【夏休みの自由研究】自作言語でFizzBuzzを動かす!
はじめに
夏休みというと自由研究の季節ですが、プログラミング言語を自作してみるのも面白いか、と思い以下の動画を作ってみました。
私自身も十年ぶりくらいにプログラミング言語を実装してみて、だいぶ忘れていて部分もあったので整理を兼ねてサマリを記事にしておこうと思います。
なお、コードは以下にコミットしています。良ければ参考にしてください。
この記事では簡単なプログラミング言語の座学的な所から始めて、FizzBuzzやフィボナッチ数列を実行できるような言語にまで育てていきます。
プログラミング言語と処理系
まずは基本的なプログラミング言語に関わる概念をおさらいをします。動画では第一回、第四回の一部でも解説をしています。
高級言語と低級言語
プログラミング言語は英語や日本語のような自然言語とは異なり、誰かがコンピュータの振る舞いを記述するために作り出した人工言語です。大きく分けて高級言語と低級言語に分けることが出来ます。
高級言語は人間にわかりやすい、いわゆる我々がプログラミング言語と認識しているもの、低級言語はアセンブラとも呼ばれ機械語と1:1に原則なるような言語です。つまりC言語もJavaもRustもRubyも高級言語です。
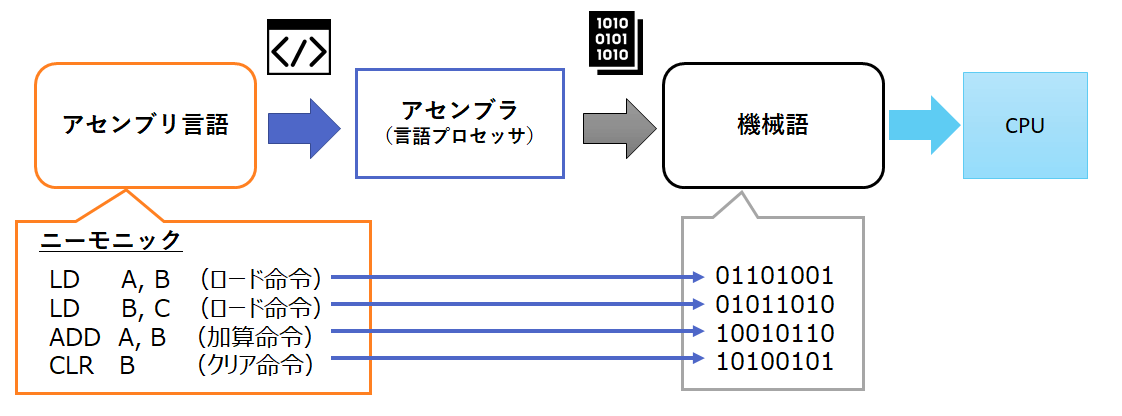
ref: https://itmanabi.com/programming-language/
上記の図が分かり易いですが、高級言語(高水準言語)では普通に四則演算の式を表現出来ますが、低級言語(低水準言語/アセンブラ)ではロード命令などCPUの振る舞いを意識したコードにする必要があります。CPUに対して完全な最適化を行う余地がある代わりに人間の負担がとても大きそうですね。ちなみにCPUの気持ちに寄り添いたい人は触りレベルですが以下の動画で解説してるので良ければ見てみてください。
- 【基本情報で学ぼう!】 第2回/前編 プロセッサのためのチューリングマシン
- 【基本情報で学ぼう!】 第2回/中編 プロセッサのためのBrainF*ck
- 【基本情報で学ぼう!】 第2回/後編 プロセッサのためのレジスタマシン
処理系の種類
プログラミング言語には実装となる処理系がいくつかあります。一つの言語が複数の処理系を持っている事も良くあります。処理系は大きく分けると以下の4つの方式に分類できます。
- コンパイラ(e.g. C, Go, Rust)
- インタプリタ(e.g. PHP, Ruby, Python, JS)
- VM/中間言語方式(e.g. Java, .NET, Ruby, JS)
- トランスパイラ(e.g. TypeScript, CoffeeScript)
コンパイラはCやGoで採用されてることが多く、GCCやLLVMを利用したものが特に有名です。プログラミング言語を機械語の実行可能ファイルに変換して、動作します。インタプリタは所謂スクリプト言語で良く使われ、プログラミング言語を実行可能ファイルには変換せずインタプリタ自身で実行します。VM方式は一度バイナリであるバイトコードにコンパイルし、それをVirtual Machine(VM) 上でインタプリタ的に実行します。Javaや.NETが有名ですが、RubyやJSも近年は性能向上のために採用しておりYARVやV8などが主流です。未確認ですがPHPやPythonも同様の流れと思います。トランスパイラは少し毛色が違ってTypeScriptとJSのように、ある言語を別な言語に変換する技術です。以前から存在しますがAltJSの文脈で改めて目立つようになったと思います。トランスパイラ以外の3つを図にすると以下のようになります。
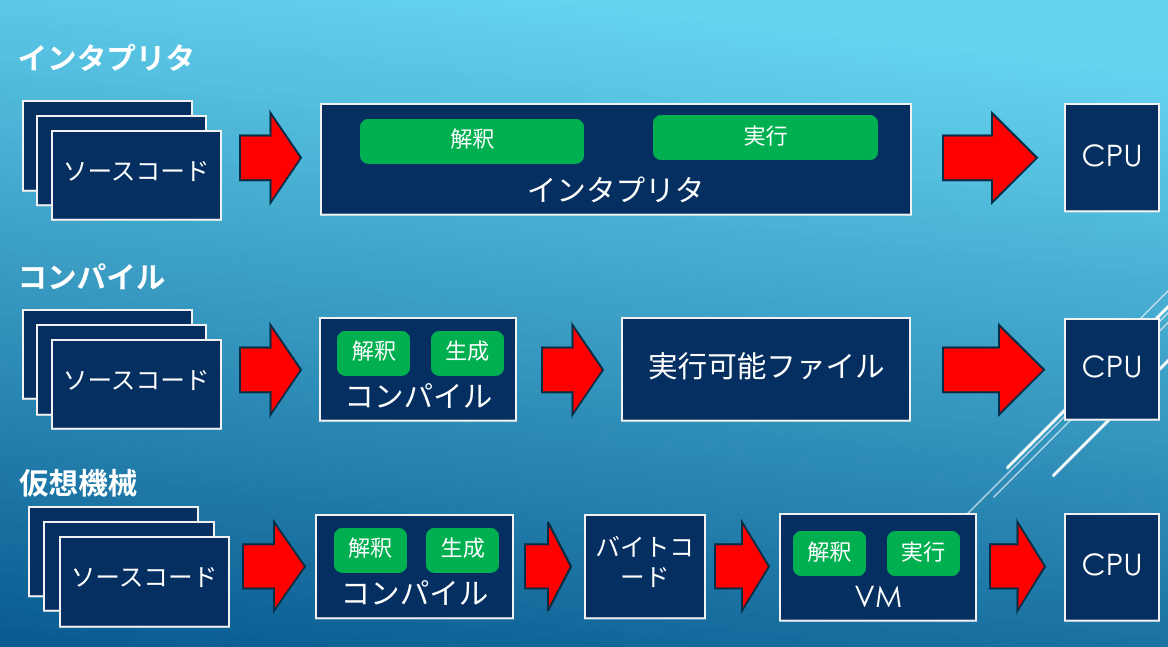
なお、上記の図では「コンパイル」とだけしていますが、実際は実行可能ファイルを作るには「リンク」という作業も必要になりますが、ここでは広義の意味で「コンパイル」としています。また、コンパイラもGCCやLLVMでは最適化やクロスコンパイルの容易性のために中間表現(IR)を経由することが多いですが、今回は割愛します。
インタプリタの構成要素
コンパイラやVM方式は機械語への理解やVMの実装など多くの要素が絡むので、今回はプログラミング言語の実装ということにテーマを絞るために最も簡単なインタプリタを作成します。
さて、それではプログラミング言語の処理系はどのように実装すれば良いのでしょうか? インタプリタの場合は以下のようなステップになります。
- 字句解析: ソースコードを単語に分解
- 構文解析: 文法を検証し抽象構文木を作成
- 意味解析: 実行できるかのチェック
- 評価: 実行
字句解析器はテキストを読み込んで単語に切り出して渡します。レキシカルアナライザともScannerとも呼ばれます。

構文解析器はパーサーとも言われプログラミング言語の文法をチェックするとともに、抽象構文木(Abstract Syntax Tree: AST)というデータ構造に変換します。
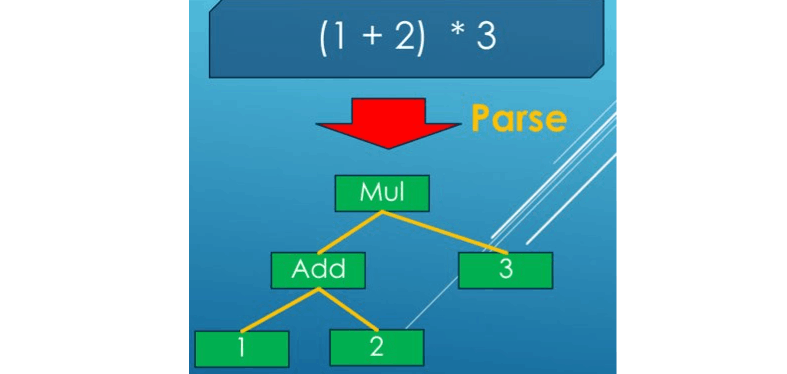
ASTはLISPのS式と同様に [命令, 引数...] をノードとする木構造になっているため、上から単純に処理をしていくこと出来るので以降の処理を書くのが簡単になります。。
意味解析(Semantic Analysis) ですが、こちらは「文法上は正しいが実行時に問題になるもの」をASTを解析することで確認します。代表的なものは以下です。
- 変数参照
- 型チェック
例えば 「x = a + 1」 という式があった場合、文法上は問題なかったとしても「aという変数が存在している」「aは数値である」「xは数値を代入可能である」など、文法上は分からないチェックがいくつもあります。こうした意味をチェックするのが意味解析の目的となります。
最後に評価(Evaluate) ですが、これはインタプリタでは実行となります。VM方式やコンパイル型ではここが コード生成 になりますが、それより前のステップは基本的に同様になります。
字句解析 -> 構文解析 -> 意味解析 -> (最適化) -> 評価 の順でプログラミング言語は処理されるとモデル化する事が出来ます。ただ、全ての実装が上記のフェーズ毎のコンポーネントに分かれているとは限らず、今回は私も意味解析を評価のタイミングと合わせて実施したりもしていました。このあたりは実装に依存します。
BNF (バッカス・ナウア記法)
BNFはプログラミング言語の文法を表現するための記法です。構文解析で文法チェックをすると言いましたが、そのためにはまず文法を正確に記述する必要があります。例えば以下のような自作言語のコードを考えてみます。
fn main(){
println("Hello World");
}
こちら、なんとなくHello Worldだという事はわかりますが、
例えば型は省略されているのでしょうか? それとも記述できないのでしょうか? あるいはダブルクォーテーションではなくシングルクォーテーションを利用したり、セミコロンを省略することはできるでしょうか? ifの書き方はどうなるでしょうか? 文なのか式なのか、そこも気になりますよね? こうした様々な疑問に答えるためにサンプルコードを大量に書くと言うだけではキリがありません。そこで有効なのがBNFとその拡張であるEBNFのようなメタ言語です。例「|(パイプ)」でorなどを表現し、ルールを再帰的に辿る事で全体を表現します。以下はWikipediaから持ってきたBFN自身のBNFです。
<syntax> ::= <rule> | <rule> <syntax>
<rule> ::= <opt-whitespace> "<" <rule-name> ">" <opt-whitespace> "::="
<opt-whitespace> <expression> <line-end>
<opt-whitespace> ::= " " <opt-whitespace> | "" ……… "" は空文字列を表す
<expression> ::= <list> | <list> "|" <expression>
<line-end> ::= <opt-whitespace> <eol> | <line-end> <line-end>
<list> ::= <term> | <term> <opt-whitespace> <list>
<term> ::= <literal> | "<" <rule-name> ">"
<literal> ::= '"' <text> '"' | "'" <text> "'"
BNFを用いることでプログラミング言語の文法を明確に表現することが出来ます。また、今回は扱いませんがYaccやANTLRを用いてBNFを食わせる事で自動的に構文解析器を生成するパーサージェネレータ と呼ばれるツールもあります。
本記事の中でも実際の文法サンプルを扱っていくので、そちらを見ていくのが分かりやすいと思いますので、まずは「こういった物があるんだ」と思ってもらえれば良いと思います。
数式パーサ、電卓を作る
さて、概要の説明が終わったので次章からは実際のコードを見ていきたいと思います。とはいえ、いきなりプログラミング言語を実装するのも少し大変なので、まずは数式パーサと評価器、つまり電卓を作成します。とても簡単なサンプルですが必要なエッセンスが結構詰まっていて最初の教材としては最適です。動画でいえば2回目や3回目の解説が同じ内容になっています。
用語整理
電卓を作る前に少し数式に関連した用語整理させてください。数式、すなわちexpressionは複数の項(term)からなり、termは因子(factor)からなり、factorは数値(number)からなる、という構造に実はなっています。
- expression: 式, 加算演算子(+-)と項
- term: 項, 乗算演算子(*/)と因子
- factor: 因子, ()と式と数値
- number: 数値
- operator: 演算子
図にするとこんな感じです。1 + 2がexpressionなのは少し不思議に思いますが、expressionは加算演算子とtermからなりtermはfactorからなり、factorはnumberからなるので、再帰的に辿る事で<number> + <number>もexpressionとして表現出来る、という事ですね。

ちなみに先程話たBNF風[1]の記載をすると以下のようになります。
expr := <term> | <exp> + <term> | <exp> - <term>
term := <factor> | <term> * <factor> | <term> / <factor>
factor := (<expr>) | <number>
number : = [0-9]*
簡単な四則演算を行う
まずは簡単な四則演算を行える電卓を作ります。デモアプリケーションを動かす場合はindex.htmlの以下のimportを./modules/02/interpriter.jsを参照するようにしてください。
<script type="module">
import * as Interpriter from './modules/02/interpriter.js';
const bnt_run = document.querySelector("#bnt-run");
const btn_clear = document.querySelector("#btn-clear");
例えば 「1 + 2」 のような2つの値からなる式を実行する素朴なコードは以下のようになります。
ピックアップして詳しく見ていきましょう。Scanner、つまり字句解析器はスペース区切りでテキストを分割し、peekで現在の値を、nextでpostionを進めて次の値を返すようにしています。
export class Scanner {
constructor(text) {
this.tokens = text.trim().split(/ /);
this.pos = 0;
}
peek() {
return this.tokens[this.pos];
}
next() {
this.pos += 1;
return this.tokens[this.pos];
}
}
本体であるevaluate以下のようにScannerから値を順に取得しています。構文エラーが無い限りはnumber operator numberの順番出来ますから、以下のようにそれぞれを取得します。
const num1 = parseInt(sc.peek());
const op = sc.next();
const num2 = parseInt(sc.next());
そして、以下のようにオペレータに応じた処理を実行します。簡単ですね。
switch (op) {
case "+":
r = num1 + num2;
break;
case "-":
r = num1 - num2;
break;
case "*":
r = num1 * num2;
break;
case "/":
r = num1 / num2;
break;
default:
r = undefined;
}
ただ、このコードには以下の2つの課題があります。
- 3つ以上の値に対応出来ない
- 掛け算や括弧の優先順位に対応できない
1に関してはループを上手く作ればできそうな気もしますが、2の演算子の優先順位は少し面倒そうです。何も考えすに実装すると 「1 + 2 * 3」 が7ではなく9になってしまうと思います。括弧や掛け算があった時に前の処理に戻ってやり直す、みたいな作りにする必要があり複雑ですよね。そこで再帰下降パーサーを実装することで、この問題を解決したパーサを作ろうと思います。
数式向け再帰下降パーサーを実装する
再帰下降パーサとはBNF等で記された文法構造にそって関数を定義することで文法を解析していく構文解析器です。比較的簡単に実装出来るので今回はこちらを用いた数式パーサを作ります。
再掲になりますが数式のBNF風[1:1]の記述は以下のようになります。
expr := <term> | <exp> + <term> | <exp> - <term>
term := <factor> | <term> * <factor> | <term> / <factor>
factor := (<expr>) | <number>
number : = [0-9]*
exprは加算演算子とtermからなり、termは乗算演算子とfactorからなり、factorは括弧+exprまたはnumberからなり、これを再帰的に辿っていきます。これによってexprに含まれる加算演算子よりtermに含まれる乗算演算子が、乗算演算子よりfactorに含まれる括弧が優先出来ますよね。
以下のサンプルコードで上記のBNFに対する再帰下降パーサーを実装しています。
具体的に見ていきましょう。以下のようにexprの中で、Scannerが空になるまで次の値を読み込み続けます。これで2つ以上の値の演算が出来ます。まずtermを呼んでいるので加算演算子よりも乗算演算子が優先して実行されます。そして、ループの中でexprの最初と演算子の次の値としてtermを呼んでいます。
const expr = () => {
let x = term();
for (let token = sc.peek(); sc.is_not_end(); token = sc.peek()) {
switch (token) {
case "+":
x += term();
break;
...
termは以下のようにほぼ同じ形式で加算演算子に対して処理をしています。こちらもまず最初にfactorを呼んでいるのでそちらが優先されます。
const term = () => {
let x = factor();
for (let token = sc.peek(); sc.is_not_end(); token = sc.peek()) {
switch (token) {
case "*":
sc.next();
x *= factor()
...
factorは以下のように括弧があればexprを実行し、なければnumberを返しています。
const factor = () => {
if (sc.peek() === "(") {
sc.next();
const r = expr();
if (sc.peek() === ")") {
sc.next();
}
return r;
}
return number();
};
numberは終端値として以下のように別な関数を呼び出すことなく、数値を返しています。
const number = () => {
const r = sc.peek();
sc.next();
return parseInt(r);
};
このようにBNFに対応する関数を同じように呼んでいくだけで、文法をパース出来るのが再帰下降パーサーの強みです。
また、先程は単にスペース区切りで分割していたScannerですが、実際には必ずしもスペースで区切られているとは限りません。そのためScannerを以下のように改造して1文字ずつ読み込み、スペースがあったときはスキップしたり、数値など特別な連続した値のときはループを回す実装にしています。以下のコードを参考にしてください。
ASTに変換してから実行する
上記の実装は実行と解析を同時に行っていますが、ParserとEvaluatorに実装を分けてから実行するように修正してみます。
全体を制御するインタプリタは以下のようになります。
export function evaluate(text) {
const sc = new Scanner(text);
const ast = Parser.parse(sc);
return new Evaluator().apply(ast).toString();
}
ScannerをParserに渡して、Parserが生成したASTをEvaluatorに渡してるとてもシンプルな構造ですね? Parserの具体的なコードを見てみましょう。
const expr = () => {
let _expr = term();
while (match("ADD_OP")) {
switch (take("ADD_OP").value) {
case "+":
_expr = [$("add"), _expr, term()];
break;
case "-":
_expr = [$("sub"), _expr, term()];
break;
}
}
return _expr;
};
基本的には先ほどと同じですが、+演算子などで直接計算しない代わりに、配列を返す形に変形させています。termやfactorなども同様の修正をしています。これによって以下のような木構造のデータを作成する事が出来ます。
作成したASTは以下のようなEvaluator#apply関数に渡し、再帰的にshift関数で先頭のノードを取得していき、オペコード毎の処理を行います。ASTに変換した後であれば演算子優先順位などを気にする必要は無いので、評価の部分がとてもスッキリしますね。
export class Evaluator {
apply(ast) {
const token = ast.shift();
switch (token.type) {
case "add": {
return this.apply(ast.shift()) + this.apply(ast.shift());
}
case "sub": {
return this.apply(ast.shift()) - this.apply(ast.shift());
}
case "mul": {
return this.apply(ast.shift()) * this.apply(ast.shift());
}
case "div": {
return this.apply(ast.shift()) / this.apply(ast.shift());
}
case "INT":
return token.value;
}
return "";
}
}
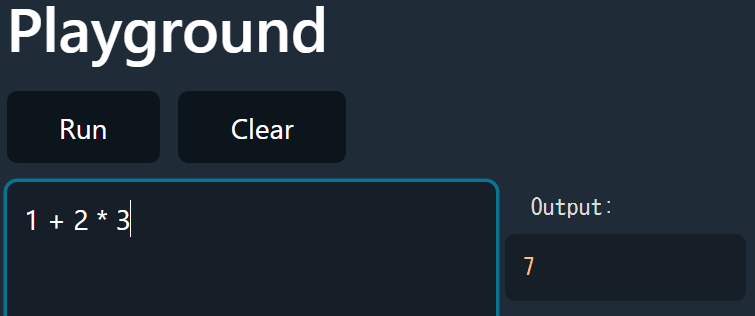
上記を実装する事で以下のように掛け算や括弧を含んだ演算をきちんと行う事が出来ます。
Hello World専用言語の実装
さて、電卓を作って基本的な構造を理解したところで、いよいよ実際にプログラミング言語を自作していきましょう! 動画では4回目で解説しています。
とはいえ、いきなり色々作るのは大変なのでまずは 「Hello Worldを実行できるだけの言語」 を作ります。つまり、以下のコードが実行できるという事ですね。
fn main(){
println("Hello World");
}
この言語のBNFっぽいもの[1:2]は以下のようになります。ほんの十行程度のとても短い定義ですね。
<program> := <funcdef>+
<funcdef> := fn <ident> '(' <funcargs> ')' { <statlist> }'
<funcargs> := <ident>(, <ident>)*
<statlist> := <statement>;(<statement>;)*
<statement> := <call_func>
<call_func> := <ident> '(' <string> ')'
<string> := "<any charactor>"
<ident> := <latter>(<latter> | <digit>)*
<latter> := [a-zA-Z]+
<digit> := [0-9]+
上記をベースに実装したコードが以下となります。
interpriter.jsは先ほどの電卓の時と全く同じ構造でいけるので、Scanner/Parser/Evaluatorの3つのモジュールを見ていきましょう。
export function evaluate(text) {
const sc = new Scanner(text);
const ast = Parser.parse(sc);
return new Evaluator().apply(ast).stdout.join("\n");
}
Scannerの構造
まずはscanner.js
です。基本的な作りは変わっていませんが、先ほどの四則演算に比べたら利用する語彙が増えてますので、サイズが増えていますがやっている事自体は変わりません。ルールに基づいて切り出した単語を後続で処理しやすいように{type:意味値, value:値}の構造でトークンとして返しています。
export class Scanner {
constructor(text) {
const tokenize = (word) => {
switch (true) {
case word == "fn":
return $("FUNCDEF", word);
case word == "(":
return $("PARENTHES_OPEN", word);
case word == ")":
return $("PARENTHES_CLOSE", word);
case word == "{":
return $("BEGIN", word);
case word == "}":
return $("END", word);
case word == ";":
return $("SEMICOLON", word);
case (/"(.*)"/).test(word):
return $("STRING", word.match(/"(.*)"/)[1]);
default:
return $("IDENT", word);
}
};
const split = (text) => {
const tokens = [];
let idx = 0;
while (idx < text.length) {
const x = text[idx];
if ((/"/).test(x)) { // scan-latter
let str = x;
idx++;
for (; (text[idx]) != '"'; idx++) {
str += text[idx];
}
str += '"';
idx++;
tokens.push(tokenize(str));
} else if ((/\d/).test(x)) { // scan-int
let num = "";
for (; (/\d/).test(text[idx]); idx++) {
num += text[idx];
}
tokens.push(tokenize(num));
} else if ((/[a-z]|[A-Z]/).test(x)) { // scan-latter
let latter = "";
for (; (/[a-z]|[A-Z]|[0-9]/).test(text[idx]); idx++) {
latter += text[idx];
}
tokens.push(tokenize(latter));
} else if (x === " " || x === "\n") { // skip
idx += 1;
} else {
tokens.push(tokenize(x));
idx += 1;
}
}
return tokens;
};
....
Parserの構造
続いてparser.jsです。こちらも数式パーサーの時と同様にBNFの定義通りに再帰的に対応する関数を呼んでいきASTを構築します。matchとtakeは今回作成したユーティリティ関数でmatchはScanner#peakをして引数で渡したトークのTypeと一致するかを確認し、takeでScanner#nextをして取得しています。
export function parse(sc) {
...略
const program = () => {
const _program = [];
while (match("FUNCDEF")) {
_program.push(funcdef());
}
return _program;
};
const funcdef = () => {
const _funcdef = [];
_funcdef.push(take("FUNCDEF"));
_funcdef.push([take("IDENT")]);
take("PARENTHES_OPEN");
_funcdef.push(funcargs());
take("PARENTHES_CLOSE");
take("BEGIN");
_funcdef.push(statlist());
take("END");
return _funcdef;
};
const funcargs = () => {
// Hello Worldでは使わないので今回は未実装
const _funcargs = [];
return _funcargs;
};
const statlist = () => {
const _statlist = [];
while (match("IDENT")) {
_statlist.push(statement());
}
return _statlist;
};
const statement = () => {
const _statement = [];
const name = take("IDENT");
_statement.push(call_func(name));
take("SEMICOLON");
return _statement;
};
const call_func = (name) => {
const _funcall = [];
_funcall.push($("call_func"));
_funcall.push([name]);
take("PARENTHES_OPEN");
_funcall.push([take("STRING")]);
take("PARENTHES_CLOSE");
return _funcall;
};
const ast = program();
return ast;
}
数式とプログラミング言語と全く見かけが異なる2つですが、同じようにパーサーが書けるのは面白いですよね。
Evaluatorの構造
最後にevaluator.jsです。こちらも電卓を作成したときとほとんど変わりません! と、言いたいところなのですが、少し新しい考え方を入れています。順を追ってみていきましょう。
以下のように定義通りに再帰的に実行してASTをトラバースしていくのは同じです。
function eval_prgram(env, ast) {
for (let i = 0; i < ast.length; i++) {
eval_funcdef(env, ast[i]);
}
}
function eval_funcdef(env, ast) {
ast.shift(); // fundef
const name = ast.shift()[0].value;
const args = ast.shift();
env.func_table[name] = () => {
eval_statementlist(env, ast.shift());
};
}
function eval_statementlist(env, ast) {
for (let i = 0; i < ast.length; i++) {
eval_statement(env, ast[i].shift());
}
}
function eval_statement(env, ast) {
const token = ast.shift();
switch (token.type) {
case "call_func": {
const name = ast.shift()[0].value;
const args = ast.shift()[0].value;
return env.func_table[name](args);
}
}
throw new Error("Unkown Error");
}
関数テーブルと関数呼び出し
追加ポイントの一つしとして 環境(env) に関数テーブルであるfunc_tableを作成している事です。今回のprintは組み込みの関数なので連想配列に直接ラムダ式を記載しています。
そして main関数 を暗黙のエントリポイントとしているので、ユーザが定義したmainを実行しようとします。なのでmainを定義しないと必然的にエラーになるのが現在の実装です。このあたりはアノテーションを付けたりとか、色々やなり方が出来ると思います。
export class Evaluator {
apply(ast) {
const env = {
func_table: {
"print": (text) => syscall_stdout(env, text),
},
stdout: [],
};
// 評価を開始
eval_prgram(env, ast);
// mainと付いている関数をエントリポイントとして実行
env.func_table["main"]();
return env;
}
}
関数定義は以下のように名前と引数を取得して、関数テーブルにラムダ式として代入しています。ブロックを取り出してeval_statementlistを実行する事でプログラミングされたことを実行する事が出来ます。
function eval_funcdef(env, ast) {
ast.shift(); // fundef
const name = ast.shift()[0].value;
const args = ast.shift();
env.func_table[name] = () => {
eval_statementlist(env, ast.shift());
};
}
関数呼び出しはeval_statementの中の処理として実行されます。今回のhello world専用言語ではBNFにも書いている通り引数は文字列一つと決まっているので、以下のように名前や引数を取得して、関数テーブルから呼び出しています。
case "call_func": {
const name = ast.shift()[0].value;
const args = ast.shift()[0].value;
return env.func_table[name](args);
}
標準出力
print関数は標準出力を呼びますのでsyscallを以下のように実装しています。
function syscall_stdout(env, text) {
env.stdout.push(text);
if (Config.is_show_console()) {
console.log(env.stdout[env.stdout.length - 1]);
}
}
見ての通り実際のOSのシステムコールを呼んでるいるわけでは無く、console.logに委譲する事で標準出力を実現しています。簡単ですね。またenvの中にstdoutという配列を用意して、そちらにも値を格納しています。こちらが直接画面に出力できるわけではないですが、デバックや他のPGからの呼び出し時に標準出力を返すために利用しています。
これでHello Worldを実行するだけの言語は完成です。デモアプリを実行すると以下のようになります。無事、Hello Worldが表示されていますね!
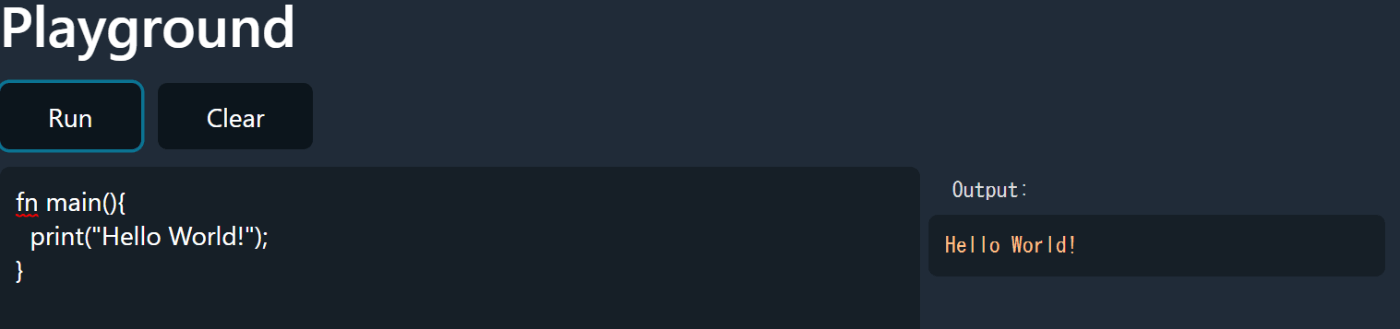
インタプリタの場合はラムダ式や関数オブジェクト等を活用して、比較的簡単に関数呼び出しが実行できるのは便利ですね。
FizzBuzzへの拡張
Hello Worldが実行できるだけとはいえ、だいぶ自作言語らしくなってきましたね! ここにifやwhile、変数定義や再帰的な関数呼び出しなどを実装して、FizzBuzzやフィボナッチ数列も実行できる本格的なプログラミング言語に育ててみましょう。動画としては第5回で解説しています。
先ほどのHello Worldではifやwhileが無いのももちろんですが、変数定義が無かったり、引数が文字列しか取れなかったり、電卓で作った四則演算がそもそも無くなっていたり、と多くの部分を簡略化していました。そこで、もう少し本格的なBNFっぽいもの[1:3]は以下のようになります。
<program> := <funcdef>+
<funcdef> := fn <ident> '(' <funcargs> ')' { <statlist> }'
<funcargs> := <ident>(, <ident>)*
<statlist> := <statement>;(<statement>;)*
<statement> := <call_func> | <call_if> | <call_while> | <assign> | <return> | <break>
<call_func> := <ident> '(' <literal>(, <literal>)*')'
<call_if> := if '('<relation>')' { <statlist> } [else (<statlist>|<call_if>]
<call_while> := while '('<relation>')' { <statlist> }
<assign> := <ident> = <expression>
<return> := return
<break> := break
<relation> := <bool> |<expression> <rel_op> <expression>
<rel_op> := > | < | == | != | <= | >=
<expression> := <expression> <add_op> <term> | <term>
<term> := <term> <mul_op> <factor> | <factor>
<factor> := <literal> | "(" <expression> ")" | <funccall>
<add_op> := + | -
<mul_op> := * | / | %
<string> := "<any charactor>"
<number> := <digit>+
<bool> := true | false
<literal> := <number> | <string> | <bool> | <ident>
<ident> := <latter>(<latter> | <digit>)*
<latter> := [a-zA-Z]
<digit> := [0-9]
基本的には先ほどのHello WorldのBNFに要素を追加しているだけです。多少技巧的な所と言えば、else ifに関しては「elseはブロック(statlist)かifを取る」と定義する事でelse ifをif定義の再帰呼出しとして表現する事でシンプルにしています。
<call_if> := if '('<relation>')' { <statlist> } [else (<statlist>|<call_if>]
こちらを実装した言語が以下となります。
ScannerやParserは増えた語彙に対応しているだけで、あまり変わっていません。一方でいくつか新しい話が入っているのがEvaluatorなので主にそちらを解説したいと思います。
関数呼び出しとスコープ
ぱっと見で大きく変わっている部分の一つがeval_statementです。元々は関数呼び出しだけだったので当然ですね。
function eval_statement(global, env, ast) {
const token = ast.shift();
switch (token.type) {
case "call_func": {
return eval_call_func(global, deep_copy(env), ast);
}
case "IF": {
return eval_if(global, env, ast);
}
case "WHILE": {
return eval_while(global, env, ast);
}
case "ASSIGN": {
const name = ast.shift()[0].value;
const value = eval_expr(global, env, ast.shift());
env.var_table[name] = value;
return env.var_table[name];
}
case "BREAK": {
throw new BreakError();
}
case "RETURN": {
env.result = eval_expr(global, env, ast.shift());
throw new ReturnError();
}
}
throw new Error("Unkown Error");
}
それでは関数呼び出しのeval_call_funcがどう変わったかを見ていきましょう。
function eval_call_func(global, env, ast) {
const name = ast.shift().value;
const args = ast.shift();
const mapped_args = args.map((t) => eval_expr(global, deep_copy(env), t));
return global.func_table[name](mapped_args);
}
元の関数呼び出しと同じく名前と引数を取って、関数テーブルを参照して実行している点は同じです。ただし、異なるポイントとしてglobalという引数が増えている事とargsを直接渡さずmapped_argsなるものに変換している部分が気になります。
まず、globalですが、これは元を辿るとapplyメソッドに実装されたもので、以前はenvとしていたものと同様です。では、envには今度は何が入ってるのでしょうか?
apply(ast) {
const global = {
func_table: {
"print": (args) => {
syscall_stdout(global, args[0]);
},
},
var_table: {},
stdout: [],
};
関数テーブルがenvの代わりにglobalという名前の連想配列に保存されましたが、envは以下のようにeval_fundefの中で、関数を定義する度にローカル変数テーブルと共に作成されています。
function eval_funcdef(global, ast) {
ast.shift(); // fundef
const name = ast.shift()[0].value;
const args = ast.shift();
global.func_table[name] = (args_values) => {
const env = {
var_table: {},
};
これを関数呼び出しの時に引数として渡してやることで、ローカルのスコープを実現する事が出来ます。もし、先ほどのようにグローバルの環境のみで変数テーブルを運用すると、いつ何処で名前がぶつかるか分からず、コーディングが非常にメンドクサイです。変数テーブルと戻り値をこうしてローカルスコープとして作る事で、再帰呼出し等を行った場合にも適切に値を返していくことが出来ます。
続いてmapped_argsです。先ほどは文字列のみを受け取る、という仕様だったのですが今回はそうしたプリミティブな値以外にも変数や式を引数として受け取る事が出来ます。そのためそれらを評価して最終的な値にしているのが以下の部分です。
const mapped_args = args.map((t) => eval_expr(global, deep_copy(env), t));
return global.func_table[name](mapped_args);
eval_exprは四則演算だけではなく、関数呼び出しや変数名の解決なども行っています。これによって最終的な値にした状態で関数テーブルの引数に渡す事が出来ます。
case "call_func": {
return eval_call_func(global, env, ast);
}
case "IDENT": {
return env.var_table[token.value];
}
case "INT":
case "STRING":
case "BOOL":
return token.value;
}
渡された値はeval_funcdefの通り、ローカル変数にマッピングしているためプログラム中で利用する事が出来るようになります。
global.func_table[name] = (args_values) => {
const env = {
var_table: {},
};
for (let i = 0; i < args.length; i++) {
env.var_table[args[i][0].value] = args_values[i];
}
if文の実装
プログラミングで欠かすことの出来ない条件分岐ですが、インタプリタの場合は実装はとてもシンプルです。以下のように単純にガード条件を取得して実際のJS側のif文で処理してやれば良いので簡単に実装する事が出来ます。また、BNFにも書いていた通り、elseの後ろはブロック(statlist)またはifなので、再帰的に呼び出す事でelse-ifをいくらでも書くことが出来ます。
function eval_if(global, env, ast) {
const guard = eval_relation(global, env, ast.shift());
const block1 = ast.shift();
const else_directive = ast.shift();
const block2 = ast.shift();
if (guard) {
eval_statementlist(global, env, block1);
} else if (else_directive) {
if (block2[0].type == "IF") {
block2.shift(); // if directive
eval_if(global, env, block2);
} else {
eval_statementlist(global, env, block2);
}
}
}
while文の実装
Whileの実装もif文と同じく実際のJS側のwhileで無限ループをさせてガード条件でbreakさせるだけです。
function eval_while(global, env, ast) {
try {
while (true) {
const cloned_ast = deep_copy(ast);
const guard = eval_relation(global, env, cloned_ast.shift());
if (!guard) {
break;
}
const block = cloned_ast.shift();
eval_statementlist(global, env, block);
}
} catch (err) {
if (!(err instanceof BreakError)) { // 例外では無く正常系。breakが投げられたら大域脱出
throw err;
}
}
}
ポイントとなるのは今までのように直接ASTを渡さずに複製を渡している事です。
const cloned_ast = deep_copy(ast);
というのも、While文の場合は当然条件がマッチする限りはループし続けるので、なにも考えずにast.shiftを繰り返していると2回目から違う部分を呼んでしまいます。それを防ぐために複製をしているわけです。本来は引数に渡すものは全部複製で良いはずですが、今回deep_copyをJSONにシリアライズしてデシリアライズするというかなり雑な作りにしているので、利用箇所を限定しています。
もう一つの工夫としてbreakの対応があります。breakやreturnというのはジャンプ命令なのですが、真面目に 「そこいうの処理は破棄する」 というコードを書くのは少し面倒です。そのため例外をGOTOのようなジャンプ命令と見立てて、breakをした時点で以下のようにBreakErrorを発行しています。
case "BREAK": {
throw new BreakError();
}
これを以下のようにwhileの外の例外で掴む事で、ジャンプ命令を実現しています。
try {
while (true) {
~ 中略
}
} catch (err) {
if (!(err instanceof BreakError)) { // 例外では無く正常系。breakが投げられたら大域脱出
throw err;
}
つまり、ここで出ている例外は異常系ではなく正常系です。returnも同様の考えて実装しています。
case "RETURN": {
env.result = eval_expr(global, env, ast.shift());
throw new ReturnError();
}
} catch (err) {
if (err instanceof ReturnError) { // 例外では無く正常系。returnが投げられたら大域脱出
return env.result;
} else {
throw err;
}
このようなジャンプ命令の疑似的な再現はちょっとダーティーハックの匂いがしますが、 いったん作ってみる という温度感であれば問題は無いと思います。
サンプルコード
上記の拡張により以下のようなサンプルコードを自作言語処理系で動かす事が出来るようになりました。FizzBuzzはもちろん、フィボナッチ数列のような再帰も動作するので、結構いろんなコードがこれだけでも記述できると思います。
こちらのREAMDEにデモアプリの動かし方も書いているので良ければ自分のS3やGithub Pages、あるいはローカル環境で試してみてください。
HelloWorld:
fn main() {
print("Hello World");
}
FizzBuzz:
fn main() {
fizzbuzz(1, 100);
}
fn fizzbuzz(start, end) {
i = start;
while(i<=100){
if(i % 15 == 0){
print("FizzBuzz");
}else if(i % 3 == 0){
print("Fizz");
}else if(i % 5 == 0){
print("Buzz");
}else {
print(i);
}
i = i + 1;
}
}
フィボナッチ数列:
fn main() {
print(fib(10));
}
fn fib(n) {
if(n == 0){
return 0;
}else if (n==1){
return 1;
}else {
return fib(n - 1) + fib(n - 2);
}
}
まとめ
今回は夏休みの自由研究というテーマで、少しいつもは作らないタイプの開発として 「プログラミング言語自体の自作」 を行ってみました。今回作ったコードはユーティリティ的な関数を含めても600行と少しという事で非常にコンパクトになっています。
$ ls -1 ./|grep -v test|xargs wc -l
19 config.js
229 evaluator.js
9 interpriter.js
230 parser.js
121 scanner.js
30 util.js
638 total
もちろん、いろんな考慮が抜けていますし、実用的な言語にするためにはもっときちんとした理論背景を押さえる必要もあると思いますが、今回の記事や動画を見て、プログラミング言語の開発が 「魔法ではなく自分で作れるもの」 と思ってもらえれば嬉しいです。自分のオリジナル言語で開発してるとかアツいですよね! ○○の言語のエコシステムは好きだけど、言語自体にはどうも馴染めない... みたいなこともあるでしょうし。
また、私自身もまだ使っては無いのですが、LLVMやGraal Trufflelのような言語実装フレームワークを用いれば、高度な処理系も比較的簡単に作る事が出来るようなので、今度時間をみつけてチャレンジしてい見たいですね。
それではHappy Hacking!
Discussion