Javaがサーバレスに至るまでの道のり
はじめに
先日、JakartaOne Live Japan 2022というイベントで登壇させていただく機会を頂きました。
QuarkusやHelidonのような新しめのEEフレームワークがこれまでのPayaraやWebLogicとどう違うのか? CloudRunのようなサーバレス環境でMicroProfileのどの機能が効果的に働くのか? という点を最近のWeb開発周りのトレンドと絡めながら話ました。上記のようにアーカイブ動画も公開されていますが、せっかくなのでQuarkusがサーバレス環境で実行に最適化されるまでの周辺事情等をまとめたいと思います。Javaだけに留まらず最近の環境事情の整理にも役立つかと思います。
TL;DR
- Quarkus/Helidonは軽量で高速な新しいEEフレームワーク
- コンテナや、サーバレス、クラウドネイティブなど最新のトレンドに基づいた設計
- GCPのCloud Runで手慣れたEEの開発と運用を行う事も出来る
MicroProfileとマイクロサービスあるいはCloud Native
Jakarta EE(Java EE/J2EE)には全機能をもったFullProfileとEJBなどを抜きWebアプリケーションの開発に最適化したWebProfileがあります。またEE10からはさらに小さくAPIの開発等に特化したCoreProfileが登場しました。一方で、ここ数年のEE界隈ではMicroProfileという言葉も聞くようになりました。
名前だけ聞くとCoreProfileと同様にWebProfileよりも小さなプロファイルだと考えてしまいそうですが、それは誤解です。
例えば以下がEE10のスペックです。

ref: JAKARTA EE 10 AND BEYOND
一方で最新のMicroProfile 5.0のスペックは以下の用になります。
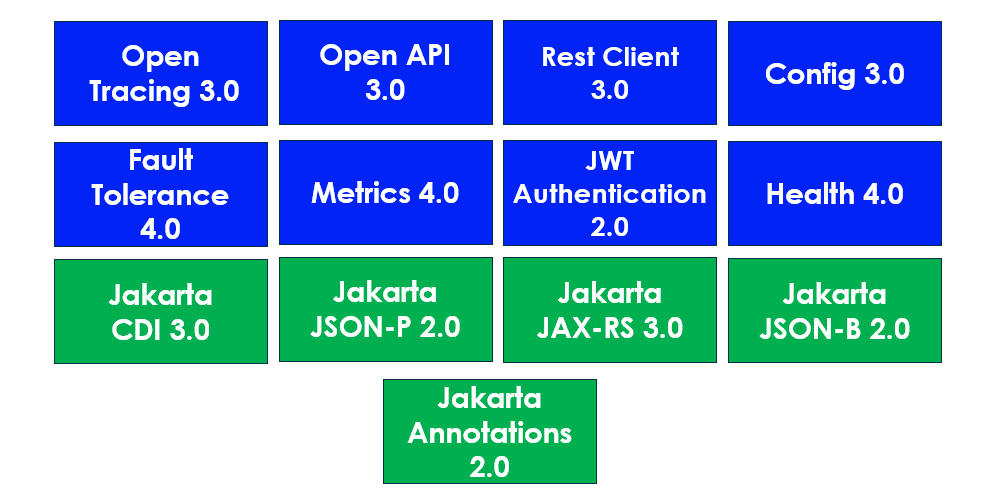
緑の部分はCoreProfileとも被っており、一見するとたしかにEEのサブセットに見えるのですがOpen Tracing や MetricsなどEE10のフルプロファイルにすら入ってない仕様があります。これがどこから来たのか? というとマイクロサービスの実装に便利な仕様が含まれている事がポイントです。
それではマイクロサービスに便利な機能とは何でしょうか? その考え方の指針の一つがThe Twelve-Factor AppやBeyond the Twelve-Factor Appです。元々Herokuが出したベストプラクティスなのでマイクロサービスというよりはサーバレスな特性も強いですが、設定値を環境変数で上書き出来るMP Configを始めこのプラクティスの影響を受けた仕様もいくつかあります。
また、Spring BootやHystrixのようなNetflixのOSSスタック、OpenTracingやOpenMetrics (Prometheus)など先行したOSS実装やJavaに限定しないオープンな仕様も取り込んでいます。クラウドネイティブと言い換えても良いかもしれないですね。
このようにMicroProfileには従来のEE由来以外の機能も多く含まれており、単純にサブセットという分けではありません。理論的にはWebProfileより大きくても良いのです。
MicroProfileのどの機能がCloudRunのような実際のサーバレス環境で役に立つかは後ほど見ていきたいと思います。
コンテナとk8s - EEの民主化
最近はDockerの名前を聞かない日は無いくらい普及したDockerやk8sですが、名前や概要は知っていても今一つどう使えば良いのかがピンと来ない、という方も居るのではないでしょうか? 色々な説明があると思いますがJakarta EEのエンジニア向けにはWebLogicやPayaraといったEEのAPサーバのパワーがJava以外の世界にも民主化されたもの、と捉えると分かりやすいと思います。
そもそもJakarta EEの原初であるJ2EEはCORBAなど分散環境が持て囃されていた時代にJava向けの分散実行基盤として登場した経緯があります。つまりマイクロサービスのような分散環境を上手く処理するために使われるk8sとユースケースが非常に似ているのです。k8sとEEのアーキテクチャを対比させると次の図のようになります。
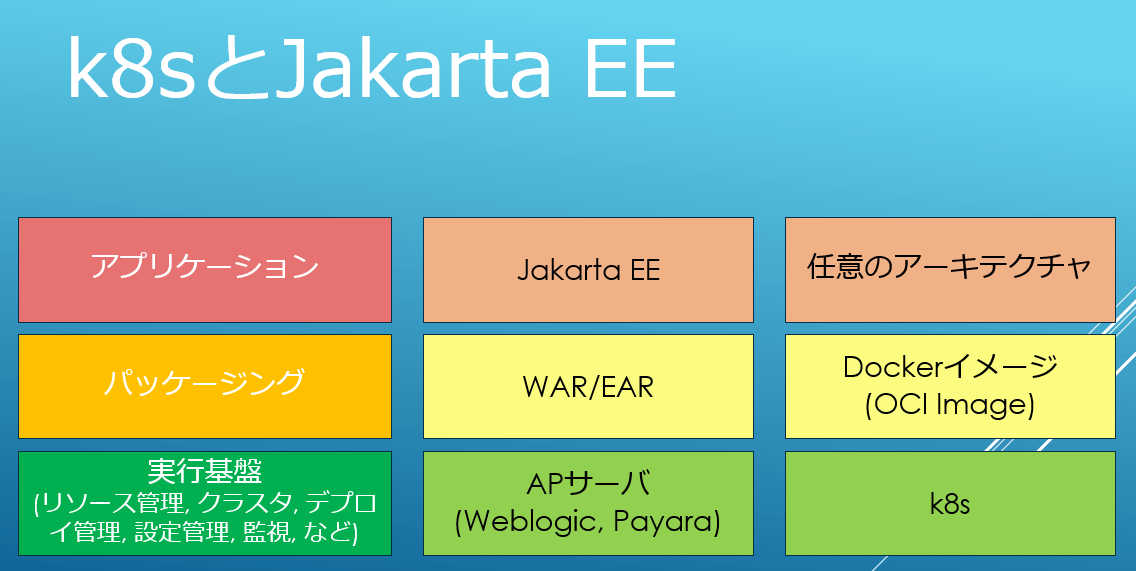
つまりDockerはWARやEARに相当する依存関係を内包しポータビリティを高めたパッケージング技術です。そしてリソース管理, クラスタ, デプロイ管理, 設定管理, 監視等などの分散環境での実行に必要なインフラ機能諸々はWebLogicがそうであったようにk8sが担う事になります。分かりやすいですね? このようにJavaエンジニアが楽しんでいたEEの便利さを言語やFWを限定せずに利用できるのがk8sの魅力、という分けです。これだとEE環境からk8s環境に移行するメリットが少なく感じますよね? 実際、Javaしか使わないのであればそうなんですが、現在の開発や運用のエコシステムの中核はDocker/k8sなので初期のころはともかく現在は移行を考えるのは妥当でしょう。ちなみにDockerに関しては別途以下の記事にもまとめているので、良ければご参考ください。
この前提でWebLogicやPayaraのようなトラディショナルなEE環境をk8sに載せた場合は以下の図の左の様になります。同じ色の箱で分かる通り、機能やロールが重複してるわけですね。そのため、より最適な形にするためには右側のように重複を省いてk8sベースのアーキテクチャに寄せてやる必要があります。
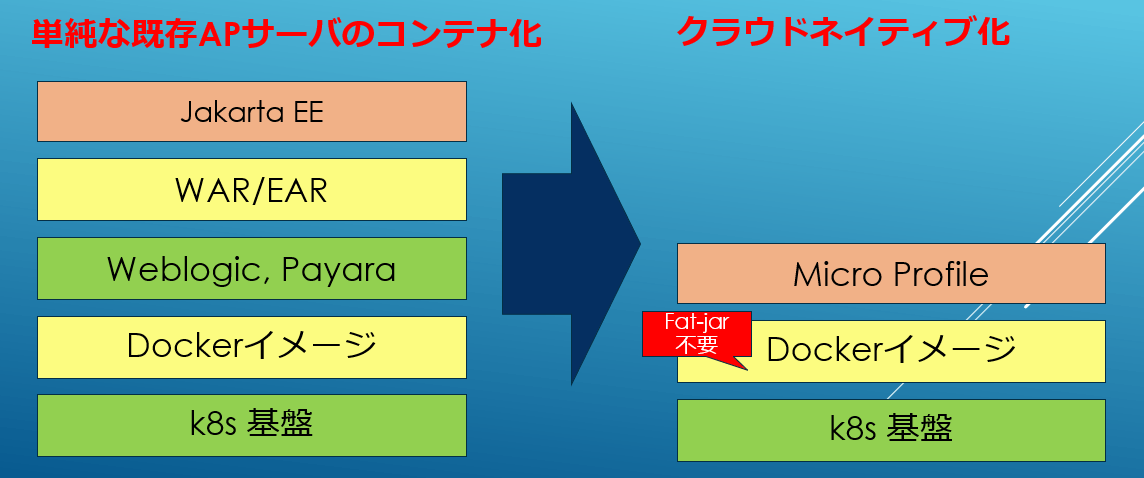
そのため、HelidonやQuarkusといった新しいEE環境ではAPサーバではなく単なるFWとしてMicroProfileが実装されています。
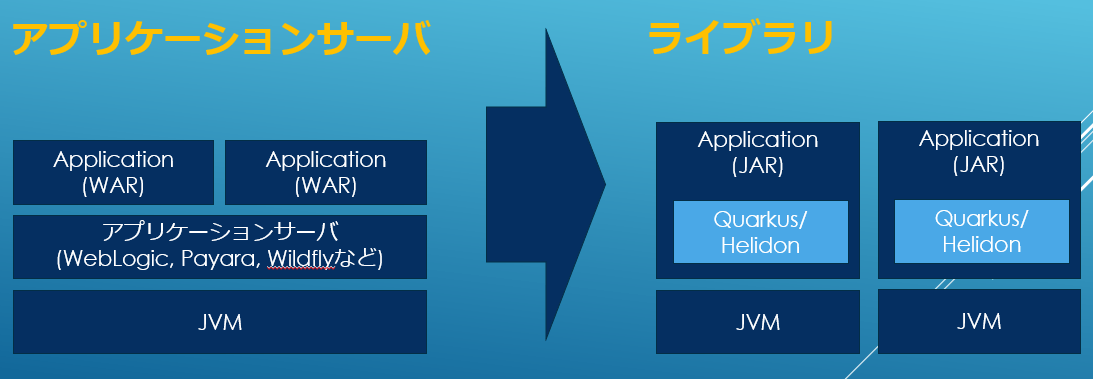
こうする事で、単純に重複が無くなるだけではなく、シンプルなアプリケーションとして罠も少なく開発もしやすいモジュールを作る事が出来ます。このあたりはSpringBootが先行していた部分ですね。
なんにしてもk8sを前提にする事でHelidonやQuarkusはかなりシンプルな作りを実現しています。逆に言えばk8s無しでこれらを使うのは間違ってる分けではないですが別途オーケストレーションレイヤーを用意してやらないと運用時には機能不足になるかと思います。
EEの異常な愛情 ~ または私は如何にして心配するのを止めて起動時間を愛するようになったか
QuarkusやHelidonのWebページに行くと奇妙な事実に出会います。それは起動時間の短さを異常に強調している事です。QuarkusはおそらくSpringBootと思われる伝統的なJavaのクラウドネイティブスタックが10秒なのに対して、うちは2秒で起動する! いや、GraalVMのNative Imageを使えばミリ秒だ! と言っています。Helidonも似たような主張ですね?
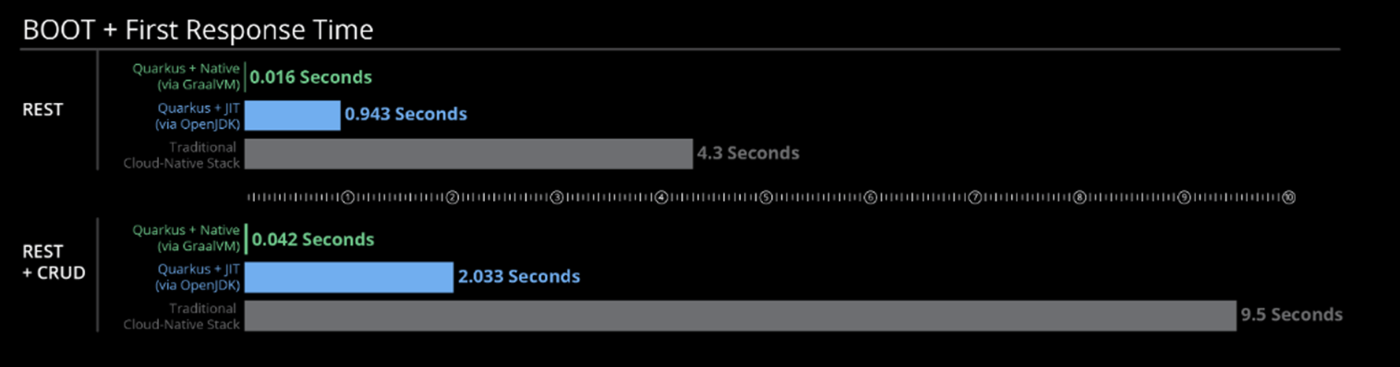
たしかに起動時間はDX (Developer Experience) の観点で重要です。巨大なWARを伝統的なAPサーバにデプロイすれば数十秒どころか分オーダーもザラです。それはEclipseの起動時間にコーヒーを淹れに行ってた古えではなく現代でもです。その点から考えると10秒になるのは劇的な事であり2秒はスゴイけど誤差です。0.04秒ともなれば数十倍速くなっていますが体感できるかは怪しいですよね? そもそもユーザに直接影響が出る値ではないので別にデプロイに10分かかっても安定してレスポンスを返せるなら問題無い気もします。嫌だけど。
ここがサーバレスという新しいアーキテクチャではその前提が変わります。サーバレスの定義はいくつかありますが、今回は開発者はサーバを気にせずリソース使用率で考えるのがサーバレスとしましょう。
つまり名前の元祖であるAmazon LambdaのようなFaaS、Cloud Run(KNative)のような CaaS やHerokuやGAEのようなPaaSも含みます。インフラ的にはHWの利用効率とか色々面白い特徴もありますが、アプリからみた最大特徴はスレッドではなくCGIのようにプロセスを逐次起動させる事です。
JavaはもちろんですがRubyだろうかPHPだろうがJSだろうがGoだろうが、ほとんどのWebアプリケーションは以下の用な常駐プロセス型のモデルを取ります。

プロセスを常駐させて、その中でスレッドなど何らかの並行性を管理する機能を使ってリクエストを順次処理していくわけですね。これは古のCGIがプロセスを毎度起動させてそのオーバーヘッドがインフラの負荷になっていたことに対するソリューションです。
一方、典型的なサーバレスモデルでは以下の様にリクエスト毎にプロセスを立ち上げ、終わったら破棄します。
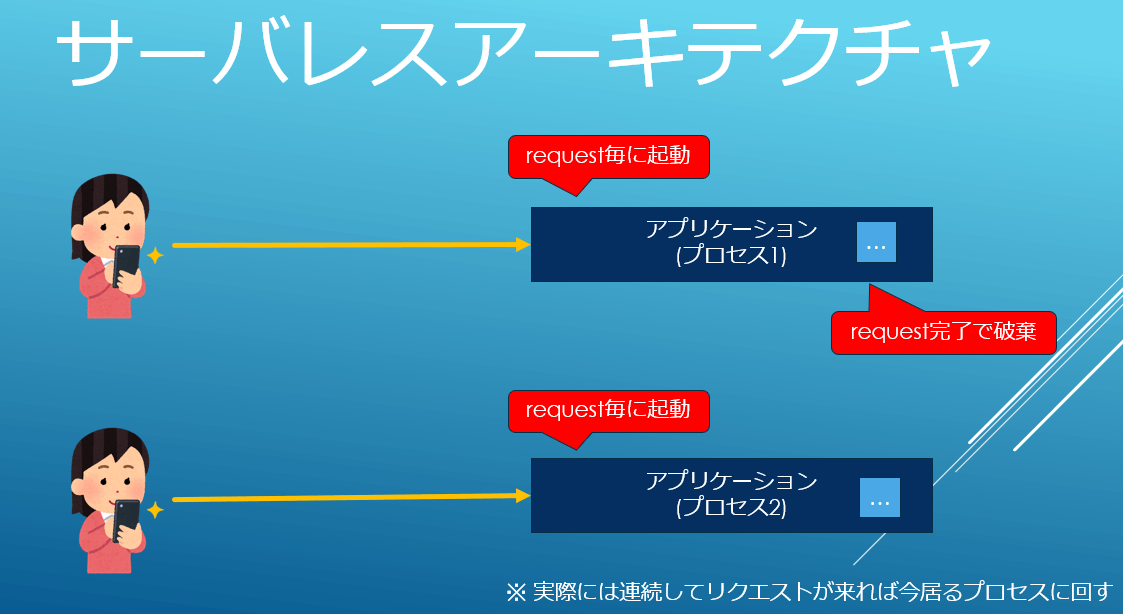
一般的にスレッドよりもプロセスの方がずっと人類にとって並行性の管理が楽なので運用性は高いです。CGIに回帰しているようにも見えますが、当時とはインフラの事情が違います。クラウドにより大量のHWリソースを取り扱える事とコンテナのIsolationとPortabilityを用いた高集約な共有環境がオーバーヘッドの壁をぶち壊します。利用者から見たらオートスケール全振りのアーキテクチャです。
ここでポイントになるのが 「起動時間がレスポンスタイムに含まれる」 という点です。

リクエスト毎にプロセスを起動するという事は当然起動時間が応答時間に載ってきます。なのでここが10秒とかましてや分だと必然的に応答時間も10秒以上になるわけですね。これはとても受け入れられません。だから起動時間を2秒、あるいはミリオーダーにする事に大きな価値が生まれるのです。
なお、実際には1プロセスである程度は複数リクエスト捌けたり、リクエスト終了直後に破棄せずに次のリクエストを回す、などペナルティを小さくする工夫は行われています。また、プロセスが分かれているのでインメモリの情報も共有されません。そのため起動時に大量のファイルを読み込むようなデザインやキャッシュを多用するデザインとは相性が悪いのでアプリの実装として避ける必要があります。
このような前提があるのでJIT性能がHotSpotに比べて悪く、ビルド時間も膨大に伸びるGraalVM Native-Imageを使ってでも起動時間を短縮するモチベーションが生まれることになります。
プラクティカル・サーバレスEE
ここからはQuarkusを実際にサーバレス環境のCloudRunにデプロイして、どのような機能が役に立つのか、あるい運用に必要な構成をどう作るのか?を解説していきます。
MP Configによるデプロイ時に設定値を上書き
Javaでは長らくMavenのプロファイル機能を使いビルド時に読み込むリソースファイルを変更する事で、開発環境と本番環境で使う設定の切り替えをビルド時に解決してきました。これは非常に便利なやり方ですが設定の差分がわずかでもとりあえず設定ファイルは全環境分作る必要があるので、保守の観点ではやや負担になっていました。また、ビルドをし直すのでテストしたモジュールと本番にリリースするモジュールが厳密には同じではない、という問題もありました。依存ライブラリのバージョンが変わるとか差分が入り込む余地がある、という事です。一方、MP Configでは12factorに則り、環境の違いは環境変数でリリース時や実行環境で解決します。
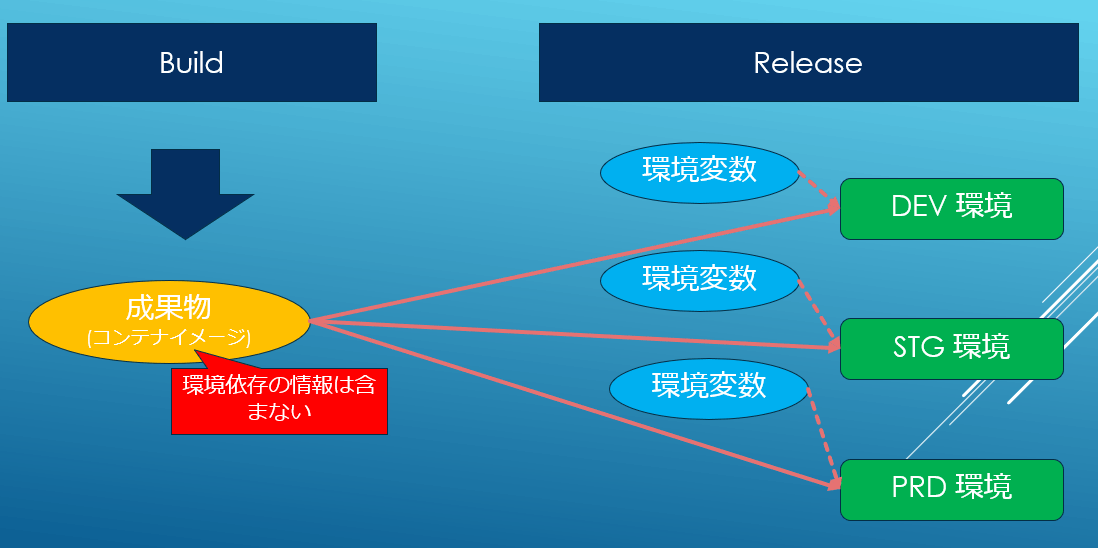
MP Configは設定ファイルの値を環境変数で上書きできるため、ビルド時ではなくリリース時あるいは実行時に環境差分を解決可能です。これによって同一のバイナリをどの場所にでもデプロイする事が出来ます。また差分だけを環境変数として管理すれば良いので保守もぐっと楽になります。このあたりは最近のCI/CDの前提なのでエコシステムとも統合しやすくなると思います。
それでは実際に使ってみましょう。src/main/resources/application.propertiesが以下の様に設定を書きます。
quarkus.http.port=8080
quarkus.http.cors=true
quarkus.http.cors.origins=http://localhost:3000
quarkus.http.cors.methods=GET,PUT,POST,DELETE
quarkus.smallrye-jwt.auth-mechanism=MP-JWT
mp.jwt.verify.issuer=https://securetoken.google.com/xxx
tasknotes.gcp.project=GCP_PROJECT_ID
tasknotes.gcp.bucket.image=GCP_BUCKET
tasknotes.gcp.bucket.data=GCP_BUCKET
これはコーディング中では以下のように参照できます。XMLやYAMLで設定ファイルを自作したときと違ってパース処理がなくアノテーションで簡単にマッピング出来るのは便利ですね。
@ConfigProperty(name = "tasknotes.gcp.bucket.image")
String bucketImage;
開発環境では設定ファイルの値で良いのですが実際に実行する時にはいくつかのパラメータは本番のモノに上書きしてやる必要があります。Cloud Runを利用する場合は以下のように環境変数で上書きする事が出来ます。環境変数とプロパティ値のマッピングルールとして大文字に変換してドットを_に変更することができより自然な環境変数として使えます。
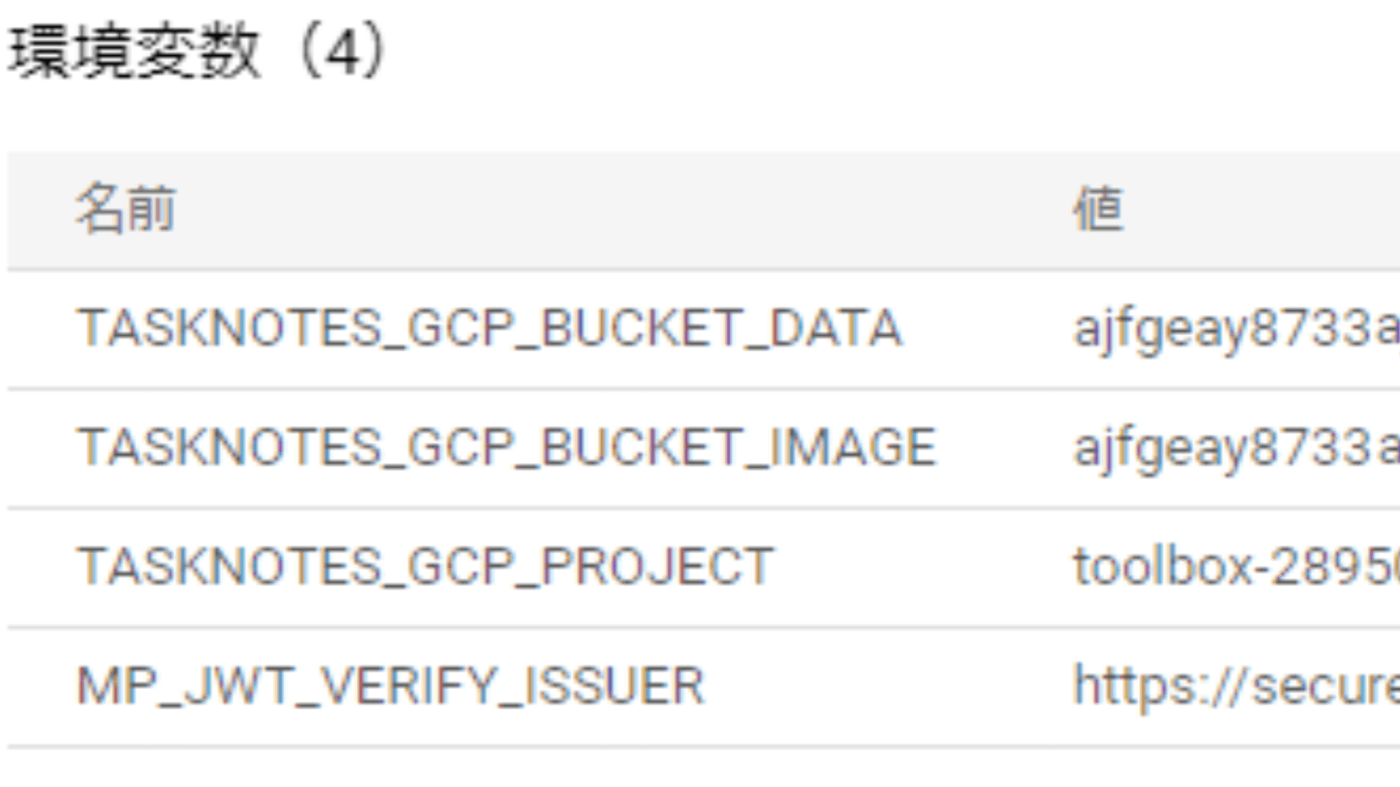
これでパラメータが本番のモノに上書きされます。もちろんコードの変更は必要ありませんし、ビルドしなおす必要もありません。Cloud Runではデプロイ時にコンテナに渡す環境変数が指定出来るので同一のモジュールを様々な環境にデプロイするのに非常に向いています。これはCloud Runに限らずDockerコンテナがそのような運用のされ方を想定しているのでMP Configはk8sや他のサーバレスなど様々なプラットフォームにマッチするデザインです。MPの中で一番好きな仕様ですね。
MP Configでシークレット情報の取り扱い
実はMP Configを使ってパスワードのようなシークレット情報もCloud Runでは簡単に取り扱う事が出来ます。パスワードを設定ファイルに記載しておくとコードのセキュリティ上の取り扱いが厳しくなりますし、環境変数で上書きするにしてもリリース担当などのオペレータに見えてしまいます。典型的なアンチパターンです。このような場合高いセキュリティレベルを実現するためにもHSMやSWベースの秘密管理システムを使うのが一般的です。GCPではSecret Managerがその役割を担います。
Cloud RunはSecret Managerをネイティブにサポートしているのでコンテナ上の環境変数やファイルに秘密情報をマップできます。環境変数にマッピングすることでコード上は普通の設定ファイルと何ら変わる事なく秘密情報をMP Configで利用可能です。まずは以下のようにGCPのコンソールからSecret Managerに適当な秘密情報を入れます。
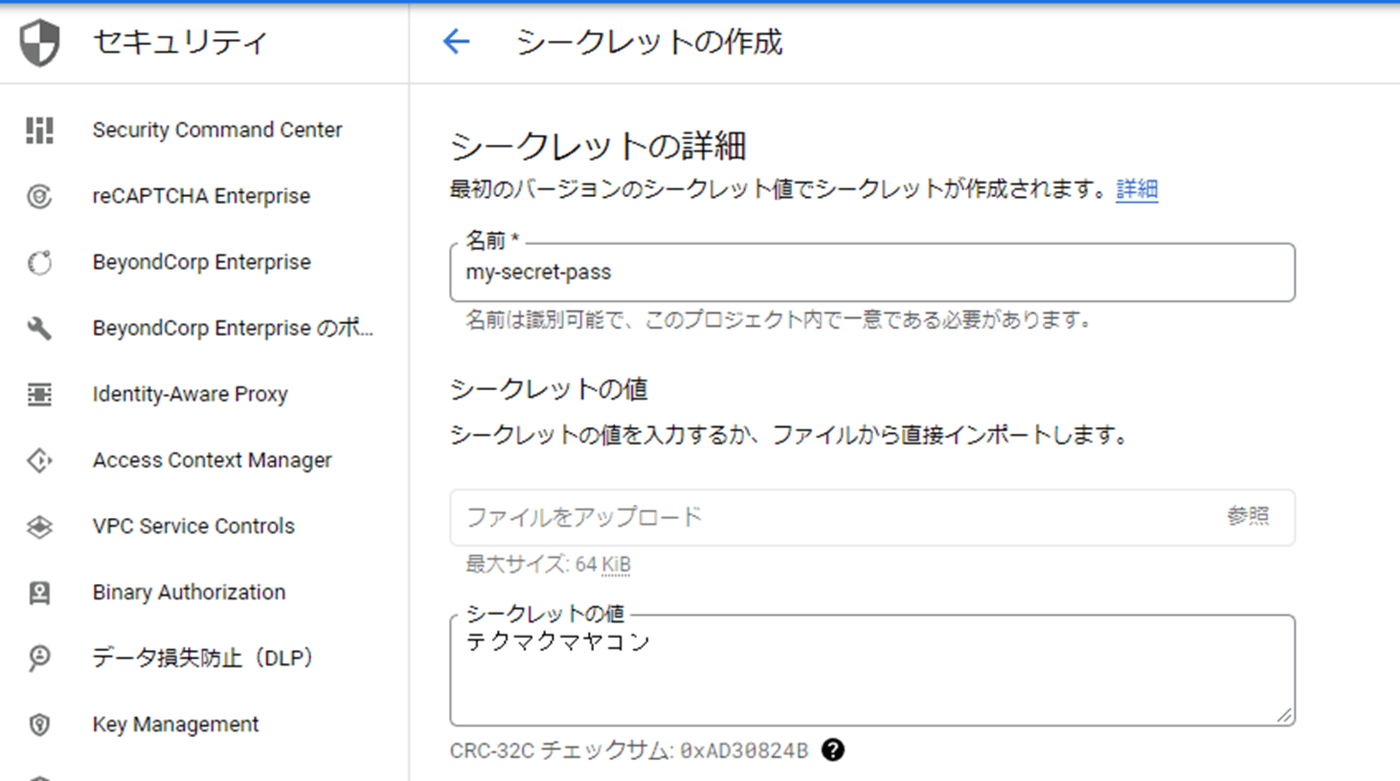
これを次のようにCloud Runで任意の環境変数にマッピングします。

コード上では以下のように参照できます。ローカル環境などSecret Managerを用意するのが難しい環境でも単に環境変数としてダミー値を渡せば良いので簡単ですね。
@ConfigProperty(name = "my.secret.pass")
String password;
ログ管理
続いで本番運用で忘れてはいけないログ管理や監視に関する部分です。まずは基本のログから行きましょう。実はCloud Runというかk8sを含めたコンテナの運用ではアプリケーションログの管理はアプリケーションの仕事ではありません。Twelve Facotrでは単純に標準出力に出すことが推奨されています。
従来であればログをファイルとして出力してサイズごとや日付毎にローテションするなど結構な部分がlog4jなどのログライブラリの役割でした。しかし最近ではSplunkやKibanaを始めとしたログ管理ツールを使うのが当たり前になって来たのでサーバに入ってログをgrepするというシーンも減ってきました。またコンテナは寿命が短く、エフェメラルな名前でアクセスする必要があります。そのためSSHなどで入るのには向いてませんし、大きなサービスではログも巨大になりその場でgrep/awkをするのは不適当です。こういった事情を加味してQuarkusにもログ周りはさほど特別な仕組みは無く、標準出力に出すことでCloud Run上で以下のように管理できます。
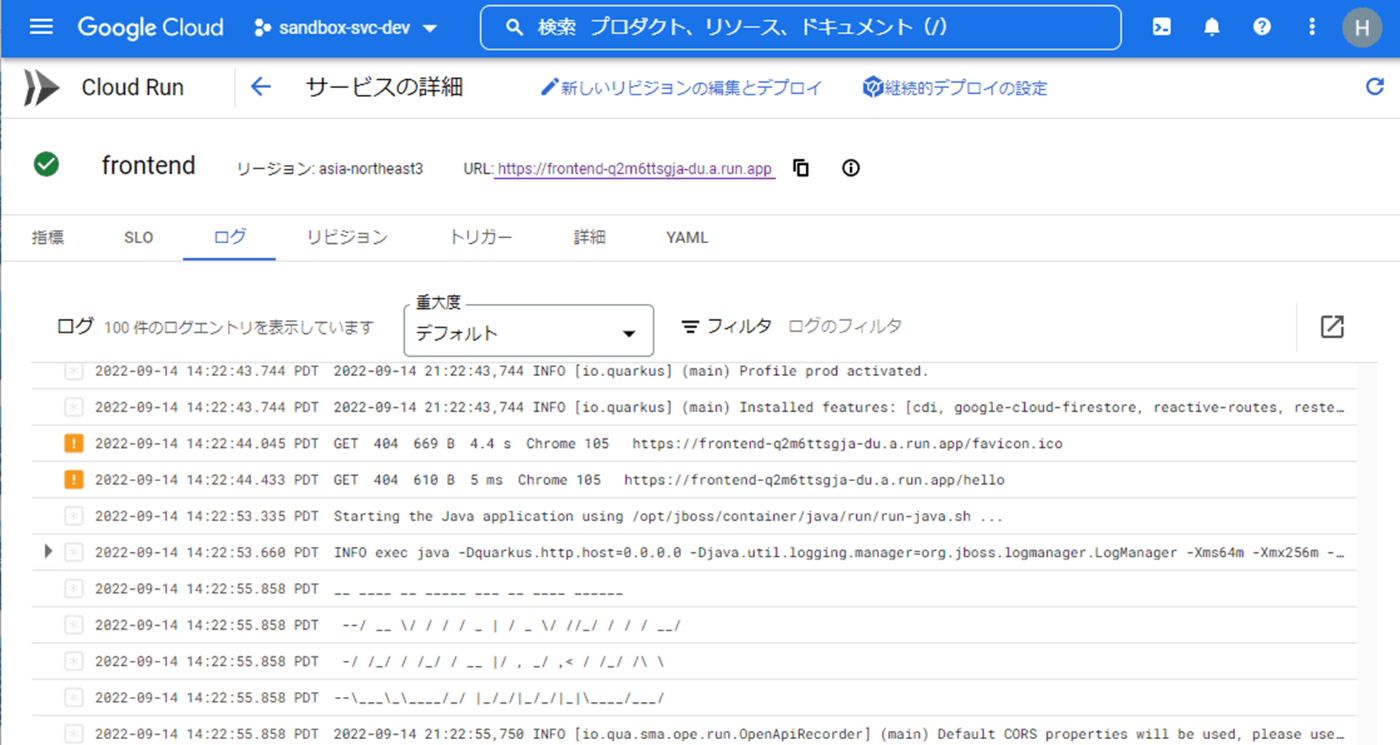
Cloud Runの標準出力は自動的にCloud Loggingに連携されています。そのため上記のようにCloud Runの管理コンソールから見る事も出来ますし、以下のようにLoggingのコンソールからクエリを書いて複雑な抽出を行う事も簡単に出来ます。
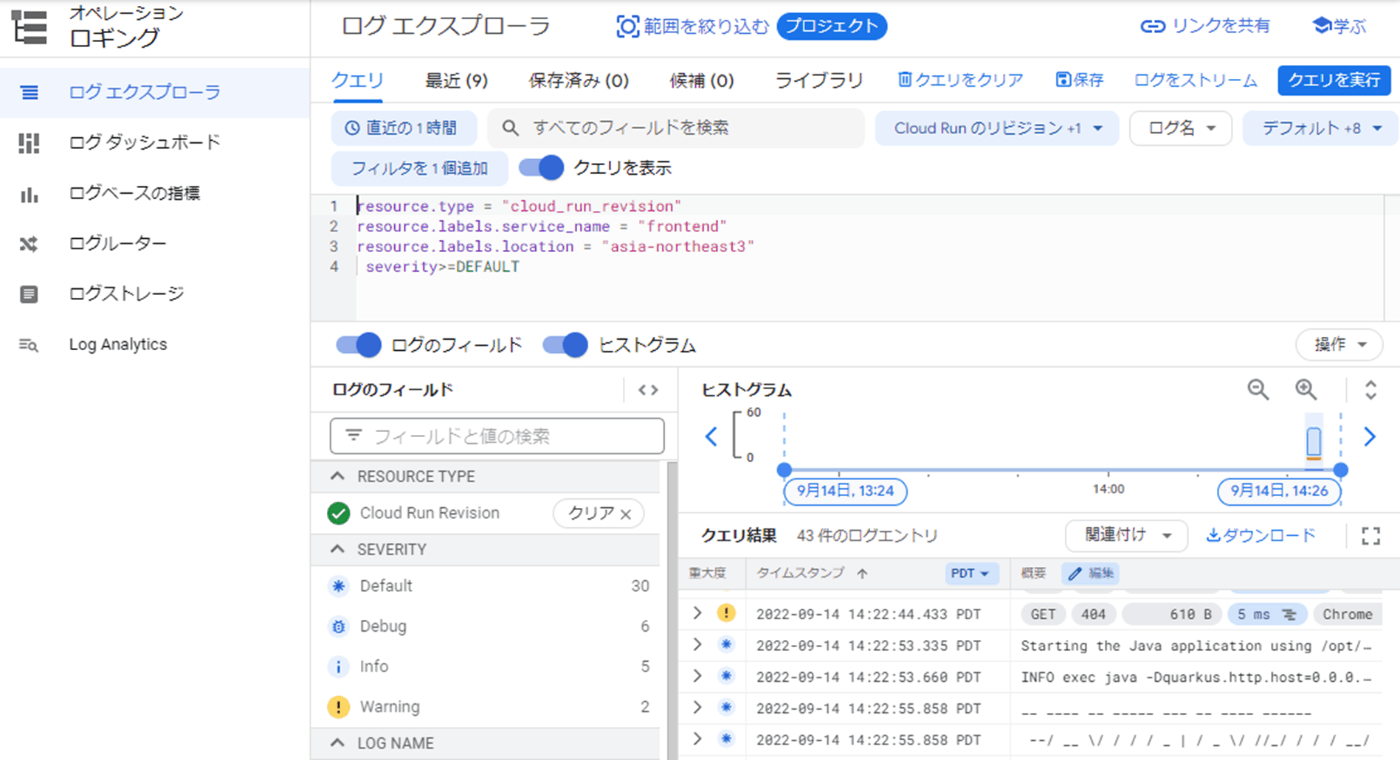
自分でfluentdやELKを入れる必要が無いのは良いですね。Cloud Runに限らずコンテナ利用ではこのような運用が基本なのでk8s上でログをファイルに出すのはアンチパターンになりやすいので避けるようにしましょう。
監視
ログ管理と並んで運用の基本は監視ですよね。従来もNagiosやZabbixなど様々なツールで監視をJMX等を使ってリソースの監視をするのがJavaの基本でしたよね。現在はSNMPやJMXよりもよりアプリ監視に特化したプロトコルとしてOpenMetricsが好まれます。これは元々Prometeusという監視ツール向けのフォーマットで、テキストやProtocol Buffersを用いて汎用的にメトリクスを取得できます。MPでもこちらをサポートしたMP Metricsがあります。あるのですが実はCloud Runでは有効に使う事が出来ません><
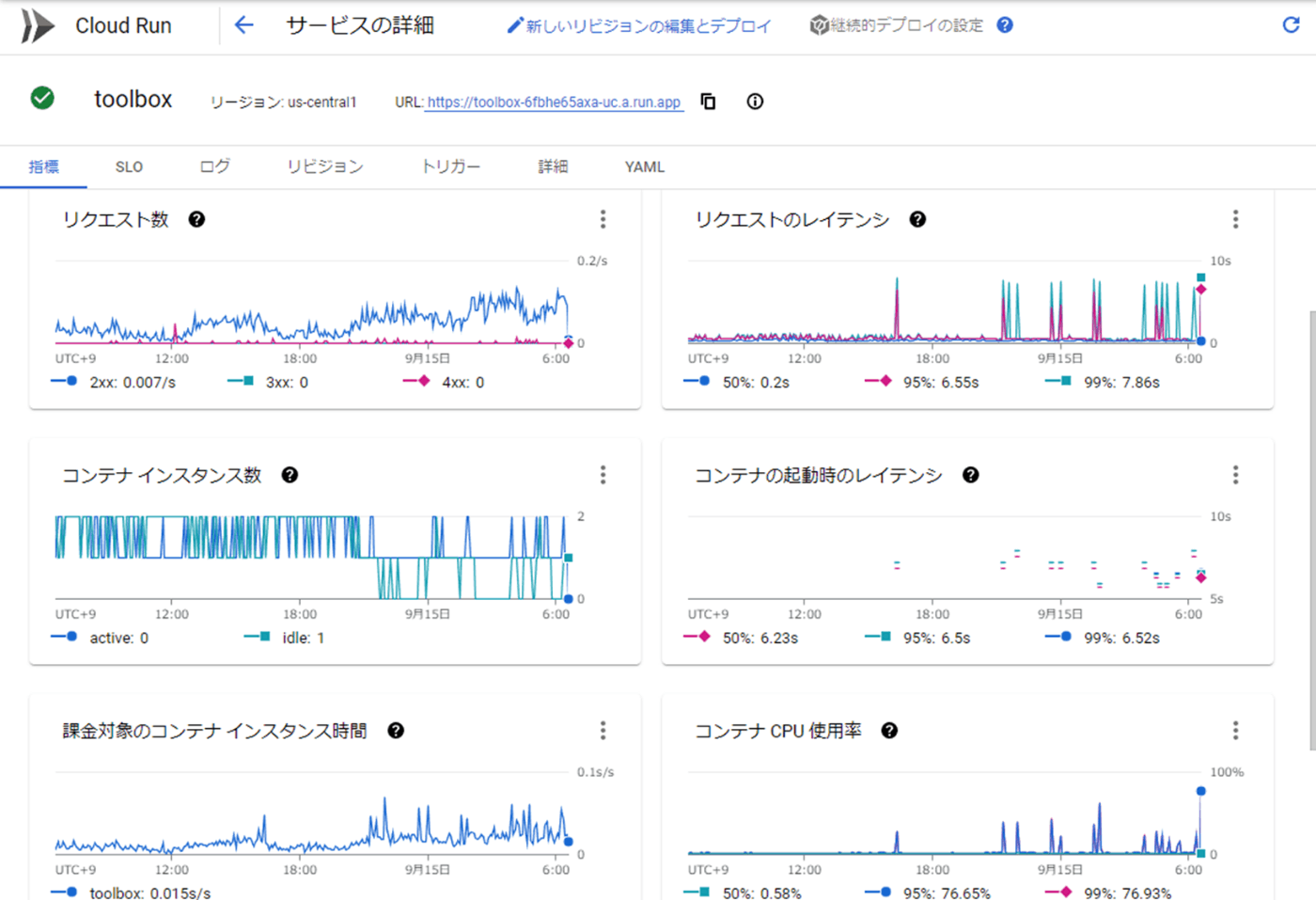
Cloud Runでは上記のように標準のメトリクスとしてSLIによく使われるようなレスポンスタイムやアクセス数、CPUの利用率やメモリなど様々な情報が取得できます。しかし現時点ではOpenMetricsのようなカスタムメトリクスを使った監視はサポートされていません。
そのためガベージコレクションやDBへのコネクション数などJavaやアプリケーションに固有の情報が取得できないという問題があります。一応、ログに出力してCloud Logging側で分析するというアプローチは可能ですし、CloudMonitorとは別のサードパーティの監視ツールでチェックする事も可能です。ただし、サーバレスでは寿命が短いので従来のアプリケーションに比べるとGCなどの情報の優先度が低い、という点を踏まえてトレードオフでの導入を検討するのが良いと思います。
分散トレーシング
ここ数年は分散トレーシングという言葉が話題になっています。これは複数の異なるアプリケーションで1つの大きな(広義の意味の)トランザクションを作る時に、一連の処理としてログやエラー、性能情報などをトラッキングするための仕組みです。2010年のDapperの論文を皮切りにOSSの実装であるZipkinなどが登場し一気に普及し、それを標準化する仕様のOpenTracingが登場するなど大きな発展を遂げました。
以下のスライドが詳しくそのあたりを説明されています。
APをフロントエンドとバックエンドに分けるケースは以前から存在しており各社独自のID(リクエストIDとかトレースIDとか色んな社内用語があったはず)をリクエスト毎に振ってそれでログをgrepするとかは良くされていたと思います。タイムスタンプだけだとAPを超えてトラックできあにので。
最近はマイクロサービス化の流れもありアプリケーションのスタックトレースだけではとてもじゃないけど追いきれない、という点から標準的な分散トレースが普及したのかと思います。
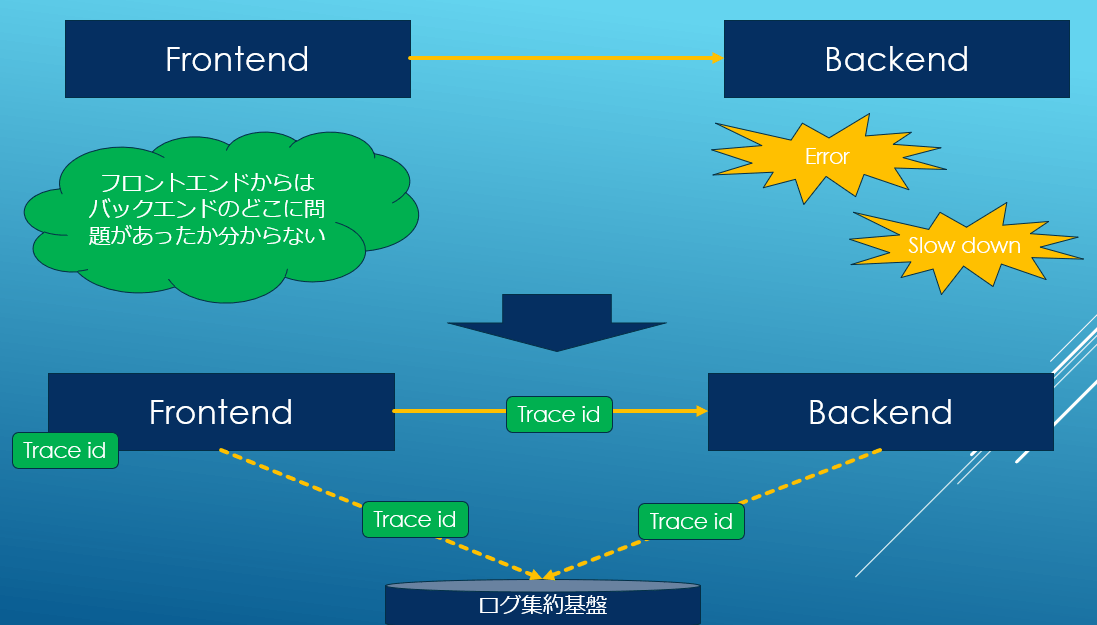
そしてOpenTracingとは別にOpenCensusと呼ばれるGoogle由来の分散トレーシング(+メトリクス)の仕様も登場しました。どちらも人気がありましたが、似たようなものが複数あるのは好ましくないので、OpenTelemetryという形で統合されました。これにはDynatraceやNewRelicのような独自で分散トレースを実施していたAPMベンダーも参加しているので広く共通的に利用できる仕様になりつつあります。しかしながら去年の5月に1.0が出たばかりで、まだ各自の対応状況はまちまちです。

MicroProfileも次世代の6.0ではOpenTelemetryをサポートする予定ですが現在はサポートしていません。Quarkusは独自にOpenTelemetryのサポートをしているのですが2022年9月現在ではExpoterがOpenTelemetry Protocol (OTLP) のみの対応しており、GoogleのCloud TraceはOTLPをサポートしていないという複雑な状況があるため、そのまま利用することは出来ません。なので、現時点ではシンプルに直接OpenTelemetrlyのJavaライブラリとGCPのCloud Trace Exporterを直接使うのが簡単です。
まずは以下のようにpom.xmlにopentelemetry-api, opentelemetry-sdk, exporter-traceの依存を追加します。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-bom</artifactId>
<version>1.17.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
...
<dependencies>
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-api</artifactId>
</dependency>
<dependency>
<groupId>io.opentelemetry</groupId>
<artifactId>opentelemetry-sdk</artifactId>
</dependency>
<dependency>
<groupId>com.google.cloud.opentelemetry</groupId>
<artifactId>exporter-trace</artifactId>
<version>0.23.0</version>
...
利用する際には以下のように初期化をまず行います。
var googleExporter = TraceExporter.createWithConfiguration(
TraceConfiguration.builder()
.setProjectId(“PROJECT_ID").build());
var tracerProvider = SdkTracerProvider.builder()
.addSpanProcessor(SimpleSpanProcessor.create(googleExporter))
.build();
var openTelemetry = OpenTelemetrySdk.builder()
.setTracerProvider(tracerProvider)
.setPropagators(ContextPropagators
.create(W3CTraceContextPropagator.getInstance()))
.buildAndRegisterGlobal();
使う場合は以下のようにSpan#start, endの間に計測したい処理を書きます。
var context = dt.getContext(headers);
var msg = "";
try (Scope scope = context.makeCurrent()) {
var span = dt.getTracer().spanBuilder(“call firestore").startSpan();
try {
msg = service.run();
} finally {
span.end();
}
}
ちなみにトレース情報は以下のようにHTTPのヘッダに載せることで後続のアプリケーションに伝搬させることが出来ます。
var context = openTelemetry.getPropagators().getTextMapPropagator().extract(Context.current(), headers, getter);
var client = HttpClient.newHttpClient();
var request = HttpRequest
.newBuilder(URI.create("バックエンドURL"))
.header("accept", "application/json")
.GET();
openTelemetry.getPropagators().getTextMapPropagator().inject(Context.current(), request, setter);
var response = client.send(request.build(), HttpResponse.BodyHandlers.ofString());
これにより様々なアプリケーション、可視化ツールで分析をするこが出来るようになります。ベンダーロックインされないのは嬉しいですよね!
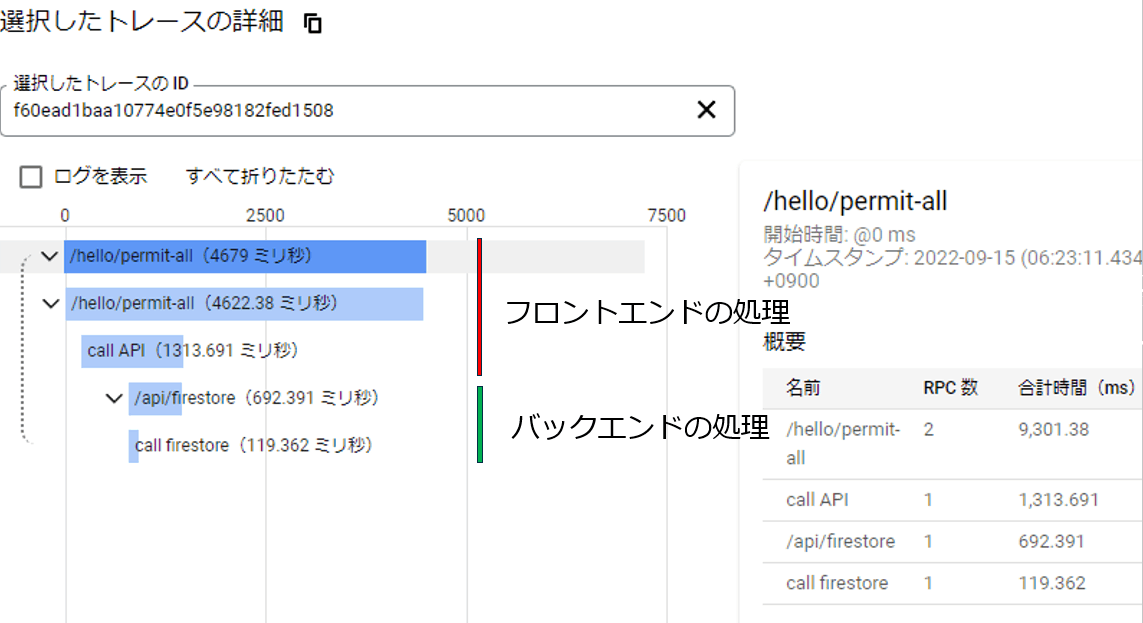
Cloud Traceで見た場合には上記のようになっており、フロントエンドとバックエンドの処理が一連の処理として可視化されいて、どこにどのくらいの時間が掛かっているかが一発で分かるのは非常に便利です。
GraalVM/native-imageによる起動時間の高速化
起動時間がサーバレスではレスポンスタイムに含まれる事があるので非常に重要であることはすでに開設しました。このスピンアップタイムはGAEのようなPaaS時代からJavaエンジニアを悩ませてきました。しかし、今我々にはnative-imageがあります!
native-imageは高速なJava及びその他言語のVMであるGraalVMの目玉機能の一つであるJavaのAOT (Ahead-Of-Time) での ネイティブイメージへの変換です。
Javaは中間言語をJVMでインタプリタ的に実行しJIT(Just in Time) コンパイラで最適化して高速に実行することは良く知られています。一方で、その反面起動時間がGoやCに比べて遅い事も。native-imageはJavaをx86/Linux等の実行ファイルにAOTコンパイル、つまりCやGoのように普通に機械語にそのタイミングで変換する方式です。そのため非常に高速に起動しメモリ使用量も小さい、という特徴を持ちます。一方でほとんどの処理がピーク性能ではJITで最適化したJVMにはかないません。しかし、これは毎回起動しJITの効果薄いサーバレスには最適の方法です。QuarkusやHelidonも推奨しているのでガンガン使っていきましょう。
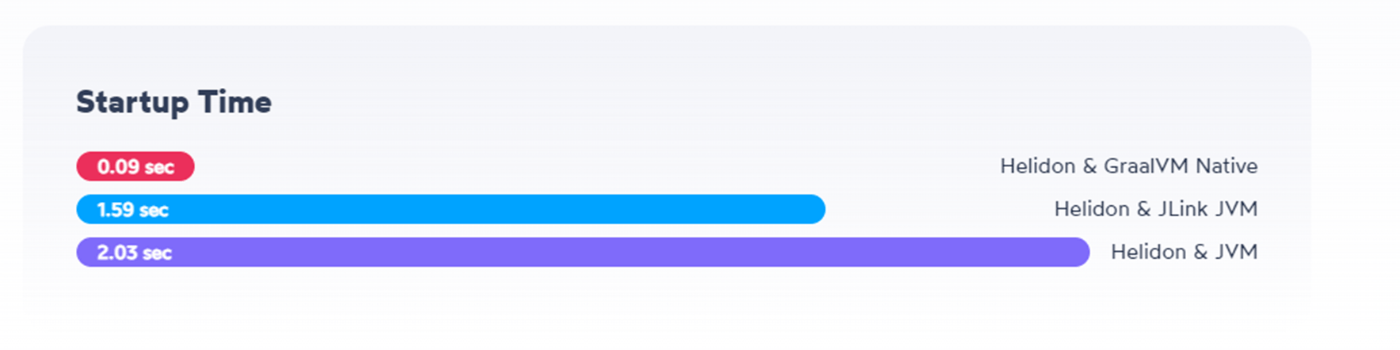
以下は私が作ったサンプルアプリのCloudRun上での起動時間を含むレスポンスタイムの比較です。ネイティブイメージが極めて速いことが分かりますね。
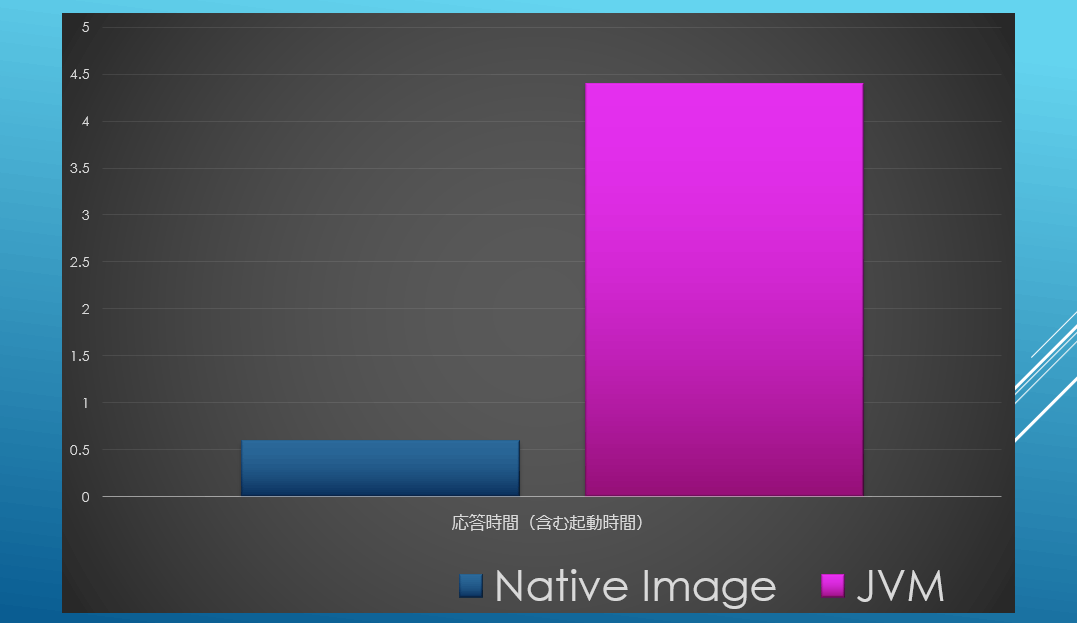
しかし、native-imageの利用には結構険しい道のりがあります。というのも元々JavaはJVMのようなプラットフォームを想定して設計されておりAOTではリフレクションを含めたいくつかの機能に制約が入ってしまいます。そのため特にサードパーティのライブラリを使うときには注意が必要です。ビルドエラー祭りになります。
幸いにもGCPのライブラリに関してはGoogle側でサポートライブラリも出していますし、Quarkusもそれを前提としたExtentionを持っているのでそちらを使う事で簡単にNative-imageに対応が出来ます。
以下のようにpom.xmlを修正します。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>io.quarkiverse.googlecloudservices</groupId>
<artifactId>quarkus-google-cloud-services-bom</artifactId>
<version>1.2.1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
...
<dependency>
<groupId>com.google.cloud.opentelemetry</groupId>
<artifactId>exporter-trace</artifactId>
<version>0.23.0</version>
<exclusions>
<exclusion>
<groupId>io.grpc</groupId>
<artifactId>grpc-netty-shaded</artifactId>
</exclusion>
</exclusions>
</dependency>
基本的にはquarkus-google-cloud-services-bomを呼んでおけば問題ないのですが、expoter-traceはその中に含まれていないので独自でgrpc-netty-shadedをexcludeする必要があるので忘れないでください。これでバッチりCloud RunでEEライフを楽しむことが出来ます。
まとめ
今回はQuarkusやHelidonのような新しいEE実装が何故登場したのかを、最近のWeb開発のトレンドを踏まえながら解説をしました。また、後半ではCloud Runというサーバレス環境でどのようにQuarkus/MPを運用していけば良いかの具体例をいくつかあげました。MPには様々な機能があるので今回の説明だけでは足りませんが、何かの参考になれば幸いです。
最後に、今回はJakartaOneというイベントにアバターのまま登壇させていただき、本当にありがとうございます。以前より、VのままこういうITイベントに登壇してみたいと思っていたので夢が一つかなった気分です。私の発表以外にもたくさんのセッションもあるので、ぜひ皆さん見てみてください。
それではHappy Hacking!
Discussion