Cloud Monitoring で認証付き Cloud Run の外形監視を行う
概要
認証付きの Cloud Run が外部からアクセス可能な状態かどうかを監視するのに使える Google Cloud サービスを調査した。
その結果、「Cloud Monitoring 稼働時間チェック」が良さそうと考え使い方をまとめた。
前提
次点として、Cloud Scheduler で定期的にヘルスチェックエンドポイントを叩いて、失敗した時の監査ログを検知してアラートを出す方法もある。
しかし、複数リージョンでのチェックやICMP Pingsが無いなど外形監視の機能としては少し弱い。なので、そのような使い方は Cloud Monitoring の稼働時間チェックがどうしても採用できない場合に検討するのが良い。
Cloud Run は Google Cloud のサービスであり、それを監視するのに同じ Google Cloud を使うと Google Cloud 全体が落ちていたら監視できない事になるが、監視トリガーが動いている全リージョンが一斉に落ちることは考えづらく確率も低いと考える。
外形監視とは
外形監視とは、Webアプリケーションに対して外部のネットワークから実際のユーザと同様の方法でアクセスし、異常がないか監視する手法である。
ユーザが体感するWebサイトのパフォーマンスや、不具合などをリアルタイムで把握することを目的としている。
Cloud Monitoring 稼働時間チェックの作成
Google Cloud コンソール上で稼働時間チェックを作成する方法を紹介する(参考:ドキュメント)。
Google Cloud コンソールで「Cloud Monitoring」 > 左メニューの「稼働時間チェック」に移動して、「稼働時間チェックを作成」をクリックし、以下のように必要事項を入力する。
ターゲット
 |
|---|
 |
|---|
- リソースの種類・Cloud Run Service
- リソースの種類には Cloud Run Service を選択する。これが Cloud Run Service を対象とする時に設定する種類(参考:Google Cloud ブログ)
- Cloud Run Service には監視対象の Cloud Run Service を選択する。
- Regions
- 最低3つを選択する必要があり、リクエスト呼び出し回数はリージョン数との掛け算で決まる。
- ICMP Pings
- 以下理由により設定するのが良い。
- 失敗した公開稼働時間チェックをトラブルシューティングする際、ping がネットワーク接続の問題やアプリケーションのタイムアウトなどによって引き起こされる障害を区別するのに役立つ。(参考:ドキュメント)
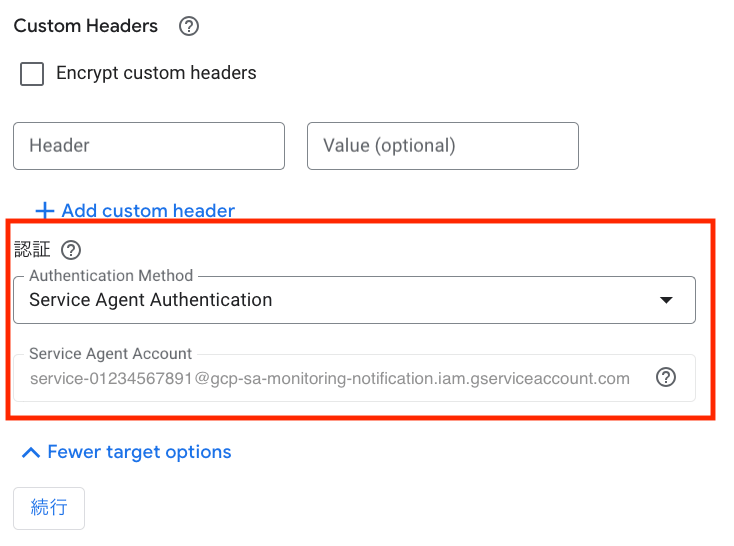
- 認証
- Service Agent Authentication を選択し、Service Agent Account には Cloud Monitoringサービスエージェントが設定される。
- このサービスエージェントは
run.routes.invoke権限を含むroles/monitoring.notificationServiceAgentロールを持っており、Cloud Runに対してHTTPリクエストを呼び出すことができる(参考:ドキュメント)。
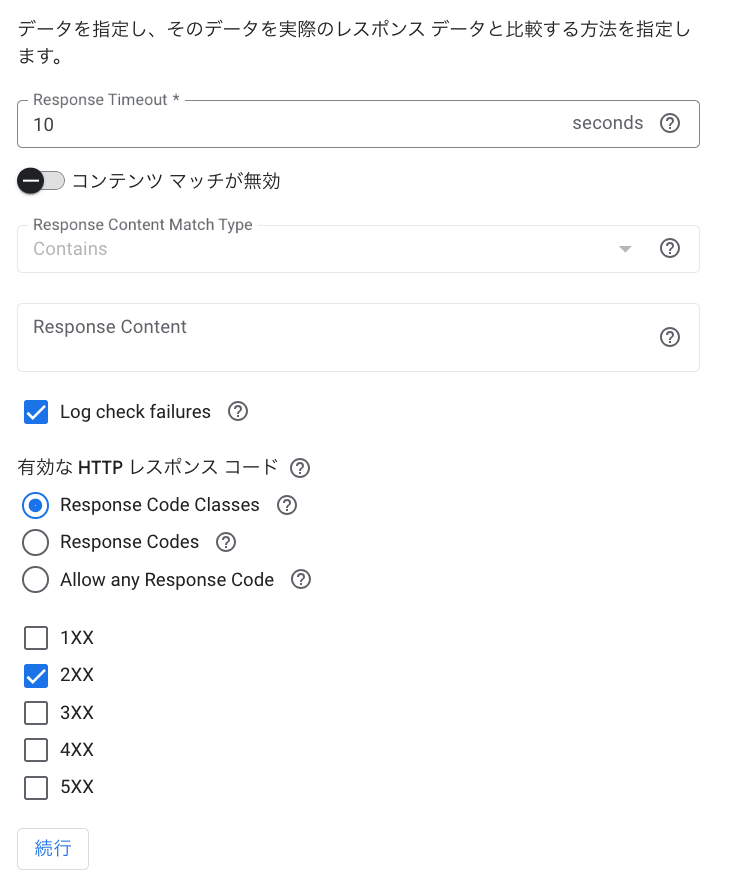
レスポンスの検証
 |
|---|
- 「Response Codes」を選択することで特定のレスポンスコード(ex. 200)に絞って検証することも可能。
アラートと通知
 |
|---|
- 稼働時間チェックが失敗した時に通知されるようにアラートを作成する。
- デフォルトでは、2 つ以上のリージョンが 1 分以上の稼働時間チェックの失敗を報告したときに通知が送信される。これは、作成されたアラートポリシーのデフォルト設定に再テストウィンドウが1minで設定されているため。
- 通知先にはメールやSlackチャンネルを選択できる。ここではメール通知を指定した。
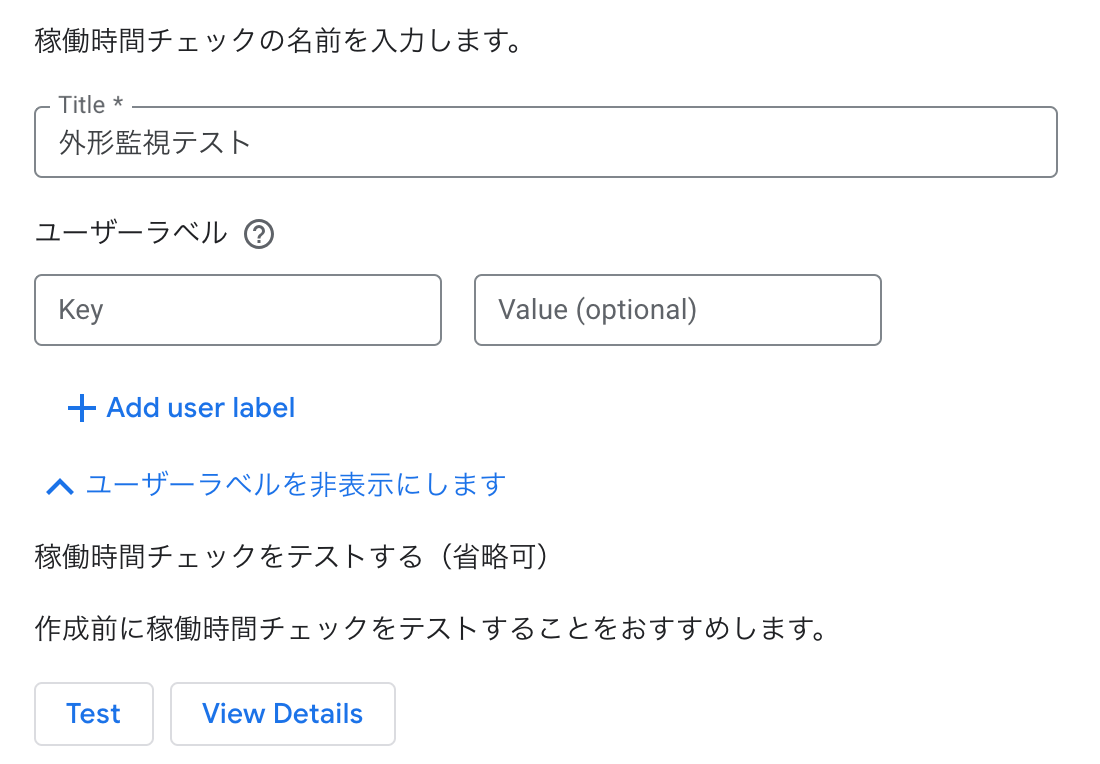
確認
 |
|---|
「Test」ボタンを押すと、対象の Cloud Run サービスのエンドポイントに対してチェックを実行し、結果の成否が表示される。
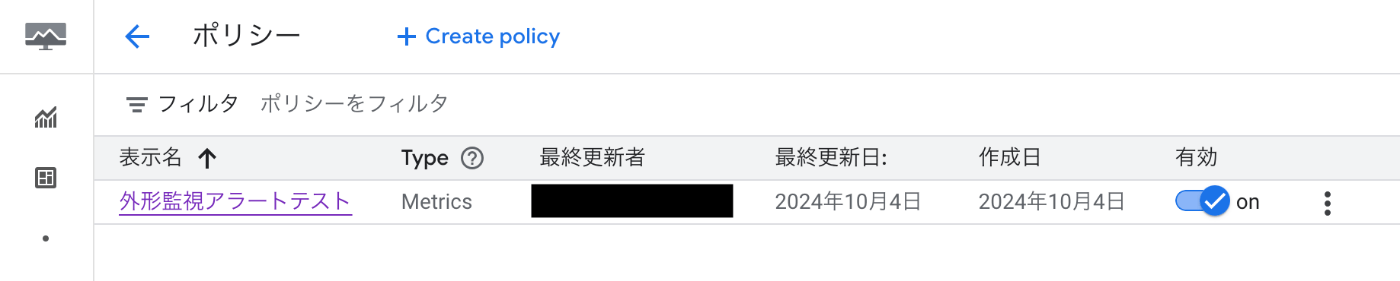
以上のようにして稼働時間チェックを作成すると、指定したアラートポリシーも作成される。
 |
|---|
動作を確認する
稼働時間チェックを作成すると、指定した Path(/healthcheck)に対してHTTPリクエストが送信される。「Check Frequency」を 1min、「Regions」を3つ選択したので1分間に3回リクエストが送信される設定になっている。
実際の Cloud Run ログである次の画像を見てみると、8:00台に3回リクエストを受信し、8:01台にも3回りクエストを受信しており、設定通り1分間に3回リクエストが送信されていることが分かる。
 |
|---|
次に、稼働時間チェックが失敗する動きを見るために、/healthcheck がステータスコード 500 を返すようにコードを変更する。チェックに失敗すると、次のことが起こる。
- リクエストエラーのログが出力される
- アラートが通知される
- インシデントが開かれる
リクエストエラーのログが出力される
Cloud Run ログを見ると、チェックに失敗した時の500エラーログとPingsログがセットで出る。Pingログはチェックが失敗した時だけ出るようになっており、アプリケーションへのリクエストの成否とPingの成否を分けて考えることができる。
 |
|---|
アラートが通知される
メール通知では、次のようなアラートが通知される。「VIEW INCIDENT」を開くとインシデントの詳細を確認できる。
 |
|---|
 |
|---|
インシデントが作成される
インシデントとは、アラートポリシーの条件が満たされたときの記録であり、条件が満たされると Cloud Monitoring はインシデントを開き、通知を送信する。
インシデントが開かれたら問題の修正を開始する。ここでは、/healthcheck が200ステータスコードを返すように修正する。
修正が反映されると稼働時間チェックが通るようになり、稼働時間チェックが正常状態に戻ったことを知らせるログが出力される。
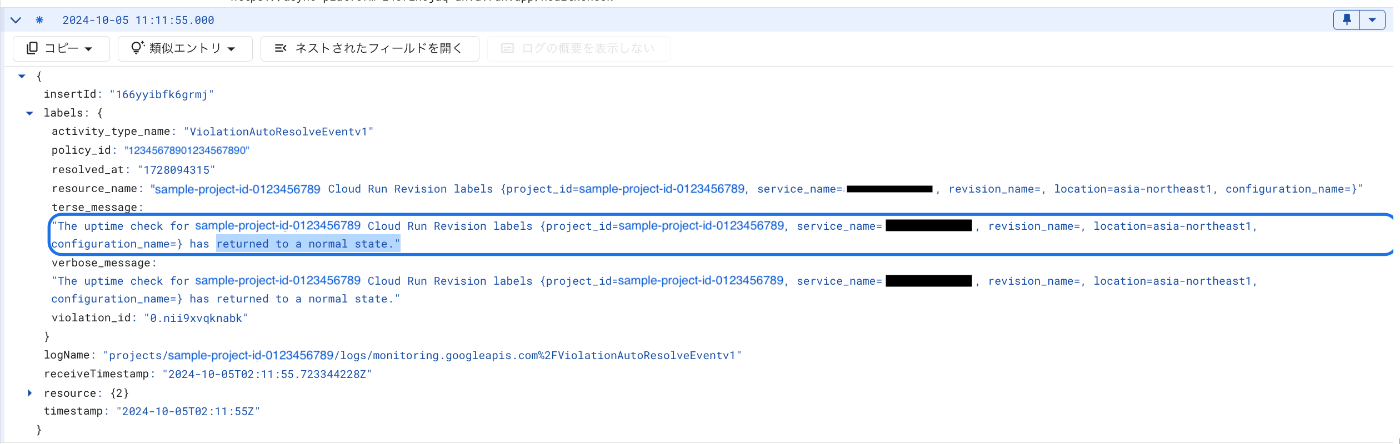 |
|---|
それに伴って、自動的にインシデントがクローズされ、その旨を知らせる通知が送られる。
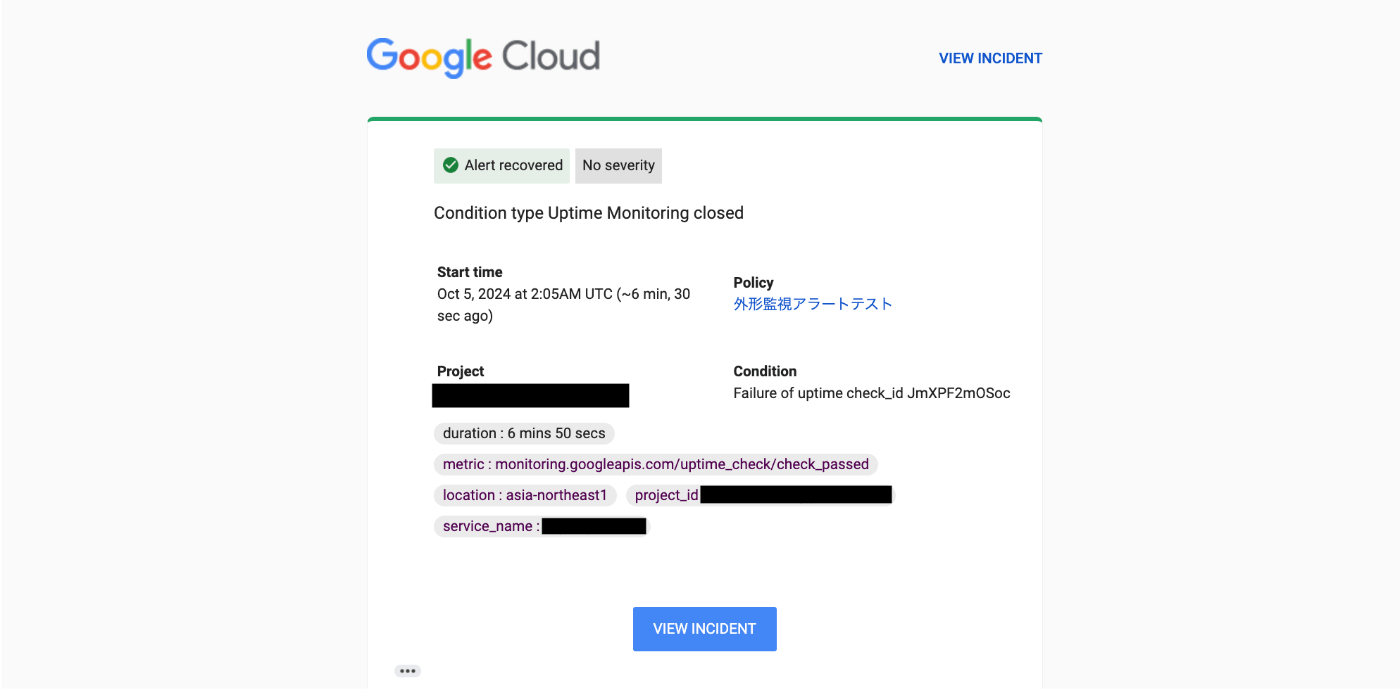 |
|---|
Cloud Monitoring の料金
稼働時間チェックの実行料金は、1,000 回当たり$0.30。
毎月の無料枠は、Google Cloud プロジェクトあたり 100 万回の実行。
(Cloud Monitoring の料金概要)
今回の設定では1min間に3回実行されるので、ひと月(31日)あたり133,920回となり、無料枠範囲内に収まる。(1min * 3回 * 60 * 24 * 31 = 133,920回)
Cloud Run の料金
稼働時間チェックを行うことで Cloud Run へのリクエスト数が増えるため、それによって料金がどれくらい増えるか調べた。
Cloud Run の料金体系はCPUを常に割り当てるか、割り当てないかで2パターンある(料金表)。
CPUを常に割り当てない方式を前提にすると、発生する料金は3つある。
- CPU割り当て時間あたりの料金:$0.00002400 / vCPU-second
- メモリ割り当て時間あたりの料金:$0.00000250 / GiB-second
- リクエスト数に応じた料金:$0.40 / million requests
こちらのツールを使ったところ、$0.04/ month となった。
- 算出根拠データの備考
- CPU・Memoery:2CPU, 2GiB
- Number of requests per month (million):
3回/min * 60min * 24h *31日 * 0.000001 = 0.133920 ≒ 0.14 millinon/month - Execution time per request (ms):稼働時間チェックが
/healthcheckを叩いた時のレスポンスタイムは実測値を平均して5msに設定 - Number of concurrent request per instance:3Regionから送信されるリクエストは別々のタイミングのため、リクエストを個別に処理する想定(最も料金がかかるケース)としている。
- Committed use discounts:設定せず
備考
チェックが失敗している状態で長時間放置しても、アラートは初回のみで繰り返し飛んでこない。
繰り返し通知を構成すると、アラートポリシーの特定の通知チャネルに同じ通知を再送信できるみたい。
Discussion