拡張・保守しやすいStreamlitアプリのための構成検討
はじめに
今更ながら「Pythonのみで爆速にWebアプリが開発できる」というStreamlitを使ってみました。
実際に使ってみると、
- 確かにすぐできる!
- 見た目も洒落てる!
- あれ、イベントと状態の管理が追いにくくなってきた...
- あれ、拡張しにくくなってきた...
- 気づけばスパゲッティの完成…
と、こんな感じになり、構成を検討してみました。
ある程度形になってきたので、まだ3日も触っていない若輩者ですが、記事にまとめて発信したいと思います。
留意点
いきなり話の骨を折りますが、前提として
- アプリとして短命ならばStreamlitでも良い
- シンプルなものであればStreamlitでも良い
- フロントをゴリゴリ頑張るならStreamlitは使うべきではない
というのが私の個人的な見解です。
そもそもStreamlitは「機械学習エンジニアやデータサイエンティストが、時間をかけずにデータの確認・検証・デモ用UIを作成できる」ことを主眼に置いていると思っています。
そのようなもので、運用だの保守だのを頑張ったところで、コストが見合わない可能性があります。
とはいえ、プログラムは得てして改修が繰り返されます。
そしてStreamlitは仕様上、増改築を繰り返せばコードが読みづらく、保守しづらさを助長させる気がしたので、何かしらの対策は必要かなと思っています。
題材:個人向けの日別作業記録アプリ
日別の作業記録アプリをつくってみたので、これを基に説明していこうと思います。

アプリのざっくりした仕様は以下の通りです。
- 日付別にどの作業をどれだけ実施したか記録できる
- いまから作業開始&終わったら停止
- 過去分の手動登録、修正
- 作業内容をカテゴリ別に登録できる
- 日本語,英語を切り替えられる
- DBは現状SQLite
大したものではないですね。
(余談)モチベーション
※私が働いている会社の日報って、「X時間○○をやった」っていう入力をしなくちゃいけなくて、これが地味に面倒なんですよね。
「XX:XX-XX:XXに○○をやった」って入力できた方が楽なので、それをしたくて作ってみました。
要点まとめ
先に要点をまとめたほうが分かりやすい気がするので、書いておきます。
- データ登録・取得はStorageクラス経由で行う
- 各イベント処理やデータ制御はMediatorクラスが一括して担当
- ダッシュボードのパーツごとに.pyファイルにまとめる
- エントリポイントはStorage, Mediatorのインスタンス化とパーツの配置のみ
ファイル・ディレクトリ構成
主要部分のディレクトリ構成は以下の通りです。
.
├── main.py # エントリポイント
└── work_report
├── colleagues # ダッシュボードのパーツ群
│ ├── date_selection.py
│ ├── __init__.py
│ ├── ...
│ └── working_hours_schedule.py
│
├── config.py # コンフィグ管理
├── database # DBアクセス系
│ ├── database.py
│ ├── __init__.py
│ └── models.py
│
├── __init__.py
├── locale.py # 言語定義など
├── logic.py # ビジネスロジック
├── mediator.py # イベント・データ取扱いの仲介者
├── session_storage.py # データ一覧
└── view_models.py # View Model
上記にあげた要点を噛み砕きながら見ていきます。
その1:データ登録・取得はStorageクラス経由で行う
Streamlitでは、Session State機能を使うことで、イベント発火等により再実行された後にも状態を保存しておくことができます。
キーに対して値を1:1で保持できます。
ブラウザのSessionStorageみたいな感じですかね。
# Initialization
if 'key' not in st.session_state:
st.session_state['key'] = 'value'
# Session State also supports attribute based syntax
if 'key' not in st.session_state:
st.session_state.key = 'value'
# Read
st.write(st.session_state.key)
# Outputs: value
各ウィジェットの値も、ウィジェットのkeyをkeyとしてSession State上で管理されます。
st.text_input("Your name", key="name")
# This exists now:
st.session_state.name
簡単ですね。
ただし簡単が故に、どこからでも呼び出せてどこからでも変更できてどこからでも登録できてしまいます。
ということで、機能に関連するSession Stateのkeyを集約したクラスを作りましょう。
それが今回でいうところの、work_report.session_storage.SessionStorageクラスです。
ごちゃごちゃしてますが、要点は以下の2つです。
-
st.session_stateと各キーをプロパティに持つ - DBのデータ保持
2つめは後ほど説明しますので、いまはわからなくて良いです。
その2:各イベント処理やデータ制御はMediatorクラスが一括して担当
「各ウィジェットはSessionStorageクラスからデータを取り出す」と書きましたが、データの更新や制御、イベント発火時の処理はどこで行うのでしょうか。
SessionStorageで管理するデータは、実際にユーザが扱うデータだけでなく、ボタンの有効・無効などのデータも含んでいます。
これを、単純に各ウィジェットの定義場所で記述してしまうと、各ウィジェットが密に結合してしまいます。
例えば、今回の「ジョブ/カテゴリ登録」機能を具体例にしてみましょう。
この機能は、
- ラジオボタンで
jobを選択し、かつ、チェックボックスか外された場合、categoryのセレクトボックスの選択ができる - ラジオボタンで
categoryが選択されている場合、セレクトボックスもチェックボックスも押下不可 - ジョブ名もしくはカテゴリ名を入力するとボタンが押下可能
という制御がされています。
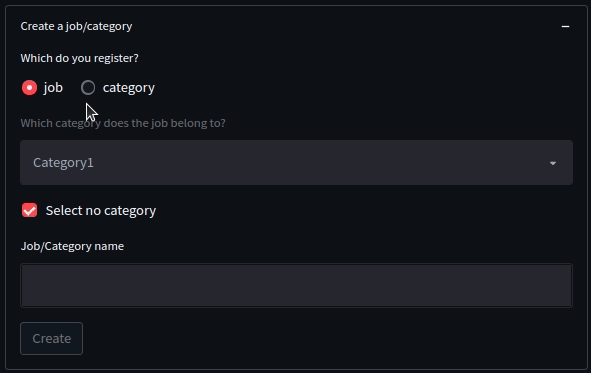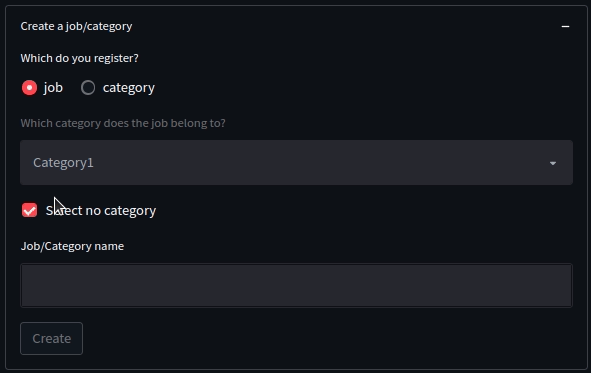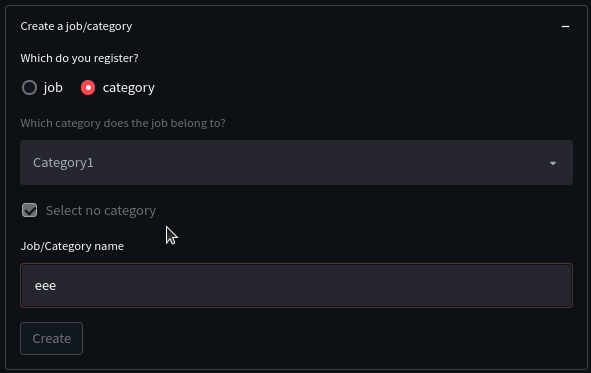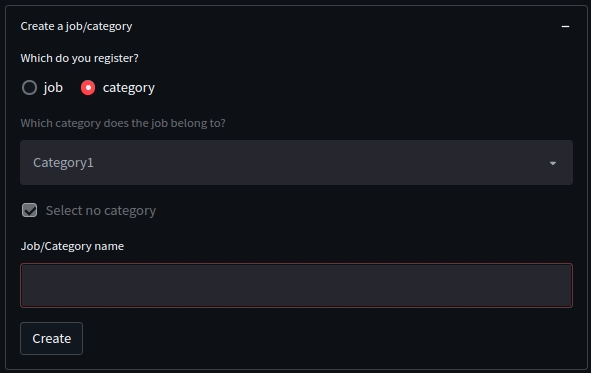
文章にしてみると簡単ですが、地味にややこしいですよね。
- ラジオで
jobが選択されているか - ラジオで
jobが選択されている場合、チェックボックスが外されているか - セレクトボックスにはそもそも選択可能なカテゴリがあるか
- etc
これを各ウィジェットに書くとおそらく読みたくなくなるコードが完成するでしょう。
そこで、この辺を一括で制御してくれるクラスを作成します。
それがMediatorクラスです。
Mediatorクラスの主な役割は以下の通りです。
-
SessionStorageクラスの値を参照し、各ウィジェットの状態制御を行う - 各ウィジェットで発生したイベントを基に制御を行う
- DBからデータを取得して
SessionStorageクラスに保持する
SessionStorageクラスの値を参照し、各ウィジェットの状態制御を行う
上にあげた「ジョブ/カテゴリ登録」のウィジェット制御している部分が以下になります。
内容がまとまっていて、見通しが良いですね。
各ウィジェットで発生したイベントを基に制御を行う
こちらも「ジョブ/カテゴリ登録」で作成イベントが発生したときの処理を貼っておきます。
SessionStorageから値を取り出し、ジョブを作成すべきなのか、カテゴリを作成すべきなのかを判断し、実際に該当する処理をおこないます。
DBからデータを取得してSessionStorageクラスに保持する
ここはちょっと今後も要検討の部分です。
SessionStorageクラスが直接DBにデータを取りに行くのは変な話です。
かといって、Mediatorクラスがデータを保持するのもなんか違う気がしたので、SessionStorageのプロパティを更新するようにしました。
その3:ダッシュボードのパーツごとに.pyファイルにまとめる
これももう「ジョブ/カテゴリ登録」で説明しちゃいましょう。
- ウィジェット配置
- ウィジェットのkey, value, disabled, optionsなどは全て
SessionStorageクラスから取得 - イベント発生時のコールバックは
Mediatorクラスのメソッドを指定
シンプルですね。
その4:エントリポイントはStorage, Mediatorのインスタンス化とパーツの配置
最後にエントリポイントであるmain.pyを見てみましょう。
-
SessionStorage,Mediatorのインスタンス化 - (streamlitの初期化)
- 各パーツの配置
説明が後になってしまいましたが、今回はst.columns()を使ってグリッド構成にしています。
(再掲)要点まとめ
まとめを再掲しておきます。
- データ登録・取得はStorageクラス経由で行う
- 各イベント処理やデータ制御はMediatorクラスが一括して担当
- ダッシュボードのパーツごとに.pyファイルにまとめる
- エントリポイントはStorage, Mediatorのインスタンス化とパーツの配置
おわりに
以上、今回検討した構成についてざっとですが見ていきました。
書きなぐりで、細かい説明などできていなくて申し訳ないです。
まだ荒削りではありますが、割と責任の分離ができているのではないかと思います。
今回の構成にすることで、例えば以下のようなことが比較的容易にできるかと思います。
- 新機能の追加
- ダッシュボードパーツの配置変更
- DBMSの切替
- 認証機能の追加
- コンフィグファイル読み込みによるダッシュボードカスタマイズ
参考になれば幸いです。
ここが分かりにくい、もっと良い方法があるなど、ご指摘大歓迎です。
P.S.
最後に不満を一つ書くと、StreamlitはUIのテストがしにくいです、pytestでできたりするとより便利なんですけどねー…
Discussion