EffecientWord-Netでカスタムのウェイクワードを学習する
前にRaspberry PiでEffecientWord-Netを動かせるようにしました。今回は独自のウェイクワードを学習させてそれを使用してみます。
前回の記事はこちら(https://zenn.dev/kobayutapon/articles/8282e244104276)
学習の環境
今回は以下の環境で行いました。Raspberry Piでもできそうですが、Githubのissueとか見ているとx86_64環境のほうが安定していそうなので今回はそちらを利用します。
CPU:AMD Ryzen9 7950X
RAM:64GB
SSD:2T
OS:Ubuntu 22.04 LTS
EffecientWord-Netのインストール
Python 3.9環境の設定
EffecientWord-Netを動作させるにはPython3.9の環境が必要です。pyenvを用いて動作環境を構築します。
必要なパッケージを追加
sudo apt install -y liblzma-dev
sudo apt install -y libbz2-dev libreadline-dev libsqlite3-dev
pyenvで環境をインストール
pyenv install 3.9.17
pyenv local 3.9.17
pip install --upgrade pip
pyenv rehash
python -m venv env
./env/bin/activate
※activateスクリプトに実行属性がついてないことがあるので注意
EffecientWordをインストール
sudo apt install -y portaudio19-dev libsndfile1-dev ffmpeg
pip install wheel
pip install typer
pip install rich
pip install "numpy==1.20.0" "librosa==0.9.2" tflite_runtime
pip install EfficientWord-Net
※ライブラリの依存が強いので上記でバージョンを指定してインストールする。(2024/1/14現在)
独自のウェイクワードを学習する
インストール出来たらウェイクワードを学習させます。
学習サンプルを用意する
必要なものは学習用の音声データを準備します。
これは以下のフォーマットで準備すると良いでしょう。
- WAV形式
- 16000Hz, モノラル
- S16LE
学習用サンプルは最低4つ必要です。また、楽手モデルによっては2秒以上必要です。
学習用のデータはまとめて同じディレクトリに置いておきます。
学習をさせる
以下のコマンドを使って学習させます。
python -m eff_word_net.generate_reference [OPTIONS]
オプションは以下を指定します(必須)
--input-dir 学習する音声データが入っているディレクトリ
--output-dir 楽手済みのモデルを出力するディレクトリ
--wakeword ウェイクワード
--model-type 使用するモデル first_iteration_siamese か resnet_50_arc を指定
以下にコマンドの実行例を記載します。
python -m eff_word_net.generate_reference --input-dir=./ --output-dir=../model --wakeword=test --model-type=first_iteration_siamese
学習すると指定したディレクトリにjson形式のモデルデータが出力されます。
モデルタイプを resnet_50_arcに指定した場合、テスト用のファイルを2秒以上に設定しないとエラーが出ます。first_iteration_siameseだと短くても学習できそうです。
学習データを使う
学習したデータを動作する実機に転送します。
そのデータを使うようにプログラムを修正します。
こちらのプログラム(https://github.com/Ant-Brain/EfficientWord-Net/blob/main/eff_word_net/engine.py)を一部修正して使います。
ホットワードのモデルを定義し、Detectorに登録することで使用します。
以下修正例:
test_hw = HotwordDetector(
hotword="test",
model = test_model,
reference_file = "./test_ref.json",
threshold=0.7, #min confidence required to consider a trigger
relaxation_time = 2 #default value ,in seconds
)
multi_hotword_detector = MultiHotwordDetector(
[mycroft_hw, alexa_hw, balloon_hw, computer_hw, mobile_hw, lights_on, lights_off, test_hw],
model=base_model,
continuous=True,
)
修正出来たら実行して確認します。
今回は「テスト」という言葉を追加して使用しました。
以下Raspberry Pi Zero2Wでの動作例です。
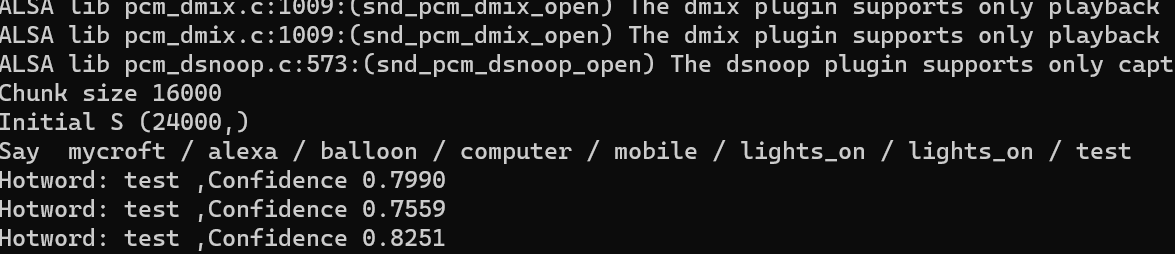
きちんと検出できていることがわかります。
参考文献
Discussion