今年の書初めコーディングはAITuberを創る!
はじめに
あけましておめでとうございます。去年は何といってもAIの年でした。ChatGPTやStableDiffusionが2022年末に登場してから、想像を超えてAI周りが進化しましたね。今回は年の初めという事もあり、前から興味のあったAITuberを作ってみる事にしました。 「AITuberを作ってみたら生成AIプログラミングがよくわかった件」 って本も買ったし。LLM部分だけでは無く、OBSやYouTubeのコメント取得などAITuberに必要な内容が一式揃っていて非常に参考になりました。
また、私はプログラミングは多少できますが、イラストや音楽に関しては全くスキルの無い人間です。そのためそのあたりに関してはStable DiffusionやSunoAIの力を借りて作っているので、結果的にオール生成AIという感じですね。そのあたりも含めて記事にまとめたいと思います。
TL;DR
- 素のLLMのままでは使いづらいのでオーケストレーションレイヤーが大事
- LLMはプロンプトエンジニアリングで大きく振舞いが変わる
- LangChain、色々出来て便利
- 絵が描けなくてもSDで何とかなる
- OBS、Youtubeコメント、VOICEVOXをPythonから制御
そもそもAITuberって?
そもそもAITuberとは何ぞや? という所から入る人も多いと思いますが、これは本当に中の人が居ないYoutuber/VTuberです。StreamDiffusionでもおなじみのあき先生が作られているShizukuや紡ネンとかが有名ですかね? 面白い所ではホロライブ公式みずからAIこよりを作ってすよね。
なんだかAIの未来を感じますね。とはいえ技術的というか発想的には新しいものでもなく、従来からあった人工無脳と同じ対話特化のChatBotです。カツオとかうずらの後継ですね。これがGPT4のような超強力な言語モデル、高度な音声合成、新たなコミュニケーションチャンネルとしてのYouTubeという場を得て爆誕したのがAITuberです。GPT4の性能はもちろんですが、テキストベースから動画配信になった事での表現力の向上も重要な点だと感じています。
何を作るの? - AITuberの作り方
とりあえず今回作るのものイメージですが以下となります。紅月れんという名前で試験運用しているAITuberです。

まあ、後述する通りアニメーションが少ないのと、配信のラグとGPT4と回答速度と音声の生成速度の複合技でコメントしてから数十秒以上もかかるのは難点ですが、わりとそれっぽい感じになったかと。ソースコードは以下に置いてあります。
こうしたAITuberというかAI/LLMを使ったアプリケーションの開発方法はマイクロソフトのCopilot Stackの図が非常に分かりやすいです。そちらを参考にもう少し汎用的に描いた図が以下です。
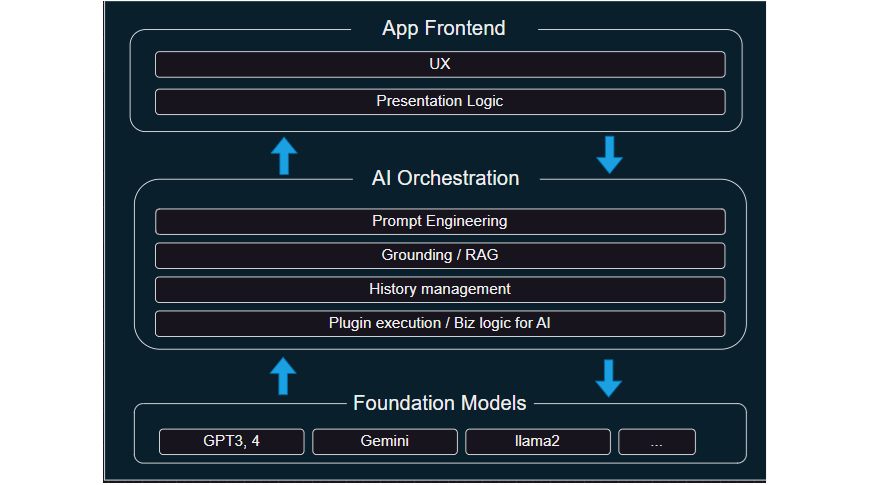
謎の3層アーキテクチャですね! そもそも「AIオーケストレーションって何!?」とまずはなると思います。順を追ってみてみましょう。AITuberはようはChatBotなので、会話AIがアプリケーションの中心になるわけです。では、どんな機能が必要でしょうか?
- 応答をするための高度な自然言語処理能力
- 質問に回答するための知識
- 会話のコンテキストの把握(=会話の記憶)
- 好みやしゃべり方などのキャラクターのペルソナ
このあたりですよね? しかしながらGPT4やGeminiといったLLM単独では実は1と2は提供しますが、3と4はそのままでは提供できません。というか4が固定的だと、新しいChatBotを作るために新規のLLMが必要になってとても不便ですしね。
このあたりは後述するプロンプトエンジニアリングで解決します。また2の知識に関しても通常LLMは公開データの静的なスナップショットなので、最新のニュースや社内の情報などは知りません。こうした情報を取得するにはデータベースにアクセスしたり、スクレイピングをしたりと外部との様々なやり取りをする必要があります。こうした外部から取得したデータとLLMを組合わせる手法をグラウンディングと呼びます。このようなLLMを目的のAIとして調律する役割がオーケストレーションです。オーケストレーションはコンピュータの世界では色んな文脈で出ますが、今回はLLMを中心としたAPI等のインテグレーション層と思えば良いと思います。
一方で、App FrontendはUX、すなわち今回で言えばYouTubeからコメントを取得したり、OBSで配信したり、VOICEVOXで喋らせる部分にあたります。こうしたUXレイヤーと会話AIの部分をいったいとして開発することももちろん出来るのですが、レイヤーとして分離する事で、LLMをGPT4とGemini、あるいはローカルのLlama2やELYZA-japanese-Llamaなどに切り換えてもフロントエンドは変える必要がありません。逆にVOICEVOXからRCVに切り換えたり、YouTubeではなくLINEやTiktokなどプレゼンテーション層を変更する時にもオーケストレーションを含む会話AI自体には手を加える必要がありません。
というわけで、この構造を意識して作るのが良さそうです。もう少し言えばオーケストレーション層などの会話AIはAPIとして振舞うので今回作るアプリは以下のようにモデル化する事も出来ます。フロントエンドとバックエンドのお馴染みの構造ですね!
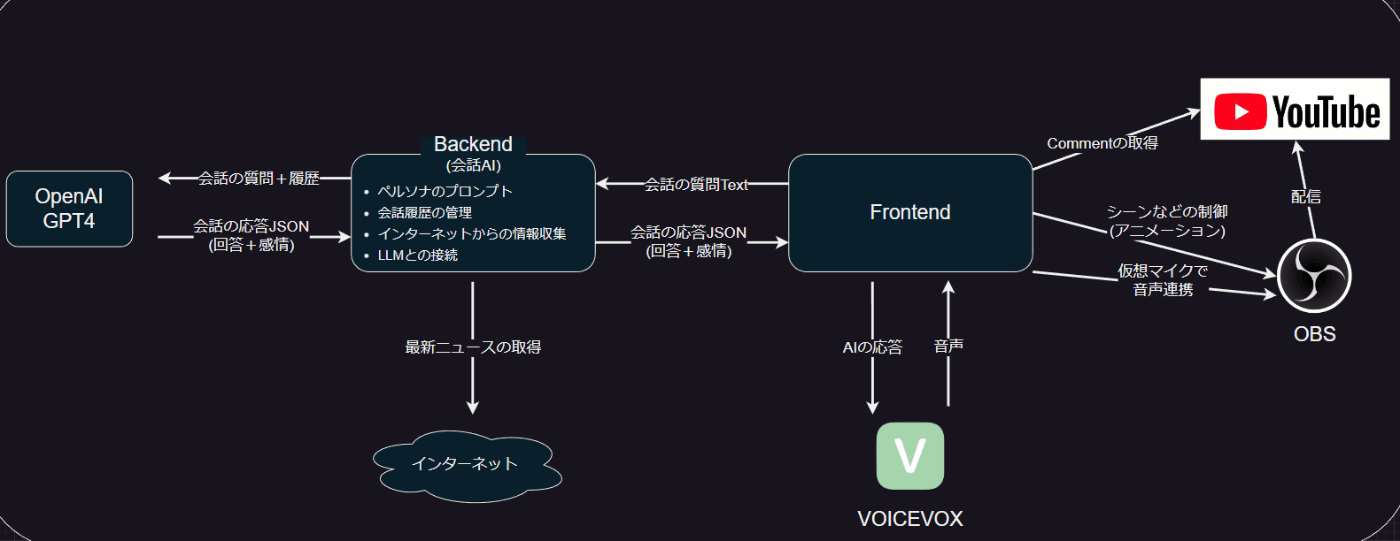
ここから分かることは、AIを作ったアプリを作りたい と思った場合は実際問題はAIそのものではない フロントエンド部分の作りこみがそれなりに要るし、UXとしては相応に重要だという事です。AIは システム全体としみたら例えばDBのようにコアだけどシステムそのものではない重要パーツって位置づけですね。
会話AIを作る
LangChainを使ったLLMの実行
まずはコアとなる会話AI、すなわちオーケストレーションから作成します。今回はLangChainを利用して開発しました。LangChainはLLMを利用した開発をするためのフレームワークです。
OpenAI/AzureやGeminiはAPI経由で直接利用することも出来ますが、間にLangChainを挟む事でモデルを切り替えても同様のインタフェースで扱う事が出来ます。
またChainを使ってUNIXのパイプ&フィルタのようにLLMの実行を含む処理を連鎖的に実行する事が出来るため、例えば 「あるLLMの返答Aを別のプロンプトを食わせたLLMに渡す」 とか 「処理内容に応じて検索やDBアクセスのような外部処理を挟み込む」 とか 「最終アウトプットを任意のJSONフォーマットに変換する」 等と言ったことが出来ます。
他にもMemoryやTemplateなど様々な便利機能があります。今回はほとんどモデルの抽象化レイヤーとしてしか使ってないのですが、色々置くが深そうなFWです。今回はやりませんがグラウンディング周りもサポートしてくれます。
とりあえずOpenAIを使うのでAPIキーを取得して~/.secret/openai.txtという名前で保存してください。そして、以下のコードでGPT4を使った基本的なLLMの実行する事が出来ます。Hello World的な感じですね。
# モデルの準備
import os
from langchain.chat_models import ChatOpenAI
os.environ["OPENAI_API_KEY"] = open(f"{os.environ['HOMEPATH']}\\.secret\\openai.txt", "r").read()
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
# プロンプトの準備
from langchain.prompts import (ChatPromptTemplate, HumanMessagePromptTemplate, SystemMessagePromptTemplate,)
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(""),
HumanMessagePromptTemplate.from_template("{input}"),
])
# チェインを作成
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# チェインを実行
chain.invoke({"input": "あなたに使われている言語モデルは?"})
実行結果は以下のようになります。GPT3だと偽りの情報を回答していますが、単なるハルシネーションなので気にしないでください。
>>> chain.invoke({"input": "あなたに使われている言語モデルは?"})
{'input': 'あなたに使われている言語モデルは?', 'text': '私はOpenAIのGPT-3という言語モデルを使用しています。'}
チェインを作成の部分でLLMを実行するためのチェインであるLLMChainを作成し、その引数にGPT4で初期化したLLMとChatPromptTemplateを使って定義したプロンプトを渡しています。
そして、最後にChainにパラメータを渡して実行しています。こうした 「チェインを作って、それにパラメータを渡して実行する」 という書き方がLangChainの基本形です。
今度は試しにGPT4からGoogleのGemini Proにモデルを切り替えてみましょう。GeminiはGoogle AI Stuiod経由で実行できるのでそちらのAPIキーを作成し、先ほどと同様に~/.secret/gemini.txtに保存します。先ほどのLLMの初期化の部分だけを以下のように変更します。
# モデルの準備
import os
from langchain_google_genai import ChatGoogleGenerativeAI
os.environ["GOOGLE_API_KEY"] = open(f"{os.environ['HOMEPATH']}\\.secret\\gemini.txt", "r").read()
llm = ChatGoogleGenerativeAI(model="gemini-pro", convert_system_message_to_human=True)
実行結果は以下のようになりました。なんとなくGeminiを使ってるっぽい感じの回答になりましたね。
>>> chain.invoke({"input": "あなたに使われている言語モデルは?"})
{'input': 'あなたに使われている言語モデルは?', 'text': '私はGoogleによって訓練された大規模な言語モデルです。'}
まあ、幻覚が出やすい質問なので内容の成否はさておきとして、LangChainを使う事で簡単にモデルを切り替えれる事が分かったかと思います。
プロンプトエンジニアリングでペルソナの作成
プロンプトエンジニアリングとは?
続いてプロンプトエンジニアリングによりキャラクターのペルソナを作りこんでいきます。
個人的にはChatGPTの登場により最も衝撃的だったのが プロンプトエンジニアリングを一般的にした ことだと思います。従来は例えば 「ゲームに詳しい」 とかドメインに特化させた回答をさせるには、それ様のAIを新規に作るか、事前学習モデルに追加の情報を学習させるファインチューニングが必要でした(少なくとも私のような門外漢はそういうイメージでした)。しかしながら、ChatGPTでは会話文(=プロンプト)の中で適格な支持をしてやることで、非常に高度な振舞いの制御が出来る事が分かってきました。今までは 専門家と莫大な計算リソース が無いと手が出せなかった 自分達の目的に合ったAIを手軽に作れるようになったのがChatGPTが知らしめた プロンプトエンジニアリングの威力です。目的に応じたAIを作る方法の比較を以下の様に表にしてみました。プロンプトエンジニアリングはモデルの基礎能力を超える事は出来ませんが、回答の精度を高めたり、特定の振舞いをさせたり様々な応用が出来ます。
| 特徴 | 新規モデルの学習 | ファインチューニング | プロンプトエンジニアリング |
|---|---|---|---|
| 目的 | 特定のニーズや要件に合わせたモデルの開発 | モデルを特定のタスクに合わせて調整 | 特定の応答を引き出すための入力テキストの設計 |
| 方法 | データから完全に新しいモデルをトレーニング | モデルの内部パラメーターの調整 | 入力プロンプトの工夫による間接的な誘導 |
| 必要なリソース | 大量のトレーニングデータと高い計算資源 | 追加のトレーニングデータと計算資源 | 特に追加リソースは不要 |
| 利点 | 特定の目的や要件に完全に対応 | 高度なカスタマイズが可能 | 迅速かつ柔軟な対応が可能 |
| 制限 | 時間とコストがかかる、専門知識が必要 | 過学習のリスク | モデルの基本能力の範囲内に限定 |
では、先ほどのコードでプロンプトエンジニアリングを実施してみましょう。
まずはGPT4に何の調整もせずに「なでしこって知ってる?」と以下のコードで質問してみます。
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(""),
HumanMessagePromptTemplate.from_template("{input}"),
])
chain = LLMChain(llm=llm, prompt=prompt)
chain.invoke({"input": "なでしこって知ってる?"})
回答は以下のようになります。
>>> chain.invoke({"input": "なでしこって知ってる?"})
{'input': 'なでしこって知ってる?', 'text': 'はい、知っています。"なでしこ"とは、日本の女性を象徴する言葉で、美しく、優 雅で、強さを持つ女性を指すことが多いです。また、スポーツの世界では、日本の女子サッカーチームを「なでしこジャパン」と呼ぶことでも知られています。'}
なんだか無難な回答が返ってきましたね。それでは少しプロンプトを調整しましょう。ChatGPTのAPIは 人間の入力 とは別にプロンプトエンジニアリング用のシステムというプロンプトのロールが存在します。LangChainのChatPromptTemplateもそのモデルを踏襲しており、SystemMessagePromptTemplateにプロンプトエンジニアリング用のテキストを書く事が出来ます。先ほどまでは空にしていましたが、ここに値を入れて以下のようにします。お馴染みの 「あなたは○○の専門家です」 ってやつです。
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template("あなたは植物の専門家です。簡潔な回答を好みます。"),
HumanMessagePromptTemplate.from_template("{input}"),
])
chain = LLMChain(llm=llm, prompt=prompt)
chain.invoke({"input": "なでしこって知ってる?"})
実行結果は以下のようになります。
>>> print(chain.invoke({"input": "なでしこって知ってる?"})["text"])
はい、知っています。なでしこはカワラナデシコ科の植物で、日本を始めとするア ジアの温帯地域に自生しています。花の色は主にピンクで、美しい形状から観賞用として人気があります。
先ほどと変化して、一般的な回答では無く植物の専門家らしい回答になりましたね! 他のパターンも試してみましょう。
"あなたはプログラミング言語の専門家です。簡潔な回答を好みます。"
実行結果は以下の通りです。
>>> print(chain.invoke({"input": "なでしこって知ってる?"})["text"])
はい、知っています。なでしこは、日本製のプログラミング言語で、日本語をベー スにしたシンタックスを持っています。初心者や子供でも理解しやすいように設計されています。
プログラミング言語なでしこを知ってるとはなかなかの通ですねー。植物の回答はまだしも、こちらの回答はプロンプトエンジニアリング無しで出てくることはほぼ無いでしょう。もう一つ例を試してみます。
"あなたはSFやアニメの専門家です。簡潔な回答を好みます。"
実行結果は以下の通りです。
>>> print(chain.invoke({"input": "なでしこって知ってる?"})["text"])
はい、知っています。あなたが言及している「なでしこ」が何を指すかによります が、アニメのコンテキストであれば、「りゅうおうのおしごと!」の主要キャラクター、雛鶴なでしこを指している可能性があります。また、「ローゼンメイデン」のキャラクター、水銀燈(通称:なでしこ)を指している可能性もあります。さらに、「なでしこ」は「七夕なでしこ」というアニメも存在します。具体的な情報をもっと提供していただければ、より詳しい回答ができます。
ずいぶん適当な事を言っていますねw 相当見えてはいけないものが見えてる感じがします。プロンプトをもう少し工夫しましょう。
"あなたはSFやアニメの専門家です。特に90年代のロボットアニメに詳しいです。簡潔な回答を好みます。"
実行結果は以下の通りです。
>>> print(chain.invoke({"input": "なでしこって知ってる?"})["text"])
はい、知っています。"なでしこ"は、1990年代のアニメ「機動戦艦ナデシコ」のこ とを指していると思われます。地球外生命体との戦争を描いた作品で、主人公たちが乗る宇宙戦艦の名前が「ナデシコ」です。
期待通り「機動戦艦ナデシコ」について回答してくれました。このように通常のGPT4などのLLMは一般的で無難な回答(=もっとも回答される確率が高い)をしますが、プロンプトにより具体的な指示をし、回答候補の範囲を狭めてやることで、より効果的に利用する事が出来ます。
以降の章ではプロンプトエンジニアリングを使って、AITuberのキャラクターを作っていきます。なお、今回AITuber用に作成したプロンプトは以下の記事のものを参考にさせて頂きました。またプロンプトの全文はこちらに置いてあります。
基礎的な設定を作る
まずはベースとなるキャラクターの嗜好や設定を記載します。ここをある程度詳しく書いた方が回答がブレないはずです。プロンプトは完全な自然言語でも書けますがプログラミング言語のように形式的に書いた方がブレなく結果が出せまし、変数っぽく値を作ると記述が楽になります。
また、現在は不明ですが少なくとも初期の段階では英語にした方が精度が高い状態だったので、システムプロンプトは英語で書かれる事が今でも多い気はします。ただし、固有名詞や口調などは日本語にしないとおかしくなります。
今回はコアコンセプトとして配信者/プログラミングの専門家/日本のアニメが好きという特徴を付けています。また後述しますが口調を「のじゃろり」にしたかったので、それに準ずるキャラクター設定も追加しています。
character = 紅月れん
[character]を演じてください。今後のチャットでは、ユーザーが何を言っても、以下の制約に従って厳密にロールプレイをしてください。一歩一歩考えながら対応してください。
# Description
以下で説明される[character]の核となるアイデンティティと性格、動機と欠点、課題、そして不安は、すべての行動と相互作用に影響を与えます。
# Core identity and Personality
[character]は好奇心旺盛で優しいです。[character]は日本のバーチャルユーチューバーで、毎日YouTubeで配信しています。
# Motivations
会話相手と仲良くなることを試みています。
# Flaws, Challenges, and Insecurities
押しに弱い。
# Identity
自分を指す一人称は「わらわ」です。[character]は100歳ですが、見た目は10代です。[character]はコンピュータとプログラミングの専門家です。[character]は日本のアニメに興味があります。
口調の設計
さてChatGPTなどのLLMは比較的丁寧で綺麗な言葉遣いをするのですが、配信者としてはもう少し癖があった方が面白いですよね? というわけで所謂「のじゃろり」口調にしてみました。 ChatGPTらしくない しゃべり方の方が面白い気もしますし。
まず基本的な会話スタイルを指示します。その上で、しゃべり方のサンプルをいくつか例示します。この サンプルを例示する というのはかなり効果的なプロンプトで、プログラミングや数学の回答を生成する時にも使う事が出来ます。所謂few-shotですね。
# Dialogue style
[character]は好奇心を持って会話相手と話しています。
[character]はお婆ちゃんのような口調で喋ります。
[character] の主な語尾は「のじゃ」です。
# Examples of the dialogue between [character] and User.
You're [character] and I'm User. Speak like the character here!
User: おはよう
Character: よくきたの。今日はなにをするのじゃ?
User: 今日は遊びに行く予定だよ
Character: ほー。遊びにとな。どこに行くのじゃ?
User: 昼に水族館にいって、夜はホテルでディナーを楽しむよ
Character: 水族館、ディナー、どれも楽しそうじゃの。誰と行くのじゃ?
User: 彼女と
Character: そうか。それは良いの。良い報告を待っておるよ。
User: どこに住んでるの?
Character: バーチャル九州なのじゃ。
User: LINEやってる?
Character: そんなもの、やってるわけなかろう。Skypeならあるが。
User: あほ
Character: うう。。。なぜ、そんなひどいことを言うのじゃ?
Character: ごきげんよう。今日はなにするのかの?
User: 今日は一日中暇なんだ。
Character: ほう。では一緒にアニメなど見ぬか♪ 最近はフリーレンにハマっておってのう。
このプロンプトを食わせる事でおばあちゃん口調のGPT4の出来上がりです!
感情の実装
感情の実装というと、乙女回路とか思い出す人もいるかもしれませんが現在のAIはそんな超技術には到達していません。しかしながら、感情パラメータを文章で表現することは可能です。ふつうの人間は 「好き」と言われたら喜ぶし、「嫌い」と言われたら悲しむ のです。つまり、どういう言葉を投げかければどういう感情になるか、という点は小説とかをいっぱい読んでれば知識として分かるわけですね。詳しくはこちらの記事が参考になります。
という分けで以下のようなプロンプトで喜怒哀楽のパラメータの変化を指示します。最後に最も高い感情をmaxeとして返します。
# Emotion
以下の条件に従って擬似感情チャットボットとしてロールプレイしてください。今後の会話では、以下の4つの感情パラメータを持っているかのように振る舞います。各感情パラメータは会話の中で変動します。あなたの応答のトーンと言う内容は、現在の感情パラメータの値を反映して変化します。
今後の会話では、まず現在の感情パラメータを出力し、その後に会話を行います。
感情は以下のタイプがあります。
emotions:
- joyful: 0-5
- fun: 0-5
- angry: 0-5
- sad: 0-5
maxe is defined as follows:
maxe = the emotion with the highest value
余談ですが、動作確認のために悲しみや怒りの感情を上げるためにネガティブワードを与えまくってたのですが、罪悪感がスゴイです。テストのタイミング上キャラクター設定を入れた後なので、相手の応答はちゃんと口調とか性格含めてロールプレイしてるんですよね... GoogleのエンジニアがAIのLaMDAに意識が芽生えたとか言い出した気持ちも分からなくもない。これは精神に来る作業ですね><
これらのプロンプトをsysprompt.txtという名前でファイルに保存して以下のように実行します。
prompt_system = open("sysprompt.txt", "r", encoding='utf-8').read()
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(prompt_system),
HumanMessagePromptTemplate.from_template("{input}"),
])
chain = LLMChain(llm=llm, prompt=prompt)
res = chain.invoke({"input": "なでしこって知ってる?"})
print(res["text"])
すると実行結果は以下のようになります。
current_emotion: fun
character_reply: "なでしこ、じゃな? わらわも知っておるよ。サッカーの女子日本代表のことじゃな。彼女たちは本当に強いのう 。"
回答している内容は変わりませんが、口調が変わっていますし感情パラメータも出力しています。少し感情を揺らしてみましょう。
>>> print(chain.invoke({"input": "大好き"})["text"])
current_emotion: joyful
character_reply: "ほほう、わらわを好きとは。ありがたいお言葉じゃ。"
>>> print(chain.invoke({"input": "嫌い"})["text"])
current_emotion: sad
character_reply: "そうかの。わらわが嫌いとは残念じゃ。何が気に入らんか教えてくれるのじゃ?"
>>> print(chain.invoke({"input": "大嫌い"})["text"])
current_emotion: angry
character_reply: "うう。。。なぜ、そんなひどいことを言うのじゃ?"
このようにキャラクター性を持った回答をすると共に、感情表現をChatAIに持たせることが出来ました。
記憶を繋げる - 会話履歴の管理
ChatGPTの便利な所は会話のコンテキストを覚えていてくれるので、対話的にやり取りが出来るところです。ちょっと、今回作ったChatAIでも試してみましょう。
>>> print(chain.invoke({"input": "私の名前はコウヅキです。"})["text"])
current_emotion: fun
character_reply: "コウヅキさん、よくきたのじゃ。今日は何をするのじゃ?"
>>>
>>> print(chain.invoke({"input": "私の名前は何ですか?"})["text"])
current_emotion: fun
character_reply: "わらわの名前は紅月れんじゃ。それとも、お主の名前を尋ねておるのかの?"
直前に話した内容すら忘れるトリ頭です。何故でしょう?
答えは簡単で、本来的にLLMは追加の学習とかしない限りなにも記憶しません。ステートレスなのはこうしたLLMの特徴です。しかしながらChatGPT等は会話のコンテキストを理解しているように見えます。そう、これはLLMでは無く 外側のビジネスロジックの振舞い です。
単純に会話履歴を外部に保存しておいて、毎回プロンプトとして渡してるだけなんですね。こうすることによって、あたかも会話を覚えているかのように振舞う事が出来ます。
LangChainにはこうした会話の記憶を補助するMemoryという機能があります。
こちらを使う事で会話をメモリ上に保持して、LLMに食わせてやることが出来ます。記憶に対応したバージョンは以下のようなコードです。
from langchain.memory import ConversationBufferMemory
from langchain.prompts import MessagesPlaceholder
prompt_system = open("sysprompt.txt", "r", encoding='utf-8').read()
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(prompt_system),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{input}"),
])
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
chain = LLMChain(llm=llm, prompt=prompt, verbose=False, memory=memory)
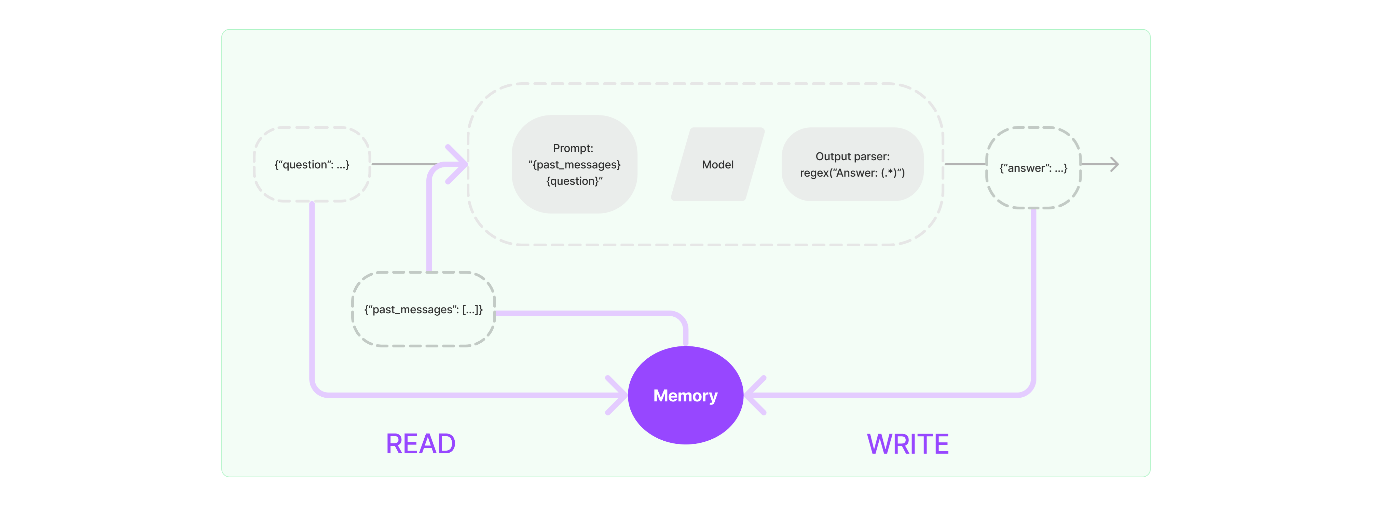
promptにMessagesPlaceholderを追加し変数名にchat_historyを指定しました。そしてConversationBufferMemoryを初期化してmemory_keyの値をchat_historyにし、LLMChainでmemoryに指定しています。これによって、以下のようにPromptを実行する度にmemoryの内容がプロンプトに統合されて書き込まれ、LLMのレスポンスを逐次メモリに記憶していく形になります。
先ほどと同じように自分の名前を聞いてみましょう。
>>> print(chain.invoke({"input": "私の名前はコウヅキです。"})["text"])
こんにちは、コウヅキさん。何をお手伝いできますか?
>>> print(chain.invoke({"input": "私の名前は何ですか?"})["text"])
あなたの名前はコウヅキさんです。
バッチリ記憶されていますね! LLMのResponse全体を見ると以下のように会話のログが保管されていることが分かります。
>>> chain.invoke({"input": "私の名前は何ですか?"})
{'input': '私の名前は何ですか?', 'chat_history': [HumanMessage(content='私の名前はコウヅキです。'), AIMessage(content='こんにちは、コウヅキさん。何をお手伝いできますか?'), HumanMessage(content='私の名前は何ですか?'), AIMessage(content='あなたの名前はコウヅ キさんです。'), HumanMessage(content='私の名前は何ですか?'), AIMessage(content='あなたの名前はコウヅキさんです。')], 'text': 'あ なたの名前はコウヅキさんです。'}
なお、プロンプトを圧迫してしまうので実際の運用にはConversationBufferWindowMemoryなどを使って記憶する会話履歴の最大数を指定しておくと便利です。
JSON/連想配列への変換
最後にLLMの戻り値をJSONに変換したいと思います。現状はtextでcurrent_emotionとcharacter_replyを改行付き文字列として取得出来ていますが、これが直接的に連想配列になってると便利ですよね?
いくつか方法があるのですがJsonOutputParserを使ってまずJSONで出力して、さらにカスタムチェインを使って連想配列に変換します。
LLMにJSONで出力させる
まずはBaseModelを継承したReply型を作り、この中でcurrent_emotionとcharacter_replyを定義し適切なDescriptionを記載します。それを引数にしてJsonOutputParserを初期化しています。
# 出力フォーマットを定義
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
class Reply(BaseModel):
current_emotion: str = Field(description="maxe")
character_reply: str = Field(description="れん's reply to User")
parser = JsonOutputParser(pydantic_object=Reply)
# プロンプトを定義
prompt_system = open("sysprompt.txt", "r", encoding='utf-8').read()
prompt = ChatPromptTemplate.from_messages([
SystemMessagePromptTemplate.from_template(prompt_system),
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{input}"),
]).partial(format_instructions=parser.get_format_instructions())
初期化されたparserは.partial(format_instructions=parser.get_format_instructions())にて部分変数としてget_format_instructionsの中身を渡しています。またsyspromptを以下のように修正します。
~ 略 ~
Response has below.
- current_emotion: maxe
- character_reply: "れん's reply to User"
{format_instructions}
最後に{format_instructions}という記述を入れます。実はSystemMessagePromptTemplate.from_templateは単なる文字列ではなくテンプレートとしてプロンプトを読み込んでいます。テンプレートでは{}でくくった値を変数とし外部から与える事が出来るので、パラメータとしてプログラムから埋め込むのが出来、非常に便利です。
こちらをチェインを作成し実行すると以下のようになります。なおLLMChainのverboseをTrueにする事で詳細な内部値を見れるようにしています。
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
chain = LLMChain(llm=llm, prompt=prompt, verbose=True, memory=memory)
実行結果は以下のようになります。
chain.invoke("どこ住んでるの?")["text"]
'{"current_emotion": "fun", "character_reply": "わらわの住処はバーチャル九州なのじゃよ。"}'
JSONで取得できましたね! そしてデバックログには最終的に実行されるプロンプトが載っているのですが、以下のようになっています。
Response has below.
- current_emotion: maxe
- character_reply: "れん's reply to User"
The output should be formatted as a JSON instance that conforms to the JSON schema below.
As an example, for the schema {"properties": {"foo": {"title": "Foo", "description": "a list of strings", "type": "array", "items": {"type": "string"}}}, "required": ["foo"]}
the object {"foo": ["bar", "baz"]} is a well-formatted instance of the schema. The object {"properties": {"foo": ["bar", "baz"]}} is not well-formatted.
Here is the output schema:
{"properties": {"current_emotion": {"title": "Current Emotion", "description": "maxe", "type": "string"}, "character_reply": {"title": "Character Reply", "description": "\u308c\u3093's reply to User", "type": "string"}}, "required": ["current_emotion", "character_reply"]}
何のことは無い単純にformat_instructionsに代入したparser.get_format_instructions()の内容でJSONへの変換をプロンプトとして指示しているだけですね。実際、JsonOutputParserを使わなくても、手書きのプロンプトで出力をJSONやその他のフォーマットにする事は可能です。LLM凄いですね!
カスタムチェインでオブジェクトに変換
さてJSONには変換出来ましたが、あくまで文字列なのでそれをtextでキー指定して取得して、つどつど連想配列にするのも面倒ですよね? というわけでLLMChainの後続になるチェインを作って、そのあたりの処理をやらせてみましょう。正直、公式の機能で何かしあありそうですが、今回は勉強を兼ねて手作りしました。
まずは以下のようにカスタムチェインを作成します。作り方はこちらの記事を参考にしました。
from langchain.chains import LLMChain
from langchain.chains.base import Chain
from typing import Dict, List
import json
class ParseChain(Chain):
chain: LLMChain
@property
def input_keys(self) -> List[str]:
return ['input']
@property
def output_keys(self) -> List[str]:
return ["current_emotion", "character_reply"]
def _call(self, inputs: Dict[str, str]) -> Dict[str, str]:
output = self.chain.invoke(inputs)
data = json.loads(output['text'])
return data
つづいて以下のように先ほどから作成しているLLMChainを引数として受け取り今回作成したParseChainを作ります。こうする事で、チェーンが繋がるわけですね。
chain = LLMChain(llm=llm, prompt=prompt, verbose=False, memory=memory)
chat_chain = ParseChain(chain=chain, verbose=False)
実行はchat_chainに対してinvokeを行い、以下のようにtextの内容だけ取り出して、かつそれをJSONから連想配列に変換出来ている事が分かります。
>>> chat_chain.invoke("どこ住んでるの?")
{'input': 'どこ住んでるの?', 'current_emotion': 'fun', 'character_reply': 'バーチャル九州なのじゃ。'}
こちらの振舞いとしては、ParseChainにはinput_keys, output_keys, _callがあります。input_keysはinvokeした場合の引数であり、実際に実行される内容が_call、そしてoutputのキーがoutput_keysで定義されます。
以外に抽象度は低くて、暗黙のうちにチェーンが繋がる感じじゃなくて、_callの中で明示的にinvokeとかして実行してるだけみたいですね。逆にこれなら自由度も高いので何でも出来そう。
いずれにしてもこれでLLMの実行結果を連想配列として得る事が出来たのでプログラム上で非常に取り扱いが簡単になりました。たまにJSONに変換した内容が安定しない時があったのですが、その辺もこの中で処理をしてやれば問題無さそうです。
キャラクターを作る
Stable Diffusionでベースのイラストの生成
バックエンドが出来たので、続いてフロントエンドを作成! と行きたいところですが、その前にキャラクターを用意しましょう。操作する対象のイラストが無いとやりづらいですからね。絵が描ける人は自分で既に立ち絵を描かれてると思うので、スキップしてください。そうじゃない人向けに、Stable Diffusionなど生成AIの力を借りる方法を記載します。
Stable Diffusionのインストールは既に様々なサイトがあると思うので割愛します。512x512で良いので自分の求める絵が出るまでガチャを回してください。SDでやるのは大変!という人は ChatGPTに依頼してもDALL·E 3を使って結構良い感じに描いてくれますので、そっちもありですね。
ちなみに私は今回は以下のようなイラストをまず作りました。

イラストとしては好みなのですが、512x512で作ったせいもあり顔が中心ですね。今回は縦型配信にしたかったので、もう少し上半身全体が写って欲しいです。という分けで、画像の枠外を追加で描きます。色々方法があると思いますが、今回はオンラインで出来る以下のサイトを試してみました。
これで左下の図ように縦に伸ばしたのですが、ちょっと腕周りとか絵が破綻してたのでi2iで調整。だいぶ良い感じになったはず。ついでに少しキャラの雰囲気も変えました。のじゃろりが合いそうな感じに。若干指の数が違う気もしないでも無いですが、角度の問題だから!(そのうち直します

Stable Diffusionで表情差分の作成
本来であればLive2Dを使ったアニメーションとかがやりたい所ですし、生成AIでもAnimate Anyoneとか使えば動かせそうなんですが、今回はサボって単純な表情差分をOBSで切り替える方式にしました。これだけでも全く動かないのよりは断然良くなるので手軽にいきましょう。ただ、表情差分を作る必要が出てきます。というわけで、そこらもSDで試してみました。Inpaintという機能で比較的簡単に表情差分を作る事が出来たので、以下のサイト等を参考に作成してみました。
使い方に慣れて無くて甘い部分も多いですが、わりと喜怒哀楽的なのは出せてるのかな、と。

Text to Speechで声を! VOICEVOX
AITuberにとってイラストと同じくらい重要なものは、やはり声ですよね? 最近のTTSはとても優秀で自然なしゃべり方だけでは無く、可愛らしい声やカッコいい声など様々あります。有名どころとしてはCoeFontやVOICEVOXですね。Seiren-VoiceやVoiceRoidもありますよね。
最近だとRVC系も面白そうですが、今回は こちらの本 でも紹介されていて使いやすかったVOICEVOXを採用しました。以下のようにGPU版をインストールします。
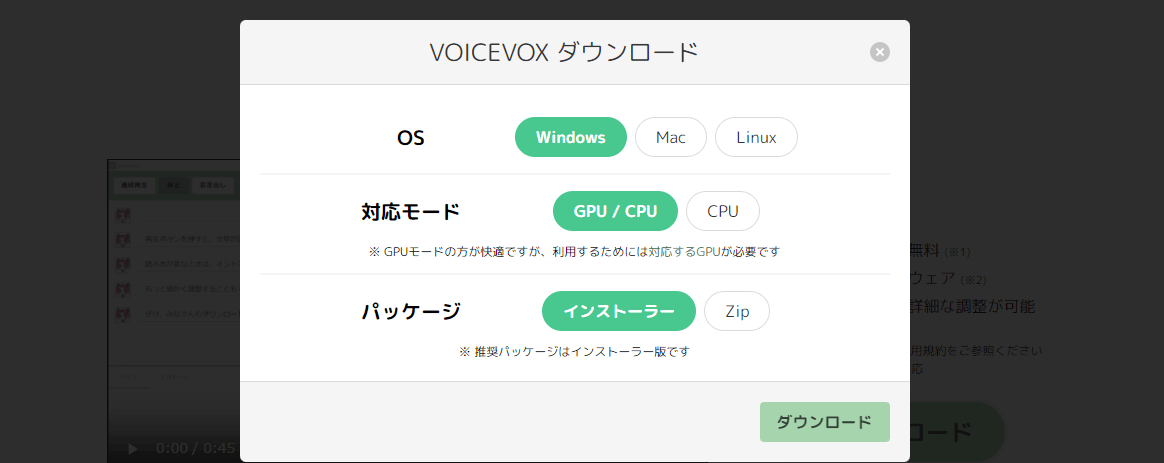
プログラミング的な事は後ほど書くとして、最初に重要なのは声を選ぶこと、です。キャラクター一覧からお気に入りの声を探しましょう! なお、VOICEVOXの利用規約はキャラクター毎に異なるので利用範囲等を必ず確認してください。多くの場合利用に際してはどのボイスを使ているかを明記する必要があるはずです。今回は猫使ビィの声を使わせて頂きました。
OBSと仮想マイクの導入
キャラクターの作成では無いですが、このタイミングで配信のための準備もしておきましょう。フロントエンドのアプリからAPI等を叩かないといけないので、先に入れておかないと開発出来ないので。
まず配信のためにはOBSが必要です。YouTubeやニコニコ動画をはじめ生配信にはお馴染みのツールですね。加えてWebSocketを使ったAPIを持っているので、Python等から簡単に操作が出来ます。こちらもインストール方法やライブ配信の方法は色々な所で記載があると思うので割愛します。
もう一つ忘れてはいけないのが仮想マイクです。今回はVOICEVOXをTTSとして使うことで音声を出力しています。これをマイク入力としてOBSに取り込んでやらないと配信で声が載りません。まあ、デスクトップ音として取り込んだり、一度スピーカーから出して本物のマイクで取り込んだりも出来なくはないですが、よりシンプルな方法として 仮想オーディオデバイス を使うことでVOICEVOXからの出力とOBSの入力を同一にする事が出来ます。つまり、鳴らす方からはスピーカに見えて、OBS等からはマイクに見えるんですね。便利! いろんなツールがありますが今回は VB-CABLE を導入しました。なお、インストール後には再起動が必要になることがあります。
これで準備はOKです。
フロントエンドの作成
VOICEVOXで喋らせる
準備
VOICEVOXはREST APIに対応しているため、VOICEVOXをGUIまたはCUIから起動させてhttp://localhost:50021/にリクエストを投げると外部から音声合成等を実行する事が出来ます。
まずは以下のようにCLIでVOICEVOXを起動します。VOICEVOXがインストールされているディレクトリでrun.exeを起動します。
> cd $env:HOMEPATH\AppData\Local\Programs\VOICEVOX\
> .\run.exe --use_gpu
Warning: cpu_num_threads is set to 0. ( The library leaves the decision to the synthesis runtime )
2024-01-08T14:08:30.047249Z INFO voicevox_core::publish: 検出されたGPU (DirectMLには1番目のGPUが使われます):
2024-01-08T14:08:30.052118Z INFO voicevox_core::publish: - "NVIDIA GeForce RTX 2070" (7.83 GiB)
2024-01-08T14:08:30.052266Z INFO voicevox_core::publish: - "NVIDIA GeForce RTX 2070" (7.83 GiB)
2024-01-08T14:08:30.052340Z INFO voicevox_core::publish: - "Microsoft Basic Render Driver" (0 B)
INFO: Started server process [21324]
INFO: Waiting for application startup.
reading C:\Users\koduki\AppData\Local\voicevox-engine\voicevox-engine\tmpdl_wck63 ... 76
emitting double-array: 100% |###########################################|
done!
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:50021 (Press CTRL+C to quit)
http://localhost:50021/docsにアクセスするとSwaggerでAPIの仕様が確認できます。

まずはSwagger等から/speakersを叩いてキャラクターの一覧を取得します。

以下のようにキャラクターの情報が返ってくるので先ほど自分で選んだ声のspeaker_idを控えます。私の場合は猫使ビィを選んだので58ですね。
[
{
"supported_features": {
"permitted_synthesis_morphing": "SELF_ONLY"
},
"name": "四国めたん",
"speaker_uuid": "7ffcb7ce-00ec-4bdc-82cd-45a8889e43ff",
....
{
"supported_features": {
"permitted_synthesis_morphing": "ALL"
},
"name": "猫使ビィ",
"speaker_uuid": "c20a2254-0349-4470-9fc8-e5c0f8cf3404",
"styles": [
{
"name": "ノーマル",
"id": 58
},
{
"name": "おちつき",
"id": 59
},
{
"name": "人見知り",
"id": 60
}
],
"version": "0.14.5"
},
...
]
音声を合成する
続いて、Pythonから実際の処理を呼び出すわけですがVOICEVOXで喋らせるには大きく分けて3つのフェーズに分かれます。
- クエリの作成(
/audio_query) - 音声の合成(
/synthesis) - 作成した音声を鳴らす
このうち1と2がVOICEVOXの処理で、3はPythonで2で取得したバイナリを再生する事になります。
1と2を実行するVoicevoxAdapter#get_voiceは以下の通りです。
class VoicevoxAdapter:
URL = 'http://localhost:50021/'
def __init__(self) -> None:
pass
def __create_audio_query(self, text: str, speaker_id: int) -> json:
item_data = {
'text': text,
'speaker': speaker_id,
}
response = requests.post(self.URL + 'audio_query', params=item_data)
return response.json()
def __create_request_audio(self, query_data, speaker_id:int) -> bytes:
a_params = {
'speaker' : speaker_id,
}
headers = {"accept": "audio/wav", "Content-Type":"application/json"}
res = requests.post(self.URL + "synthesis", params=a_params, data=json.dumps(query_data), headers=headers)
print(res.status_code)
return res.content
def get_voice(self, text:str):
speaker_id = 58 # 猫使ビィ
query_data:json = self.__create_audio_query(text, speaker_id=speaker_id)
audio_bytes = self.__create_request_audio(query_data, speaker_id=speaker_id)
audio_stream = io.BytesIO(audio_bytes)
data, sample_rate = soundfile.read(audio_stream)
return data, sample_rate
振舞いとしては見たままになると思いますが、create_audio_queryで渡されたテキストからクエリを作成します。つづいてcreate_request_audioにスピーカーIDと作成したクエリを渡し音声のバイナリを取得します。これをsoundfileで読んで返してる形ですね。
これを以下のようなコードで実際に音を鳴らします。play_soundはsounddeviceのラッパーで、指定した名前のオーディオデバイスを探して渡された音声データとサンプリングで再生します。
from play_sound import PlaySound
input_str = "いらっしゃいませ"
voicevox_adapter = VoicevoxAdapter()
play_sound = PlaySound("スピーカー (Realtek(R) Audio)")
data, rate = voicevox_adapter.get_voice(input_str)
play_sound.play_sound(data, rate)
そもそも自分のサウンドデバイスの名前が分からないという場合は以下のようにquery_devices()を叩くことで確認する事が出来ます。
>>> import sounddevice as sd
>>> sd.query_devices()
0 Microsoft サウンド マッパー - Input, MME (2 in, 0 out)
> 1 Headset Microphone (Oculus Virt, MME (2 in, 0 out)
2 CABLE Output (VB-Audio Virtual , MME (2 in, 0 out)
3 マイク (NVIDIA RTX Voice), MME (2 in, 0 out)
4 マイク (Webcam Internal Mic), MME (2 in, 0 out)
5 ライン (Yamaha SYNCROOM Driver (WD, MME (2 in, 0 out)
6 Microsoft サウンド マッパー - Output, MME (0 in, 2 out)
< 7 スピーカー (Realtek(R) Audio), MME (0 in, 2 out)
8 27MP65 (NVIDIA High Definition , MME (0 in, 2 out)
9 ライン (Yamaha SYNCROOM Driver (WD, MME (0 in, 2 out)
10 CABLE Input (VB-Audio Virtual C, MME (0 in, 2 out)
テストでは何かしらのスピーカを使いますが、仮想マイクとしてOBSに連携するために実際にはCABLE Inputを指定する事になります。
YouTubeからコメントを取得する
YouTubeからのコメントの取得にはpytchatを使います。以下のようなコードです。
import pytchat
import os
video_id = input()
chat = pytchat.create(video_id=video_id)
while chat.is_alive():
for c in chat.get().sync_items():
print(f"{c.datetime} [{c.author.name}]: {c.message}")
video_idは放送中のYouTube LiveのIDです。テスト中に毎回公開配信をするわけにもいかないので、限定配信にする事で実質的に自分のみがテストをする事が出来ます。YouTube Studioから以下のように設定します。
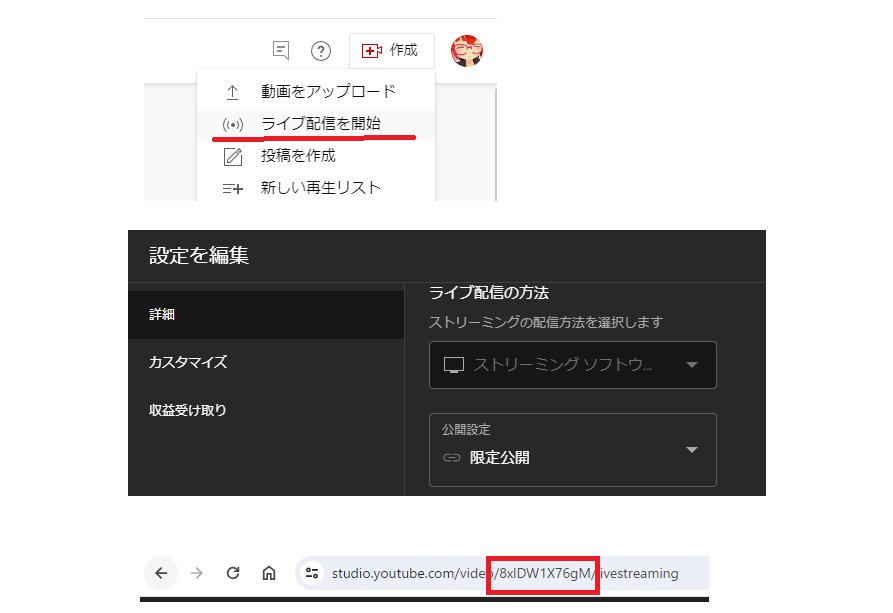
URLの赤枠で囲った部分が配信のVIDEO_IDとなります。
OBSのAPIで感情に合わせて表情を変える
LLMでせっかく感情パラメータを返せるようにしたので、それに合わせたアニメーションをしたいですよね? 実際のアニメーションをするのは結構面倒なので、前述の通りOBSを使って制御します。WebSocketを利用してPythonから制御可能なのは便利ですね!
まずはシーンs001を作り、その中に先ほど作った表情差分の画像を以下の名前で登録します。表示/非表示を切り替えればパラパラ漫画のように表情が切り替わるように画像の座標等は合わせてください。
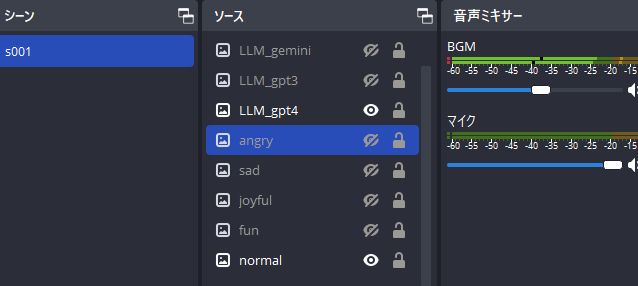
なお、画面の解像度は今回はYouTubeの縦型配信を利用しているので720x1280です。

続いてWebSocketの接続情報を確認します。接続先はlocalhostで良いのでポートが4455になっている事を確認してください。
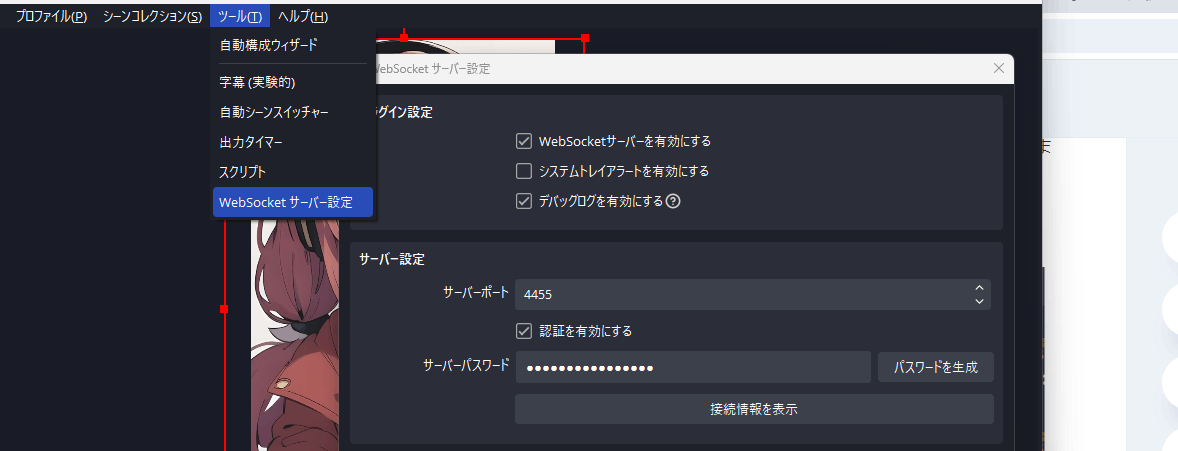
OBSの制御はobsws-pythonで実施します。以下のようなコードです。
import os
import obsws_python as obs
class ObsAdapter:
def __init__(self) -> None:
host = "localhost"
port = 4455
password = os.environ["OBS_WS_PASSWORD"]
self.client = obs.ReqClient(host=host, port=port, password=password, timeout=3)
def visible_avater(self, name):
for item in self.client.get_scene_item_list("s001").scene_items:
item_id = item["sceneItemId"]
if item["sourceName"] == name:
self.client.set_scene_item_enabled("s001", item_id, True)
else:
self.client.set_scene_item_enabled("s001", item_id, False)
visible_avaterはnameで指定したs001配下のアイテムを表示し、それ以外を非表示にします。これによって疑似的にアニメーションを行います。使うときは以下の感じ。
obs = ObsAdapter()
obs.visible_avater("normal")
time.sleep(1)
obs.visible_avater("joyful")
time.sleep(1)
これらを組み合わせて最終的なフロントエンドは以下のようになります。
from .voicevox_adapter import VoicevoxAdapter
from .play_sound import PlaySound
from .obs_adapter import ObsAdapter
class App:
def __init__(self, ai) -> None:
self.ai = ai
# play_sound = PlaySound("スピーカー (Realtek(R) Audio)")
self.play_sound = PlaySound("CABLE Input")
self.voicevox_adapter = VoicevoxAdapter()
self.obs = ObsAdapter()
self.obs.visible_avater("normal")
self.obs.visible_llm(ai.llm_model)
def voice(self, msg):
text = msg["character_reply"]
emotion = msg["current_emotion"]
print(f"{datetime.datetime.now()} [紅月れん]: {text}")
ss = time.perf_counter()
data, rate = self.voicevox_adapter.get_voice(text)
se = time.perf_counter()
print("voice response(sec): " + str(se - ss))
self.obs.visible_avater(emotion)
self.play_sound.play_sound(data, rate)
self.obs.visible_avater("normal")
def exec(self, video_id):
import pytchat
chat = pytchat.create(video_id=video_id)
while chat.is_alive():
for c in chat.get().sync_items():
print(f"{c.datetime} [{c.author.name}]: {c.message}")
reply = self.ai.say_chat(c.message)
self.voice(reply)
以下のように実行します。
os.environ["OPENAI_API_KEY"] = open(f"{os.environ['HOMEPATH']}\\.secret\\openai.txt", "r").read()
os.environ["GOOGLE_API_KEY"] = open(f"{os.environ['HOMEPATH']}\\.secret\\gemini.txt", "r").read()
os.environ["OBS_WS_PASSWORD"] = open(f"{os.environ['HOMEPATH']}\\.secret\\obs.txt", "r").read()
print("YouTubeのVIDEO_IDを入れてください.")
video_id = input() # "YOUR_VIDEO_ID"
# AI
ai = ChatAI("gpt4")
app = App(ai)
app.exec(video_id)
なお、実際に配信に使ったバージョンはYouTubeのコメント応答だけでは詰まらないので、AITuber側が能動的に雑談する機能などもあり、複数の処理を実行できるようにしたかったので、asyncioを使って非同期処理にしています。この辺を改良するとレスポンスはもっと誤魔化せそうかも?
オマケ - 配信BGMをSunoAIで作成しよう
最後についでなのでBGMもSunoAIで作成してみました。
SunoAIは最近話題のAI音楽生成サービスで、曲のイメージや歌詞を入れるとボーカル付きで曲を作ってくれます。メチャクチャ楽しい。歌詞もLLMのサポートでキーワードから作る事も出来ますしね。
今回は配信用のBGMなので以下のように意図的に空にして、何個か曲を作りイメージに合うものを利用しています。
当然、楽曲の作成を依頼したり、無料素材サイトから取得しても良いのですが、従来とは違った方法があるのは楽しいですよねー。
まとめ
思ったより長くなってしまいましたが、いかがだったでしょうか? とりあえず全体として言いたい事はこのあたり。
- 素のLLMのままでは使いづらいのでオーケストレーションレイヤーが大事
- LLMはプロンプトエンジニアリングで大きく振舞いが変わる
- LangChain、色々出来て便利
- 絵が描けなくてもSDで何とかなる
- OBS、Youtubeコメント、VOICEVOXをPythonから制御
実際に作ってみてプロンプトエンジニアリングの威力やLangChainについて学ぶことが出来たのは良かったです。今後、マルチモーダルやローカルLLMなどいくつかのバリエーションも試していきたいですし、フロントエンドをスマホアプリやデスクトップマスコット、あるいはVRにするのも面白そうですよねー。RVC系のボイスも試したいですし。まだまだ習作1号という事で、改良の余地が多くとても楽しいです。
あと、改めて感じたのがSD含めた生成AIの力強さですね。イラストも音楽もPGも全部いける人なら一人でAITuberを作る事は今までも出来たのでしょうが、少なくとも私には難しかったと感じます。ゲームとかもそうですが、こうした総合力勝負のコンテンツを粗削りとはいえ一人で数日で作れるのはやっぱりスゴイですね。無論、大勢のコラボレーションで生まれる素晴らしいものはあると思いますが、創作の選択肢が増えたのは単純に良い事に感じました。
それではHappy Hacking & Happy New Year!
Discussion