運用出来るWebアプリケーションの作り方
はじめに
先日、下記のようなツイートを見つけて、そういえば趣味で個人開発してたときには然程気にしてなかったけど、仕事で運用するようになって先輩たちから学んだり自分で身につけたチップスってちょこちょこあるよねー、とふと思ったので、Webアプリケーション開発に関わるものをいくつかまとめてみました。
特に体系的/網羅的という程でもないですし、最近はFWや色々な仕組みでカバーされてるものも多いですが備忘録として。
Tips
機械が読めるログを作る
これは割と重要なのですが、ログは人間が読むものではなく機械が読むものです。それはZabbixだったりDatadogだったりSplunkだったりgrep/awkだったりツールは何でも良いのですが、古の時代はさておき現代ではログは機械が読めることが最重要です。
まず大前提として構造化されている必要があります。言うまでもないですが「フリーフォーマット」のログの解析は地獄です。スペース区切りだったり、カンマ区切りだったりが入り混じり、そもそもログの書き方の一貫性がない。これは大変運用泣かせですね。ログ周りはきちんとライブラリ化して必要なパラメータを入れたら固定のフォーマットで出るようにしておくのは重要でしょう。
ではどのようなフォーマットにすれば良いのか? とても小さな例ですが以下の2つのアクセスログのフォーマットを見てみます。
A:
2023-07-07 12:00:00 /top 50ms
2023-07-07 12:00:00 /login 120ms
2023-07-07 12:00:00 /top 30ms
B:
2023-07-07 12:00:00 /top 50 ms
2023-07-07 12:00:00 /login 120 ms
2023-07-07 12:00:00 /top 30 ms
人間が見る分にはどちらも大きく違いません。しかし、機械に優しいのは断然 B です。何故ならたとえば A のログを集計して平均実行時間を出そうとすると一度「 ms 」を削らないといけません。一方、後者であればカラム位置の理解は必要ですが単なるスペース区切りで必要な情報を取り出せます。小さな点ですが、こういうのが積み重なって機械の読みやすいログ、を実現することが出来ます。
もう少し工夫をしてみましょう。スペース区切りには以下の課題があります。
- 「スペース」はありふれてるので、デリミタとして使うと誤爆することがある
- ログのカラムの順番を強く意識しないといけない、値を追加しづらい
1は文字通りで例えば上記の例でもタイムスタンプ中で日付と時間の間にスペースがあったり、エラーなどのようにログにメッセージが入るパターンだとスペースが含まれる事は自然であり 意図しないタイミングで区切る 事になります。もちろん、ちゃんとエスケープ処理等をすれば良いのですがログ解析のたびにそんな事いちいちやってられません。そこで便利なのが「タブ」です。タブをエラーメッセージ等に使うことはレアケース(※個人の所感です)なので、乱暴にタブでsplitしても誤爆する可能性はとても低いです。これでログの解析処理がぐっと簡単になります。
つづいて2ですが、例えば先程のアクセスログにHTTPのレスポンスコードを入れてみましょう。
2023-07-07 12:00:00 /top 200 50 ms
2023-07-07 12:00:00 /login 500 120 ms
2023-07-07 12:00:00 /admin 404 30 ms
上記のようにPathの後ろにコードを追加、みたいなことは してはいけません 。何故なら既存のログパーサーがカラム順序の変更に伴い壊れるからです。とすると常に最後尾に追加するしかないのですが、それもそれで人間に分かりづらいですし、そもそもログの仕様がわからないとパーサー書けません。なので、例えばXMLのような自己記述型のデータ構造があると非常に便利です。
上記をお手軽に実現する方法の一つがLTSVフォーマットです。タブ区切りだし、キー名でアクセスすれば順序関係なくアクセスが出来ます。
time:2023-07-07 12:00:00 path:/top status:200 response(ms):50
time:2023-07-07 12:00:00 path:/login status:500 response(ms):120
time:2023-07-07 12:00:00 path:/admin status:404 response(ms):30
一昔前に流行ったフォーマットですが、解析も簡単ですし何より実装も簡単なのでシェルスクリプトなどちょっとした処理に使うのには今でも非常に便利です。
では現代なら何がおすすめか? JSONL(JSON LINES) です。LTSV も良いのですが 正直マイナーフォーマット なので簡単とはいえ自力で色々対応しないといけないのですが、JSONLであればログライブラリ自体が対応してることも多く、解析は選り取り見取りです。というわけでログのフォーマットは変更出来るならJSONLにしておくと幸せになれるでしょう。awk派の人はjqと和解してください。
※ コメントでJSONLとJSONは違うよ、と指摘を頂いたので修正しました。
余談ですが、Webアプリでは滅多に見ないと思いますが以下のような複数行に渡るログは現代では禁じ手なので絶対にやめましょう。
**error**
2023-07-07
Somthing error
code 999
**end**
こういう奴。古のバッチとかでは偶に見かけますがZabbixとかとの相性が最悪です。でも例外のスタックトレースとかでやりがちなんですよね... 改行死すべし><
一連のログを紐付けよ
次の話題ですが、またもやログです。一言でログといっても様々なものがありますよね? アクセスログやエラーログ、性能やアプリケーションの振る舞いを書いたシステムログ、ユーザの行動を書いたトレースログなどなど。アプリケーションにより「どこまで取るか?」「どこに取るか?」という点はまちまちですが上記のような観点は考慮されるはずです。
こうした様々なログがありますが基本的には独立した1行のレコードですが、エラーやスローレスポンスがなどインシデントが発生したときに一連の処理を紐づけてやる必要があります。
例えばスローレスポンスが発生していたとして、それはどのユーザでしょうか? 別途発生していたエラーと同じリクエストでしょうか? そのタイミングのDBクエリやAPIコールが特別遅かったりしたでしょうか? などなど。問題の調査をするためにはログの相関を紐付けるのは必須です。
もっとも原始的な手段はタイムスタンプです。「同じ時間に発生したログは同じログだろう」と推測で名寄せをするわけですね。ただ、これはかなり欠点があって、スローレスポンス系だとアクセス開始タイミングと実際のエラーのタイミングに時間差があるのは普通ですし、ミリ秒オーダではそうでなくてもずれがち。一方で秒オーダだとリクエストがそこそこあると重複がすぐに発生するので、実用するのは厳しいです。
というわけで考えるのが各組織で「リクエストID」とか「トレースID」とか色んな名前で呼ばれるテクニックですが、その名の通りリクエストの最初でランダムな値をIDとして生成し、そのトランザクション内の一連のログにこのID(※以後リクエストID)を入れる方法です。リクエストIDでフィルタすると各種ログが簡単に紐付ける事が出来ます。しかもマイクロサービスのようにアプリケーションが別れていても、APIコールの引数やヘッダでリクエストIDを渡す事で分散トレースを実現することが出来ます。可視化はSplunk何かを使うと簡単ですね。
実装としては引数のパラメータに毎回渡すか、スレッド(ないしは並列処理基盤の)のローカル変数等に渡すなど少々ややこしい点はあります。また、特に注意なのがIDの生成方法です。重複が発生すると分析が面倒なので標準の乱数生成関数等ではなく、UUIDなどのユニークな値を生成する方式を採用しましょう。
と、ここまで書いたのですが最近であれば、このようなテクニックは一般的なものなのでOpenTrace及びその後継であるOpenTelemetryにて標準化されています。
こちらを採用することでリクエストIDの生成や伝搬も自動でやってくれますし、可視化もJaegerのようなOSSや様々なツールで対応していて勝手にいい感じに可視化してくれます。よほどの理由がない限り使わない手はないでしょう。
エラーログの設計、オオカミアラートに注意
ログ、特にエラーログの設計は非常に大事です。その中でも特に気にしないと行けないのが誤検知というか、何でもかんでもアラートで引っ掛けることです。
アラートの対応方法は大きく分けて以下のようになります。
- [WARN]静観、連絡なし
- [ERROR]営業日対応、メール/Chat等で連絡
- [Critical]即時対応、オンコール
まあ、これを更に細分化したり社長報告クラスの大障害を定義していたり、呼び方が違ったり、そこらは組織によって様々なでしょうけれど、基本は同じです。
これらの分類を人間がやるのかPagerDutyのようなシステムでやるのは組織によりますが、いずれにしても下2つは人間がアクションをするのが基本ですから「チェックしたけど実は問題ない」が増えるとどうしても「どうせまた誤検知でしょ?」と感度がゆるくなり、対応の優先度が下がりがち。そして、本当にオオカミとなる障害がやってきたときのアクションが遅れるということが想定されます。人間だから仕方がない。
なので、オオカミアラートを減らすことは監視システムのCPU負荷を下げるとともに、人間の応答速度の維持という品質向上に重要なファクターです。
具体的には地道に対応、特に未知のエラーとして即時対応になったものを必要に応じてより下のアクションレベルに下げる必要があります。あと、ありがちな注意としてはValidationErrorのような業務例外を無闇にエラーログに履くことです。あとは特定のリクエストパラメータの無いアクセス(つまり本来は404や403のエラー)で例外ハンドリングをせずにヌルポエラーとかをログに出してしまう。こうしたものをアラートで受け取ってしまうと加速度的に疲弊します。どうしても異常検知の要因にしたいならWARNとして出力して1分間に100件とか通常と違う数が発生した場合はエラーにエスカレーションする、などの仕組みをセットで用意するべきです。
リクエストは頑張らずに速やかに殺せ
HTTPなどで受け取るユーザのリクエストでなにか異常があった場合は速やかに殺すのがおすすめです。例えばAPIリクエストやDB処理で接続エラー的な物があるとリトライしたくなるのが人情ですよね。
ただ、リトライ処理を繰り返す事で対象システムに更に負荷を掛け、それがさらなるリトライを呼び…という負のスパイラルを回すこともあります。なので、余程必要でなければシステムサイドでリトライするのは避けるべきだと考えています。ユーザのリトライに任せましょう。
他にも通常は1秒もかからないリクエストの場合、タイムアウト値はあまり長くしすぎない方が良いです。間違っても1分とか無限とかにしてはいけません。何かしらの理由で一時的なスローダウンが発生した場合に、リクエストが滞留してしまいキューが詰まります。
待ち行列はある閾値を超えると指数関数的に遅延が発生するという性質があります。結果としてタイムアウトを適切に設定しないことにより大規模な遅延に繋がったりもします。
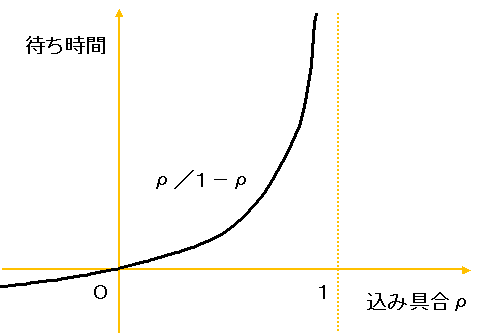
ref:サルでもわかる待ち行列
適切なタイムアウト値を設定してサクサク殺しましょう。混雑ページとか出すのがおすすめ。ユーザがリトライしてくれるでしょう。
こう書くと「ユーザのリトライに期待してはUXが下がりドロップ率が上がる」と考える人も多いかと思います。それは正しいです。が、そもそも上記のような事象が発生して遅延をしている状態はすでにUXを下げています。であれば、システム全体の影響を小さくしてユーザ全体の体験を最大化 する方がマシ です。
ヘルスチェック
この記事を書くきっかけになったヘルスチェック ですね。死活監視 という奴です。
ヘルスチェックとは監視ツールやロードバランサから定期的にリクエストを投げて、そのサービスが生きているかどうかを確認する仕組みです。まあ、curlを特定のURLに投げて200かどうかを確認し続けてる感じですね。
もちろん、監視ツールでのヘルスチェック もサービスの状態を確認する観点で非常に重要ですが、真に気をつけるべきはロードバランサ(LB)からのヘルスチェックです。というのも本当は死んでるのにヘルスチェックで生きていると返してしまうと、LBからそのサーバが自動で外れないため、ユーザが死んでるサーバにアクセスしてしまうリスクがあります。
というわけで、元ツイートにも書かれているように単純に静的コンテンツのHTMLを/healthcheckとかにするとDBアクセスやアプリケーションの基本的な振る舞いに不備がある時にゾンビ状態としてLBに残り続けてしまいます。なので、少なくとも動的ページにするのが最低要件です。そして、ここからはサービスに依存します。DBへの接続を確認するための簡単なSELECTを入れる事が考えられますね。ではMQを使っていたらそのアクセスも? 外部APIはすべて叩く? 申し込み完了メールやSMS出してるならそれも? と考えることが無限にあります。もちろん、全部やれば安心感はありますが、サービス全体としては1秒に1回以上走るヘルスチェックで毎度全てやるのはちょっとしたコストです。もちろん、サービス的にそれらが重要でかつリソース利用に伴うコストも許容出来るなら可能な限りチェックするべきですが、このあたりはサービス毎にバランスを見る部分でしょう。個人的には度のサービスにも入れるのはDBの接続チェックくらいまでかなー。
あと、余談ですが/healthcheckの実装を上手にすることで、例えばDBの値に応じて500エラーを意図的に返すことでLBを操作せずにLBから外す といったテクニックもあります。
リリースと切り戻し
サービス運用で大事なこと、それはリリースです! リリースされてないサービスに障害はなく、リリースされてからがスタートライン。
リリースはサービスをメンテにしておこうなうリリースもあれば、C2B,C2Cでは一般的な無停止リリースもあります。1台ずつ出すローリングリースもあれば、WeblogicのProduction再デプロイメントのようなGracefulなリリース、BlueGreenデプロイメントなど様々な手法がありますが、最も重要なのは切り戻しです。もちろん、安全かつスムーズに出す方法が大事なのは前提なのですが切り戻しは決して忘れてはいけないのです。そうサービスはバグります。速やかな切り戻しはお客様の被害を小さくする最初の方法です。
基本的にはバックアップを取っておいて、何かがあれば戻す、が基本的な考え方です。工夫はそのやり方ですね。スクリプト言語とCapistranoを使ってた時代だとsymlinkを使う方法が便利でした。こういう感じです。
/app/myapp -> /app/myapp20230710/
/app/myapp20230701
/app/myapp20230707
/app/myapp20230710
ファイルをrsyncやgit cloneしなおす事に比べてsymlinkの切り替えは瞬時に終わるのでこれは中々便利な方法でした。
BlueGreenデプロイの場合は少なくともリリース直後の切り戻しに関してはLB等の変更だけで行けるので、これも良いですよね。数日後に戻すとかだと、環境をいつまで残すのか? という話になって少し難しいですが。他にもローリングリリースや、半分ずつ1面と2面に分けて出すのも良いですね。ただ、リクエスが偏るのでメモリ等のリソースはもちろんDBコネクション数とかスレッド数とかの確保にも注意が必要です。
最近はDockerのようなコンテナになり、レジストリから再度出すだけなので切り戻しがしやすくなったと個人的には感じます。昔から似たような仕組みは作っていたけど標準で出来るようになったのは便利! タグ名はちゃんと付けないともちろん駄目ですけどね。
他にもアプリケーション以外にも、テーブルのスキーマ変更は必ず「追加にする」というのもあります。どうしても削除や変更をする時も二段階のリリースにして、利用しなくなってから削除にしないと切り戻せなくなるので。こうした外部リソースが新旧合わせて動くことも切り戻しの重要ポイントです。
新旧モジュールの混在の管理
次もリリースに関連する話ですが新旧モジュールの混在です。完全なモノリスのような構造を除けば、複数のAPIやフロントエンドとバックエンドという形でアプリケーションが連携している構成は良くあります。その場合、基本的にはフロントエンドとバックエンドの新旧が混ざっても問題無いように実装するのが基本ですが、どうしても同じバーション同士じゃないと不整合でエラーになる改修というのは存在しえます。その場合に重要なのが通信が新<>新, 旧<>旧と固定される状態に出来るようにしておくことです。
最初からフロントエンドとバックエンドが1:1の通信ならなんの考慮も要りませんが、通常は間にロードバランサ等が入っていて負荷分散されているでしょう。インフラやアプリケーションはこのような状態を想定して設計される必要があります。
解決方法はいくつも思いつきますが、例えばローカルに特定の設定ファイルがあればロードバランサのVIPではなく、設定ファイルに記載されたバックエンドのIPに直接接続するような実装にしておくとかが一番素朴な感じでしょうか? シンプルなのでよく動いてくれます。最近であればAPIゲートウェイとかサービスメッシュが上手くAPIのバージョニングをしてくれることもあると思います。あと、クラウドなら1セット丸ごと新規に作ってBlueGreenにすることで混在を無くすという方法も考えられます。
困ったらメンテ画面
これは半分冗談ですが、エラー画面をメンテナンス画面にしておくのは一つのテクニックです。特にC2CやB2Cの場合はユーザに詳細なエラー画面を見せるメリットはありません。そのため、通常のメンテ画面とエラー画面を同じ内容にしておくことで、訳の分からないデフォルトの500エラーが出るよりもずっとユーザの印象も良くなります。たぶん。大規模障害でもメンテ中だって言い張れるしね!
まとめ
とりあえず、思いつくままにツラツラと書いてみました。
Webの開発/運用をしていたら大なり小なりみんな似たような事は考えていると思います。個人的には最近はやはり色々成熟してきて、今まで独自にやっていたものがツールがされたり、標準的なしくみが出来たりと、この十数年でも振り返ってみるとどんどん世の中が進化してるなー、と改めて感じる事ができました。
それではHappy Hacking!
Discussion
「機械が読めるログを作る」というのは同意なのですが、
50msよりも50 msの方が良いというのは同意できないです。理由は、まず単位は項目の一部なので意味として分離するべきではありません。
50msは「msを削るだけ」なので機械が読めるログです。機械が読めないログというのは明示的な仕様なしに、ある項目は3フィールド目、ある項目は5フィールド目のように時間が出力され、人間は臨機応変に読み取れるが機械には判断が難しいものだと思います。また
msを削る必要はあまりないはずです。というのは C 言語のatoi関数の時代から数字のみを読み取るという仕様は広く使われているからです。ログの代わりに JSON はおすすめできません。使うなら JSONL (JSON Lines) です。JSONL のことを含めた話をされているのかもしれませんが、JSON にはレコード = 一データ(一行)の終わりという概念がないので随時レコード的な独立した単位のデータが生成され続けるログには不適切です。
コメントありがとうございます & 返信が遅れてしまいすいません。
おっしゃる通りで、たしかにユニットは重要な項目ですし、固定的に出力されているなら固定的に切り出せるので「機械が読めるログ」ですね。個人的な経験から"10ms"と"10 ms"が区別されないログ出力が多かったので、説明の例としてよく使ってました。乱暴にスペース区切りで出来て便利だったので。このあたりは誤解のある表現でした。
それはそれとしてawkって演算時に数値以外無視するんですね。10年前に知りたかった...
JSONの部分は仰る通りで意図してたのはJSONLです。ここはきちんとそう書いたほうが良いですね。ご指摘ありがとうございます。