Goの学習に関する雑多なメモ
- w3c
- official getting started
- Tour of Go
-
exercism on Go~syllabus~
- 昔、Elixirをチョロっと書いたことがある。めちゃくちゃ体験が良かったのでGoでもやってみる。
- exercism on Go~exercises except syllabus~
- Effective Go
- 実用Go言語
-
go design patterns
- どうせ英語でしょ?って思ったらまさかの日本語でびっくり。助かる、、、。
- Go言語による並行処理
- https://github.com/bxcodec/go-clean-arch
- https://github.com/zhashkevych/go-clean-architecture
-
Goなら分かるシステムプログラミング第2版
- 前々から読みたかったが、Go分からんから諦めてた&普通のLinuxプログラミングや詳解Unixプログラミング(積ん読)と被るから後回しにしてたが、楽しそうだし、書きながらGoを勉強したいからやってみる。
- Go Web Examples
- build-web-application-with-go
-
Go Brain Teaser
- Rust版もあるらしい。
-
Go言語による分散サービス
- gRPCとk8sを使って分散サービスを作る話。目次見たけどめちゃくちゃ面白そう。
w3cを読んだ所感は以下の通り。
- 噂通り仕様が少ない感じする。どのgetting startedや入門書も分量が少ない。だからこそ、設計力や超基本的なアルゴリズム力?が必要そう。
- Linterがバカ早く感じる。
- 変数の代入で
:=が何なのか今まで気になっていたが、型推論させるよっていうやつだった。 - 全体的に噂通りCからメモリ管理をなくした?みたいな?感じする。なくしたというか、GCに任せた。
- Rustよりも楽に速いコードが書けそう。よくGC使ってるからゴニョゴニョ、、みたいな話があるが、そこまで極めたときに考えれば良いし、Webの世界でパフォーマンスが出ない原因は98%、SQLの問題な気がする。しらんけど。
- Rustは特に文字列の扱いが大変。文字列型だけでも3つ4つあった気がする。Goは1つしかないからここでの苦労はなさそう。
- 初期化されてない変数にはデフォルト値が入るのが何か独特な感じがした。Ruby,JS,TS,Elixir,Rustはそういう仕様ない(よね?)。
- 配列の定義の仕方が何か独特。
- 配列はmutableなのか?imutableなのか?見た感じimutalbeっぽい。
- imutableでsliceがRustでいうVectorみたいな感じっぽい。RustにもSliceあった気がするけど、にわかなのでわかってない。
-
Note: The '...' after slice2 is necessary when appending the elements of one slice to another.って書いてあるけど、...ってなんだろう。- spread演算子的なやつかな?
- truthyやfalseyは存在しない。
- if/else/else if/switchがある。
- 文らしい。式であってほしかった。Rust,Ruby,Elixirは式、TS,JSは文。
- よくあるfor文しかないと聞いていたが、rangeキーワードっていうのがあるらしい。これは便利そう。
- key,value形式のデータ構造はMap。定義の仕方は独特。
- mapにアクセスしたときの返り値がval, okなのが独特。okはbool。
この先読んだ方が良さそうなもの、読んでみたいもの
- ORMはどんな感じか
- GraphQL周りがどうなっているのか
- Serverの話
- 可能なら今まで読むのを諦めたGoでできているOSSを読んでみたい
- 探せばかなり有名なOSSたくさんある。cockroachdb,docker,k8sとか。ただ使ったことのある有名所OSSはないかも、、、?dbとかコンテナ周りはコードが分かっても、そもそも難しいからよく分からん。
Goなら分かるシステムプログラミング読んだ所感
- デバッガー何使うのか知っておきたい
- 本の中ではこれを使っていた。https://github.com/go-delve/delve
- 良さげな本だけど、今の自分だとちょっとGoにもシステムプログラミングにも慣れてなさすぎて理解することが多く感じる。ので、違うものを読む。
getting-startedにはかなり続きがあったので、そっちを読む。
メモ。
- goのコードはpackageでまとめられており、packageはmoduleにまとめられている。
- package内の関数の可視性が関数名の命名ルールによって決まっている
- 大文字から始まる関数はexported function、小文字からのやつは違う。
- applicationとして実行されるコードはmain packageでなければならない。
- sliceのブログらしい
- goにはinitというプログラム起動時に実行される特別な関数がある、詳しくは以下。
- mapに関するブログらしい
- goのモジュールに関するブログ
- 公式のブログがなんか良い。なんというか、goのbest practicesをまとめている感じがする。分からんけど。
Tour of Goの所感
- goがどうして変数名の後ろに型名を書くのか?について書かれたブログ
- Named return value、独特な仕様だなと。
// x,yは関数の最初で定義した変数とみなされる。
// つまり、xとyというint型の変数を定義し、それを返り値として使うってこと。
func split(sum int) (x, y int) {
x = sum * 4 / 9
y = sum - x
return
}
個人的にはこっちのほうが読みやすいけど、コミュニティ的にはどうなんだろう。
package main
import "fmt"
func split(sum int) (int, int) {
x := sum * 4 / 9
y := sum - x
return x, y
}
func main() {
fmt.Println(split(17))
}
- type castはよくある感じ。TSと近い感じがする。
- defer statementはなんか独特。deferへ渡した関数の実行が呼び出し元の関数がreturnされるまで遅延される。
package main
import "fmt"
func main() {
defer fmt.Println("world")
fmt.Println("hello")
}
// => hello
// => world
// と表示される。
- deferはスタックされる。つまり、後に入れたものが先に出される(LIFO)。
- deferのブログはこちら
- &変数でその変数のアドレス(オペランド)へのポインタを引き出す。
var p int;
fmt.Println(&p)
// => 0xc000018030
みたいな感じ。
- dereferencingは*pってやる。
var p int;
fmt.Println(&p)
// => 0xc000018030
p = 10
i := &p
fmt.Println(*i)
// ↑dereference
// => 10
- 1つ目のコードはpに10を代入し、変数pのアドレスをiに代入している。2つ目のコードはpに10を、iにも10を代入している。
p := 10
i := &p
fmt.Println(p, *i)
p := 10
i := p
fmt.Println(p, i)
- スライスは配列の参照。なので、配列から作ったスライスを変更すると、元となった配列も変更される。
- スライスのゼロ値はnil。nilはlength,capacityともに0であり、要素を何も持たない。空のスライスみたいな方が幸せだったのではと思った。分からんけど。
Tour of goの所感2
- Map、RubyでいうHash。
- この例で「structと似ているが、mapにはkeyが必須」と説明されていて、わかりやすかった。Vertex構造体にはキーが存在しないが、mapにはキーが存在する。
package main
import "fmt"
type Vertex struct {
Lat, Long float64
}
var m = map[string]Vertex{
"Bell Labs": Vertex{
40.68433, -74.39967,
},
"Google": Vertex{
37.42202, -122.08408,
},
}
func main() {
fmt.Println(m)
}
- 関数は値。
Tour of Go所感3
- ポインタは考え方は他の言語と大差ない気がする。他の言語(てか、Cしか知らん)のポインタに全然造形がないので、分からんが。
- https://go-tour-jp.appspot.com/methods/5 これの挙動が変わるのは当然では?と思った。
- レシーバをポインタとして解釈する場合がある。レシーバの属性を変更する場合とそうじゃない場合で使い分けるのか??
- 書いてあった。
- ひとつは、メソッドがレシーバが指す先の変数を変更するためです。
- ふたつに、メソッドの呼び出し毎に変数のコピーを避けるためです。 例えば、レシーバが大きな構造体である場合に効率的です。
- 書いてあった。
- interfaceもそんな違和感ない。この辺はCleanArchitectureのサンプル読んだら色々と分かりそう。
- goではこんな感じでnilガードするのが普通らしい。
type T struct {
S string
}
func (t *T) M() {
if t == nil {
fmt.Println("<nil>")
return
}
fmt.Println(t.S)
}
- 空のインターフェイスという概念がある。要するにany型。
- type assertionが何をしてるのかよく分からん。具体的には14行目がfalseを返すのに、17行目がどうしてpanicになるのか分からん。
- type assertionの返り値を2つとも使えばpanicは起きない、1つしか使わないと起きるってことらしい。
-
そうでなければ、 ok は偽(false)になり、 t は型 T のゼロ値になり panic は起きません。この文章はそういう意味っぽい。
実用go言語の雑な所感
他言語経験者がよりGoらしいプログラムを書くための本。
ちょこちょこ読み進めてた。
構造体の埋め込みはなんかすごい。
OOP?で言うところの委譲っぽい機能なのかな?と思った。
type Book struct {
title string
}
type OreillyBook struct {
Book *Book
page int
}
ob := &OreillyBook{&Book{title: "hogehoge"}, page: 210}
ob.title => hogehoge
みたいにOreillyBook構造体に埋め込まれたBook構造体にアクセスできる。OreillyBook構造体が処理をBook構造体に委譲してるように見える。これってメソッドでもできるのかな?
タグを使って構造体にメタデータを埋め込む節もすごかった。
よく構造体でJSONのデータを構造体にマッピングすることができると書かれている。
type Hoge strcut {
fuga string `json: "fuga"`
}
// {"fuga": "happy birthday"}みたいなjsonがある時に
// &Hoge{fuga: "happy birtyday"} というGoの構造体に変換できる
が、これ以外にもValidatorやhtml formに関するものもある。便利そう。
構造体のタグはreflectパッケージ周りで実現されているので、その辺を読めば良さそう。
ストラテジーパターンについて学ぶ。
githubにgoで実装するデザインパターン集みたいなのがあったのと、本の中ではhttputil.ReverseProxy構造体が紹介されている。
3章構造体を読んだ。
難しいオブジェクト指向っぽく書ける、制限付きでっていうのが良いところなのかなと思った。
これを上手く使って実装していけると楽しそう。
xerrorsライブラリ、便利そう。Go2ではエラーのスタックトレースが出せるらしいが、今は出せない。
これ使えば出せるらしい。めちゃ便利じゃん。
exercism(syllabus)解いてく中で得た所感
- switchはstatement、文。jsと同じ。これは嫌い。
- Rustで言うところのshadowingはないのか?これができないと、例えばarrayからsliceを作る時に2つの変数が必要になってしまう気がしてめんどくさい。
- ふと思ったけど、sliceやstruct、arrayを操作する関数がほとんどないの、衝撃。
- sliceをcopyする時にコピー先のcapacityがコピー元のlengthより小さい場合、コピーができない。できないのは良いんだが、何もエラーが出ない。まじか???
- time.Parse、まじかって感じがした。format文字列の作成に関して癖がありすぎではw
- よくRubyは書きやすいが、読みづらい。Goは書きづらいが、読みやすい。っていう言説を見るが書いているとよく分かる。Rubyだったら秒でできることがGoだとできない。が、上から下まで読めばそのpackageで何をしているのか分かる。Rubyはメタプログラミングや継承、委譲などでどこに何が書いてあるのかバラバラだし、その命名が上手じゃない場合、全然何をやっているのかわからず、複数のファイルを見る必要がある。
- errorインターフェイスのErrorメソッドのレシーバがどうしてpointer receiverなのか?
- 変数名が短すぎる、意味がわからないときがあって、辛い。Goの変数名は短くっていう文化、嫌い。そもそもRubyでもindexをiと略すのはあんまり好きじゃなかったから、宗派の問題な気がするけど。
- syllabusに従うのは、gorutineとgenerics以外の基本的な書き方とかを理解するのにはもってこい。syllabus以外のexerciseはこれからやっていく。
exercism(syllabus以外のexercise)解いてく中で得た所感
- sort libraryの使い方が全然わからない。あとで調べる。
- float64からuint64へのtype conversionで躓いた。具体的にはこのコメントアウトされたコードがint64の最大値を返してくる。2 ** 64 -1はuint64の最大値と等しいはずだが、どこかで問題があるっぽい。
go-clean-archのコードリーディング&改造備忘録
このリポジトリはGolangでCleanArchitectureを実装した一例。
結構スター数が多い、仕様がシンプルそうなので、リーディングと改造に適していそうだと思ったので、採用した。
ここではその備忘録を書いていく。
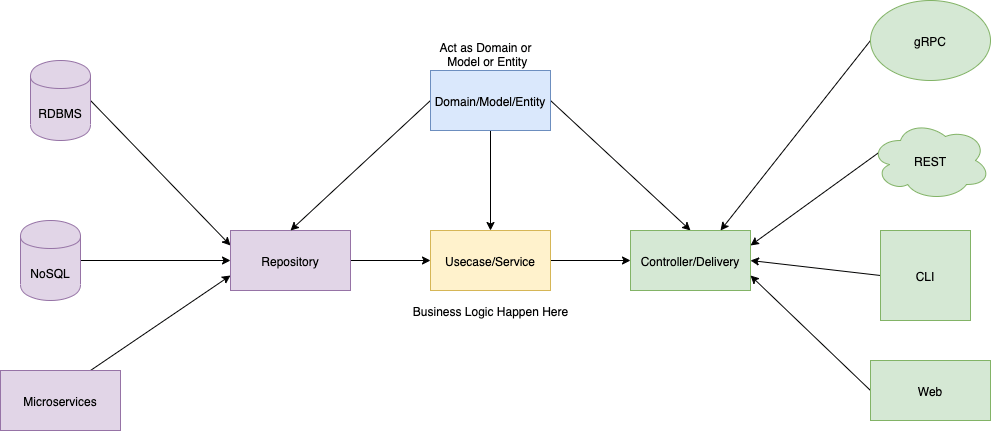
その前にこれが全体感。これはリポジトリに入ってた画像。
まず、app/main.goがエントリーポイントっぽい。このファイルがコンパイルされてバイナリーになっている。
読んでみると、article_hander.goに定義されている関数が呼ばれている。
名前の通りarticleに関するリクエストを扱っている。
article/delivery/http/article_handler.goはarticle/usecase/*.goに定義されている依存している。usecaseはdomain modelやrepositoryを使ってbusiness logicを組み立てるレイヤーとなっているっぽい。
article_handler.goを読んでいくと、↓のコードがある。
// NewArticleHandler will initialize the articles/ resources endpoint
func NewArticleHandler(e *echo.Echo, us domain.ArticleUsecase) {
handler := &ArticleHandler{
AUsecase: us,
}
e.GET("/articles", handler.FetchArticle)
e.POST("/articles", handler.Store)
e.GET("/articles/:id", handler.GetByID)
e.DELETE("/articles/:id", handler.Delete)
}
// FetchArticle will fetch the article based on given params
func (a *ArticleHandler) FetchArticle(c echo.Context) error {
numS := c.QueryParam("num")
num, _ := strconv.Atoi(numS)
cursor := c.QueryParam("cursor")
ctx := c.Request().Context()
listAr, nextCursor, err := a.AUsecase.Fetch(ctx, cursor, int64(num))
if err != nil {
return c.JSON(getStatusCode(err), ResponseError{Message: err.Error()})
}
c.Response().Header().Set(`X-Cursor`, nextCursor)
return c.JSON(http.StatusOK, listAr)
}
ArticleHandlerっていう構造体に4つのメソッドが定義されている。この構造体はUsecaseに依存している。
またこれらのメソッドはクエリパラメータの値を取得したり、response headerに値を付け加えたり、usecaseに定義されたメソッドを呼び出してロジックを実行、その結果をクライアントに返している。
echoを使ったプロジェクトを読むのは初めてだが、このコードを読むだけでこのAPIがカーソル型のページネーションが実装されているのが分かるし、どういうjsonとstatus codeを返しているのか分かる。シンプルで読みやすい。
Fetchメソッドはarticle/usecase/article_usecase.goに定義されている。また、ArticleUsecase構造体のinterfaceはdomain/article.goに定義されている。
domain/article.goには他にArticle構造体、ArticleRepository interfaceが定義されている。
このアプリケーションがArticleに関するどういうロジック、データ永続化、取得のロジックを持っているのか、インターフェイスを見れば分かるのは良いところだなと思った。
ドメインオブジェクトのロジックなどはここに書くのかなと思った。
ArticleUsecase構造体のFetchメソッド内ではArticleRepo構造体を使ってdomain.Article構造体を生成している。UsecaseではRepositoryの裏側がどうなっているのか?(mysqlなのかpostgresqlなのか、redisなのか)はわからないし、分かるべきではない。し、どういう取得クエリが実行されるのか意識する必要がないようになっている。
interfaceを見て、何が行われるのかプログラマが分かるようになっているのが大事そう。
articleUsecase#fillAuthorDetailsが全然わからない。わからないのは
- errgroup
- gorutine
-
domain.Author{}このコード
の3つ。これが分かれば色々と理解できそう。
全体感まとめ。
clean architectureなどは結局「モジュールの依存関係の流れを一定にすること」「モジュールの依存をインターフェイスを通して行うこと」を実現することで変更容易性を保つためのソフトウェアの実装/設計思想、手法という理解。
このプロジェクトは↑の図の通りに各ドメインに各レイヤーがあり、レイヤー間の依存は画像のとおりになっている。もっと大きなシステムになったら全然違ったレイヤーが追加されるが、それはその時に考えるべきもの。
gqlgenに関する雑多なメモ
gqlgenとは
gqlgen is a Go library for building GraphQL servers without any fuss.
GraphQL Serverをスムーズに作るためのGo製ライブラリ。
特徴は以下の3つ。
gqlgen is based on a Schema first approach — You get to Define your API using the GraphQL Schema Definition Language.
gqlgen prioritizes Type safety — You should never see map[string]interface{} here.
gqlgen enables Codegen — We generate the boring bits, so you can focus on building your app quickly.
- gqlgenはSchema first appoachに準ずる。つまり、GraphQL SDLを使ってAPIを定義する。
- gqlgenは型安全を優先する。つまり、
map[string]interface{}を見ることはない。 - gqlgenはコードの自動生成を可能とする。つまり、テンプレート的なコードを自動生成し、すばやくユーザのアプリを作ることを助ける。
graphql-rubyはSchema Firstではなく、Code firstだった。
なので、ruby→schemaという感じだった。が、Schema firstだと、schema→golangという流れになる。はず。
チュートリアルをやっていく。
まず、githubにあるQuickStartをやっていく。
からのgetting startedをやっていく。
進める中で以下がわかった。
- フローとしては、Schemaを書く、generateコマンドを実行する、Schemaに従って生成されたコード編集する、っていうのが基本形。ただし、typeのfieldをResolverで解決したい場合、gqlgen.ymlを書くことでそのように自動生成できる。
- Schemaから生成されたモデル(構造体)にjsonホニャララという文字があるが、これはgolangが構造体でjsonを扱えるようにしているとのこと。すごい。
その他メモ
dataloaderパターンの解説記事、一番上に出てきたのがProduction Ready GraphQLの著者の記事だった。
-
https://xuorig.medium.com/the-graphql-dataloader-pattern-visualized-3064a00f319f
dataloaderは何回読んでも分からないからたくさん動かして、たくさんソースコードを読むしかない。 - APQ(Automatic Persited Queries)という仕組みでパフォーマンス改善ができる。が、Client側でも対応が必要。
- https://www.apollographql.com/docs/apollo-server/performance/apq/
- getリクエストを使うとかcdnを使うとかredisを使うとか色々な実装パターンがあるっぽい。
- エラーメッセージの追加はgraphql.Errorをいい感じに呼び出すだけ。簡単。
- panic handlerという機能があり、これを使うとpanicしたときにユーザにいい感じにエラーメッセージを返せる。
The panic handler
There is also a panic handler, called whenever a panic happens to gracefully return a message to the user before stopping parsing. This is a good spot to notify your bug tracker and send a custom message to the >user. Any errors returned from here will also go through the error presenter.
お題
- golang + net/http + gqlgenでInstagram cloneを作る
要件
- フロントは適当
- バックエンドはできる限りカリカリにチューニング
- ユーザは特定の投稿を閲覧できる
- ログインユーザは投稿を作成できる
- ログインユーザはフォローしたユーザの投稿一覧を閲覧できる
- ログインユーザは他のユーザをフォローできる
- ログインユーザは投稿にコメントできる
とか。
Query Complexityに関するメモ
gqlgenのextensionパッケージでComplexityLimit, ComplexiyStatという構造体があり、これらをうまく使うことで以下を実現できる(そう)。
- APMでOperation(Query / Mutation / Subscription)ごとにComplexityを一覧できる、アラートを飛ばせる
- Complexityが一定を超えたらエラーとする
- Query / Mutation、一つずつ独自にLimitを設定する
gqlgen(もしかしたらGraphQL全体で?)ではリクエストを受け取りレスポンスを返すまでに、いくつかのライフタイムを定義しており、ライフライムごとに関数が実行できるようになっている。
以下は現時点でhandlerパッケージに記載されているコメント。
// HandlerExtension adds functionality to the http handler. See the list of possible hook points below
// Its important to understand the lifecycle of a graphql request and the terminology we use in gqlgen
// before working with these
//
// +--- REQUEST POST /graphql --------------------------------------------+
// | +- OPERATION query OpName { viewer { name } } -----------------------+ |
// | | RESPONSE { "data": { "viewer": { "name": "bob" } } } | |
// | +- OPERATION subscription OpName2 { chat { message } } --------------+ |
// | | RESPONSE { "data": { "chat": { "message": "hello" } } } | |
// | | RESPONSE { "data": { "chat": { "message": "byee" } } } | |
// | +--------------------------------------------------------------------+ |
// +------------------------------------------------------------------------+
HandlerExtension interface {
// ExtensionName should be a CamelCase string version of the extension which may be shown in stats and logging.
ExtensionName() string
// Validate is called when adding an extension to the server, it allows validation against the servers schema.
Validate(schema ExecutableSchema) error
}
// OperationParameterMutator is called before creating a request context. allows manipulating the raw query
// on the way in.
OperationParameterMutator interface {
MutateOperationParameters(ctx context.Context, request *RawParams) *gqlerror.Error
}
// OperationContextMutator is called after creating the request context, but before executing the root resolver.
OperationContextMutator interface {
MutateOperationContext(ctx context.Context, rc *OperationContext) *gqlerror.Error
}
// OperationInterceptor is called for each incoming query, for basic requests the writer will be invoked once,
// for subscriptions it will be invoked multiple times.
OperationInterceptor interface {
InterceptOperation(ctx context.Context, next OperationHandler) ResponseHandler
}
// ResponseInterceptor is called around each graphql operation response. This can be called many times for a single
// operation the case of subscriptions.
ResponseInterceptor interface {
InterceptResponse(ctx context.Context, next ResponseHandler) *Response
}
RootFieldInterceptor interface {
InterceptRootField(ctx context.Context, next RootResolver) Marshaler
}
// FieldInterceptor called around each field
FieldInterceptor interface {
InterceptField(ctx context.Context, next Resolver) (res interface{}, err error)
}
// Transport provides support for different wire level encodings of graphql requests, eg Form, Get, Post, Websocket
Transport interface {
Supports(r *http.Request) bool
Do(w http.ResponseWriter, r *http.Request, exec GraphExecutor)
}
現時点、存在するインタフェースは以下の通り。それぞれコメントをdeepl + ちょびっと修正して翻訳する。
-
HandlerExtension
- HandlerExtension は http ハンドラに機能を追加します。以下の可能なフックポイントのリストを参照してください。Graphql のリクエストのライフサイクルと、gqlgen で使用する用語を理解することが重要です。
- ExtensionName は、統計やログに表示される拡張機能のキャメルケース文字列である必要があります。
- Validate は、拡張機能をサーバーに追加するときに呼び出され、サーバーのスキーマを検証します。
-
OperationParameterMutator
- OperationParameterMutator はリクエストコンテキストを作成する前にコールされ、生のクエリを操作することができます。
-
OperationContextMutator
- OperationContextMutatorは、リクエストコンテキストを作成した後、ルートリゾルバを実行する前に呼び出される。
-
OperationInterceptor
- OperationInterceptor は、受信するクエリごとに呼び出されます。基本的なリクエストの場合はライター(the writer / おそらく関数のこと?)が一度だけ呼び出され、サブスクリプションの場合は複数回呼び出されます。
-
ResponseInterceptor
- ResponseInterceptorは、graphqlの各Operationに対するレスポンスで呼び出されます。これは、サブスクリプションの場合、ひとつのOperationに対して何度も呼び出されることがあります。
-
RootFieldInterceptor
- 説明なし
-
FieldInterceptor
- FieldInterceptorは各フィールド毎に呼び出される
-
Transport
- Transportは、Form、Get、Post、Websocket など、さまざまなワイヤレベルのエンコーディングに対応しています。
complexityの計算方法はcomplexity/complexity.goに書いてあるが、これを読み解くよりはcomplexity/complexity_test.goを読んだ方がイメージが湧くと思う。かなり分かりやすい。
golangのパッケージ管理がわけわかめなので、メモしていく。
まず、getting startedのCall code in an external packageという章に書いてあるとおり、
- pkg.go.dev で使いたいパッケージを探す
- コードの中でimportする
- go mod tidyコマンドを実行する
で済む。
RubyでいうGemfile.lockがgo.modファイルっぽい。
ドキュメントにはだいたいこんな流れと書いてある。
- Locate useful packages on pkg.go.dev.
- Import the packages you want in your code.
- Add your code to a module for dependency tracking (if it isn’t in a module already). See Enabling dependency tracking
- Add external packages as dependencies so you can manage them.
- Upgrade or downgrade dependency versions as needed over time.
go get commandで特定のバージョンの外部パッケージを追加できる。
この辺詳しく知るにはgo.modファイルのリファレンスを読む必要がある。