewayはバッチジョブみたいにスクレイプができないプロセスを計装するために、バッチジョブからメトリクスをpushしておける場所。乱用は禁止。
- promauto
- automatic registrationを可能とするコンストラクタを提供する
labelについて
labelは一つのメトリクスを細分化するためのもの。
http_requests_total{path="/login"}
http_requests_total{path="/logout"}
http_requests_total{path="/adduser"}
http_requests_total{path="/comment"}
http_requests_total{path="/view"}
こんな感じでhttp_requests_totalというメトリクスにpathラベルが付いており、pathラベルの値で検索することができる。
labelには
- instrumentation label
- target label
の2つがある。
前者アプリケーションの計装のため、後者はアプリケーションを特定するためのものである。
前者の具体的な例で言えば、http_response_timeメトリクスに対してpath, methodなどがある。
後者で言えば、http_response_timeメトリクスに対して、env, host, instance, pod_nameなどが考えられる。
labelを使ってEnumを表す。
例えば、server_stateというGaugeメトリクスを作り、そこに4つのラベルを付ける。
- provisioning
- running
- stopped
- terminated
それで現在の状態を表すラベルに対して1をセットし、ほかは0にする。
すると、いい感じにserver_stateを表現できる。
infoという形式でラベルが使われることもよくある。
代表例はpython_infoメトリクス。
HistogramとSummaryの話
Histograms and summaries both sample observations, typically request durations or response sizes. They track the number of observations and the sum of the observed values, allowing you to calculate the average of the observed values.
HistogramとSummaryは観測対象をサンプルする。典型的にはリクエスト処理時間とレスポンスサイズなど。HistogramとSummaryは観測対象の総計と観測値の合計を追跡する。これによって観測値の平均を計算できる。
これでリクエスト数とリクエスト処理平均時間を計測して、エンドポイントごとの平均リクエスト処理時間とか出せるわけだ。
リクエスト処理時間の合計 / リクエスト数の総計 = 平均リクエスト処理時間みたいな感じ。
Note that the number of observations (showing up in Prometheus as a time series with a _count suffix) is inherently a counter (as described above, it only goes up). The sum of observations (showing up as a time series with a _sum suffix) behaves like a counter, too, as long as there are no negative observations.
観測対象の数(Prometheusでは_count接尾辞を持つ時系列として表示される)は、本質的にカウンタであることに注意してください(上記のように、それは上がるだけです)。観測値(_sum接尾辞を持つ時系列として表示される)も、負のオブザベーションがない限り、カウンターのように振る舞います。
つまり、countとsumはcountでしかない!ってことっぽい。
You might have an SLO to serve 95% of requests within 300ms. In that case, configure a histogram to have a bucket with an upper limit of 0.3 seconds. You can then directly express the relative amount of requests served within 300ms and easily alert if the value drops below 0.95. The following expression calculates it by job for the requests served in the last 5 minutes. The request durations were collected with a histogram called http_request_duration_seconds.
95%のリクエストが300ms内で提供できるというSLOを持っている場合。
0.3secを上限としたバケットを持つヒストグラムを設定する。
そうすることで、300ms以内に提供されたリクエストの相対的な量を直接表せて、もし0.95を下回ったときはすぐにアラート出せる。
次の式は5分以内に提供されたリクエストによって95%tileのリクエスト処理時間を計算する。
リクエスト処理時間は http_request_duration_seconds と呼ばれるヒストグラムで集計される。
バケットっていう概念がいまいちわかってない。これは使えば分かりそう。