Amazon Personalize で Custom Dataset を使ったリコメンデーションをしてみる
まえがき
自社サービスに「この商品を購入した方はこちらの商品も購入しています」といったリコメンデーションの仕組みを導入したい、そんなときに使えるサービスが Amazon Personalize です。
Amazon Personalzie を利用して、リコメンデーション API を立ち上げるところまでをステップバイステップで記事にしてみました。
1.データの準備
まずは、学習データの準備です。今回はMovieLens のデータセットを利用しています。
以下の URL から学習データをダウンロード・解凍しましょう。
解凍したファイルから ratings.csv を CSV 編集ができるソフトで開きます。
ratings.csv はユーザーIDと、そのユーザーが視聴した映画のID、映画に対してのレビュー評価、レビュー行ったタイムスタンプが含まれています。こちらのデータを利用して、「あなたと同じ傾向の視聴履歴を持つユーザーは、こんな映画もみています」と推薦する仕組みをつくっていきましょう。
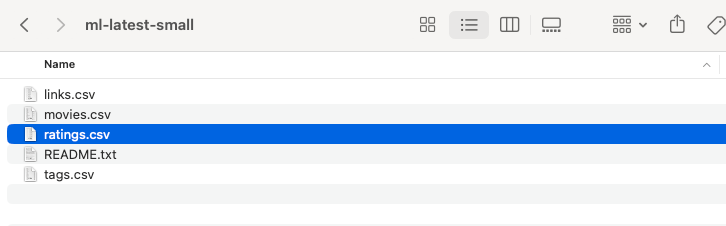
まず、rating 列を削除します
Personalzie にデータを読み込ませるため、ヘッダを USER_ID,ITEM_ID,TIMESTAMP に修正して保存します。

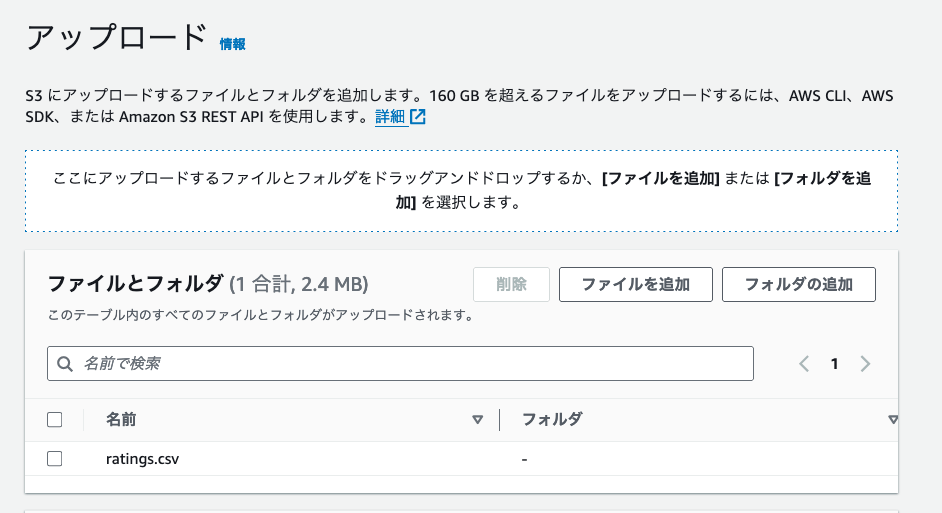
適当な S3 バケットを作成し、ratings.csv をアップロードします。
S3 のバケットポリシーを修正し、Personalize からのアクセスを許可します。
bucket-name 部分は作成した S3 バケット名に置換してください。
{
"Version": "2012-10-17",
"Id": "PersonalizeS3BucketAccessPolicy",
"Statement": [
{
"Sid": "PersonalizeS3BucketAccessPolicy",
"Effect": "Allow",
"Principal": {
"Service": "personalize.amazonaws.com"
},
"Action": [
"s3:GetObject",
"s3:PutObject",
"s3:ListBucket"
],
"Resource": [
"arn:aws:s3:::bucket-name",
"arn:aws:s3:::bucket-name/*"
]
}
]
}
2.データセットのインポート
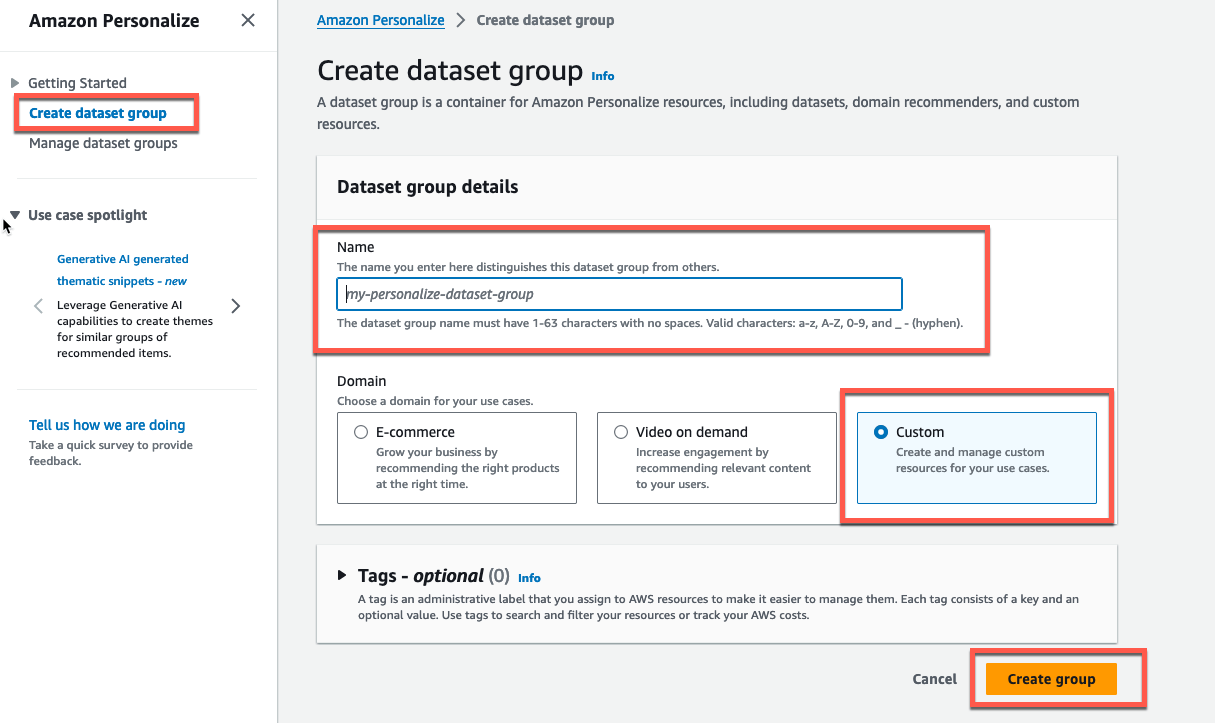
Personalize を開き、Create dataset group を選択します。
Name 欄に任意の名前を入力し、Custom を選択して Create Group を押します。
Create dataset -> item interactions dataset を押します。
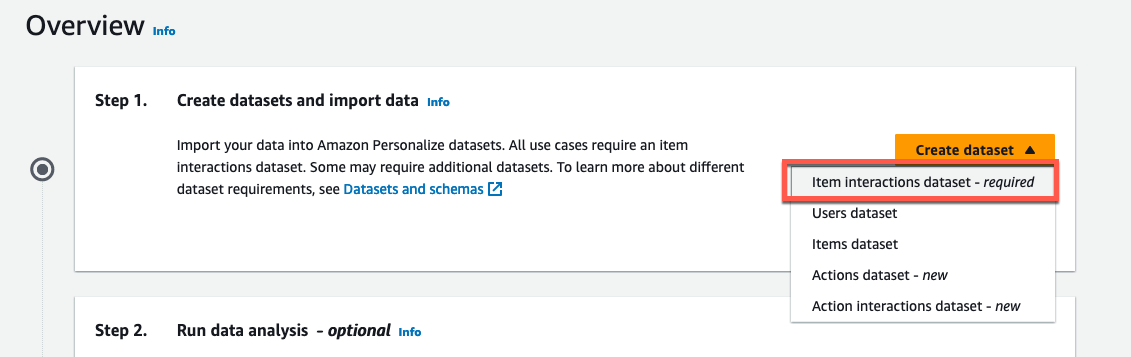
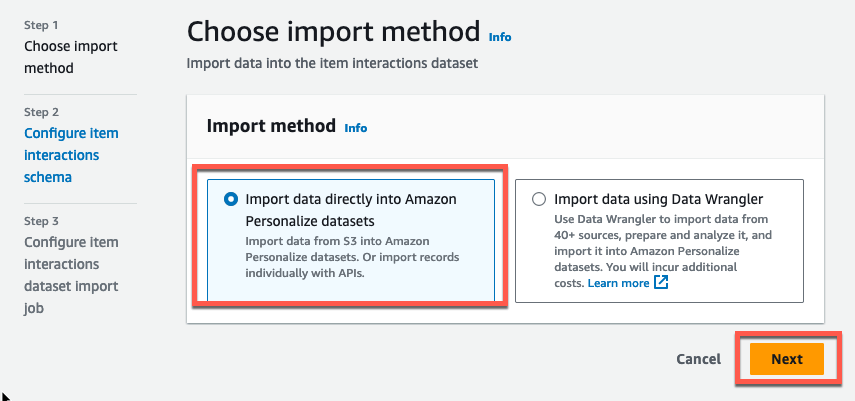
Data Wrangler は使わず、直接データセットを読み込ませます。
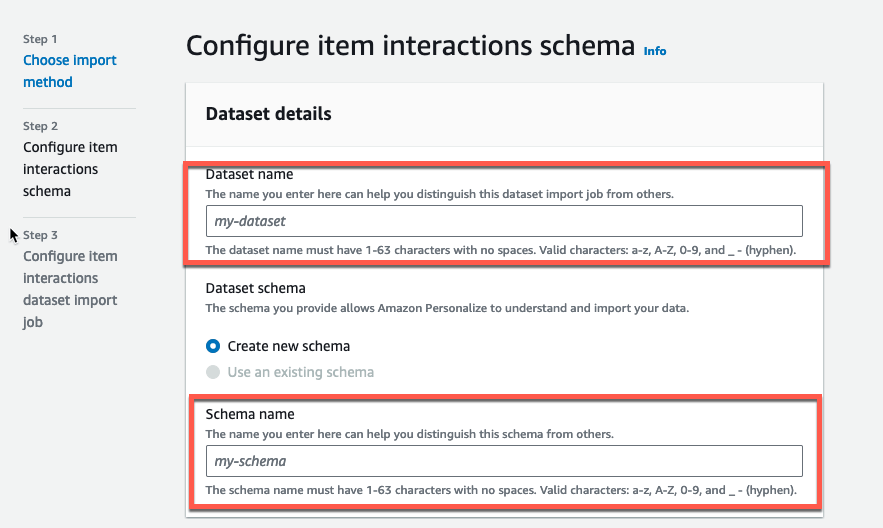
Dataset と Schema に任意の名前をつけます。
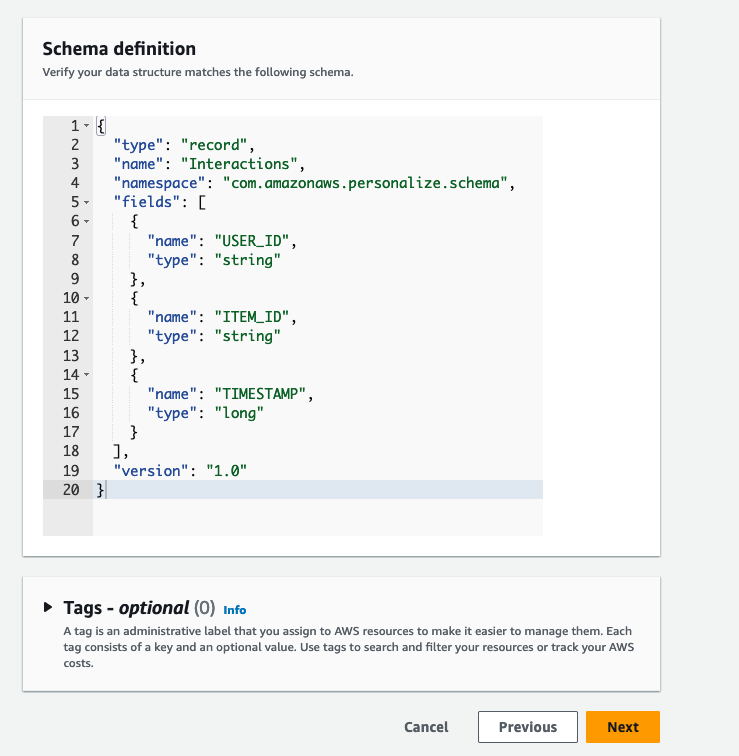
先ほどヘッダを修正した csv と同じスキーマになっていることを確認し next を押します。
Dataset import job 名に任意の名前をつけます。
Data Location 欄には、csv ファイルを配置した S3 の Location を入力します。
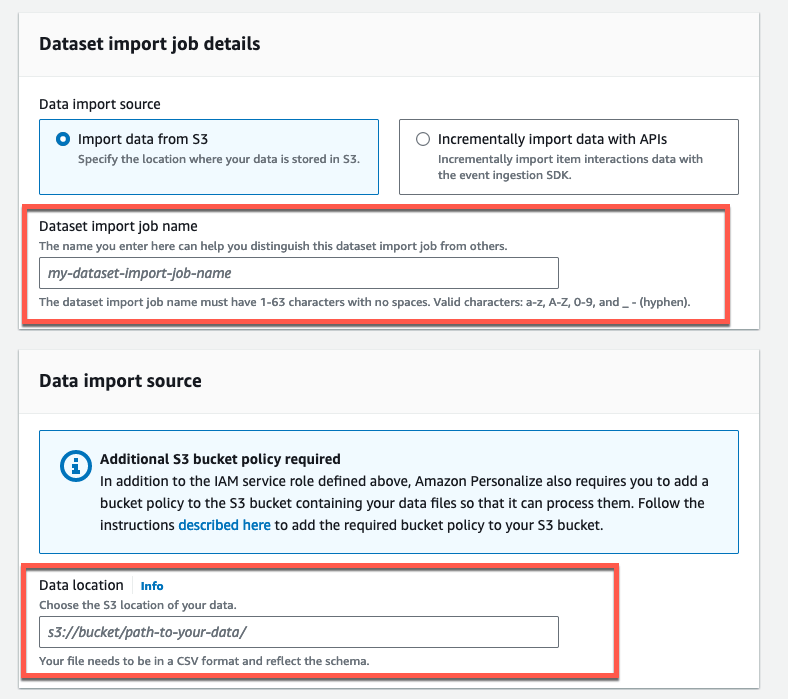
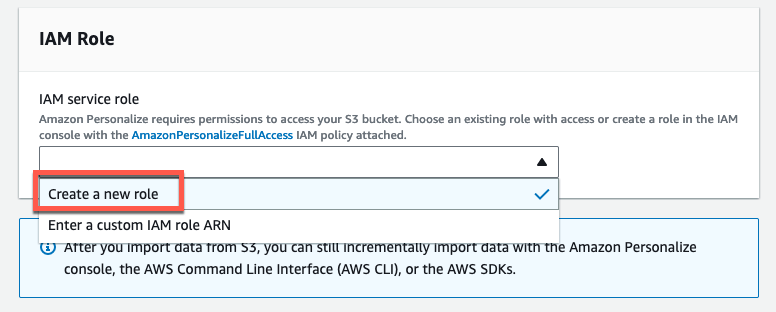
IAM Role では Create a new role を選択します。
確認画面が表示されるので Any S3 bucket を選択し Create role を押します。
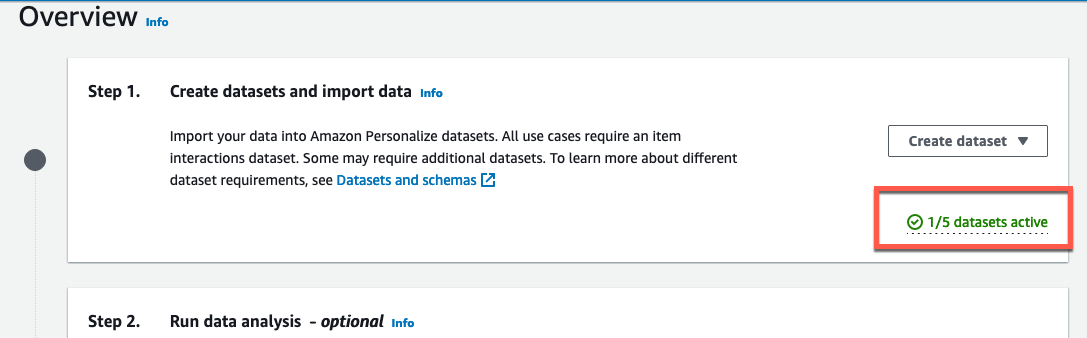
最後に Start import を押すと、データセットとして CSV が読み込まれます。

数分待ち、1/5 datasets active と表示されたら読み込みは完了です。
3.ソリューションを学習する
次は、ソリューションを作成します。ソリューションは
Create solutions を押します

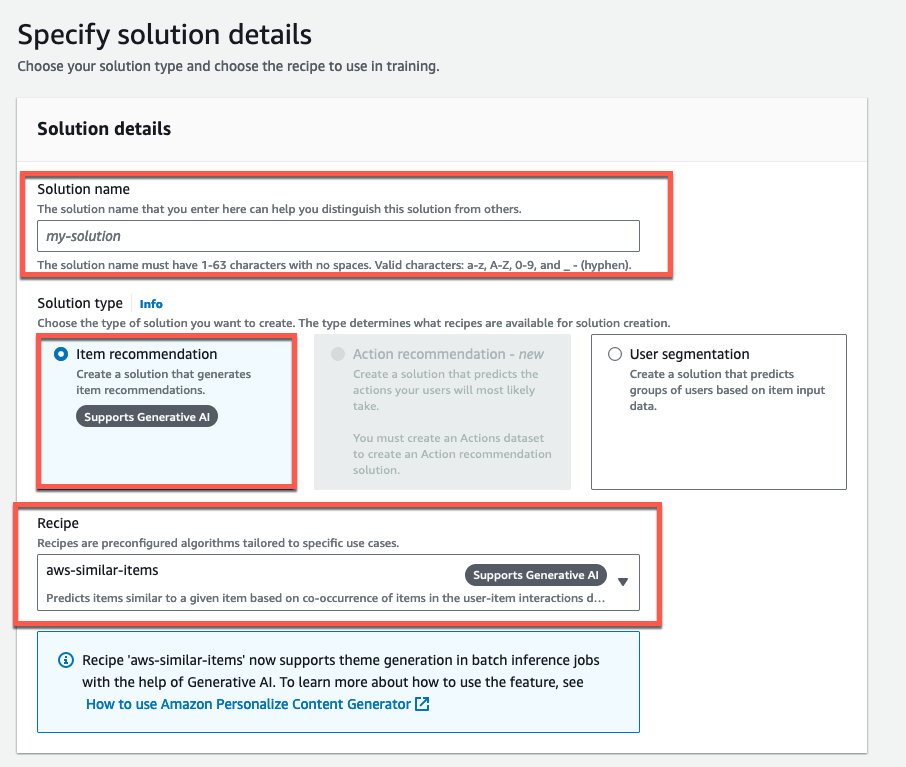
Solution name に任意の名前を入力します。
Solution type は item recommendation を選択します。
Recipe は aws-similar-items を選択します。
そして画面下部の Next を押します。
ハイパーパラメータの設定をします。
Perform HPO は OFF にします。ON にすると、item ID hidden dimension などのハイパーパラメータを自動的に最適化することが可能です。設定できたら Next を押します。
最後に、確認画面で Create solution を押せばソリューションの作成は完了です。
4.キャンペーンを作成してリコメンデーションを⾏う
次は、ソリューションを利用してキャンペーンを作成します。キャンペーンは、リアルタイムにリコメンデーションの推論を行うための API です。キャンペーンを作成する = リアルタイムの推論 API のエンドポイントを立てる、といったイメージです。
作成したソリューションの状態は画面左の Solutions and recipes から確認できます。
Solution version status が in Progress の間は学習が行われています。Status の値が Activce に変わったら次に進みましょう。
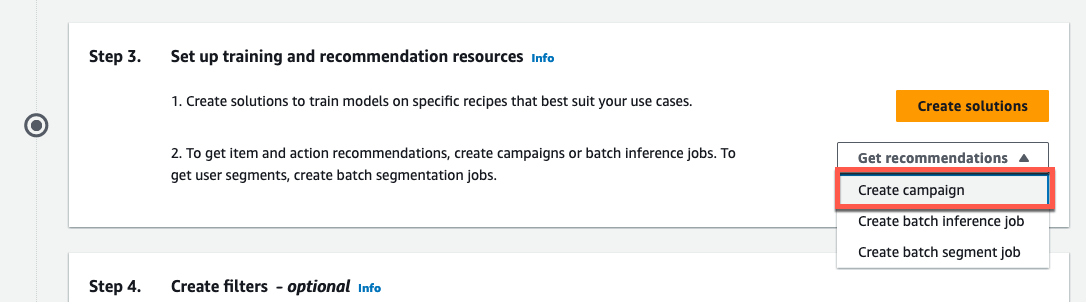
Get recommendations -> Create campaign を押します。
Campaign name に任意の名前を設定します。
Solution では 3. で作成した Solution を選択しましょう。
Minimum provisioned transactions per second は「秒間に何回レコメンドを取得するか」という設定値です。今回は 1 にしています。
設定できたら Create campaign を押しましょう。
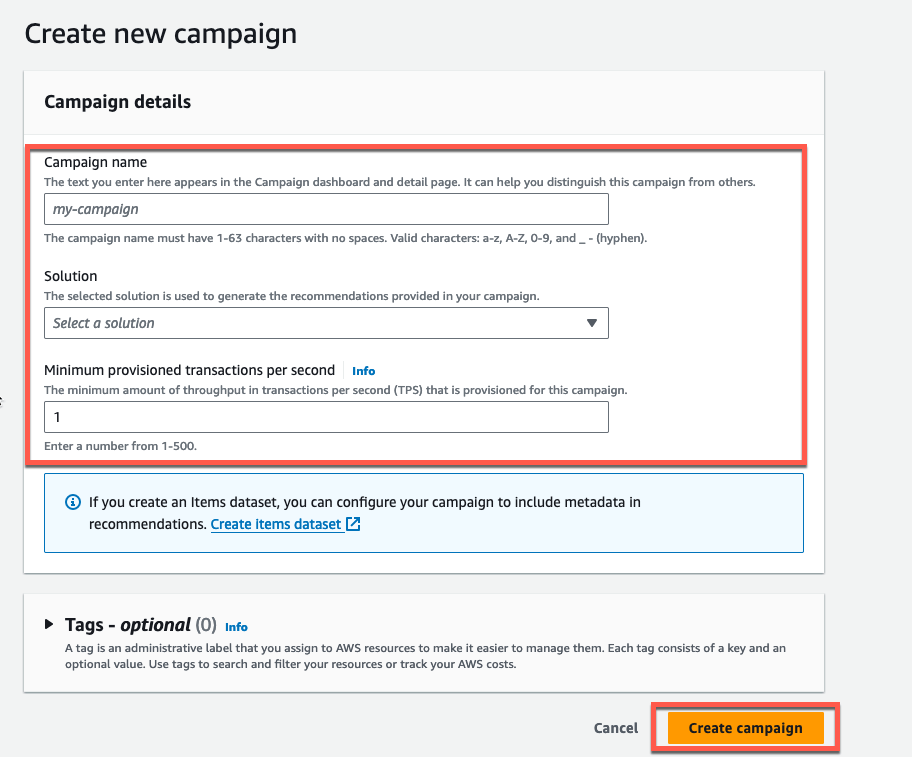
左ペインの Campaigns からキャンペーンの作成状況を確認できます。作成完了までしばらく待ちましょう。
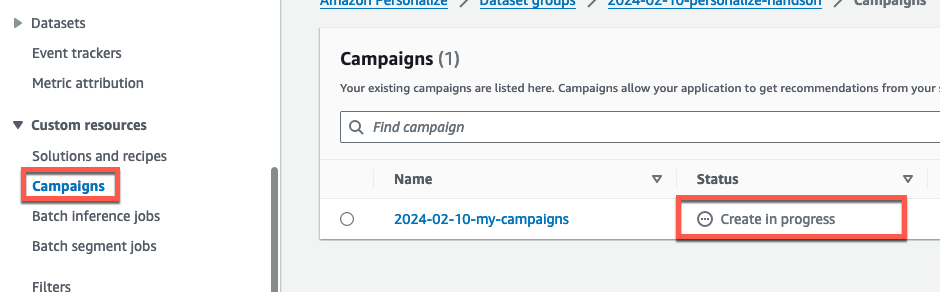
Status が Active なったら OK です。キャンペーンの名前をクリックして詳細画面に遷移します。
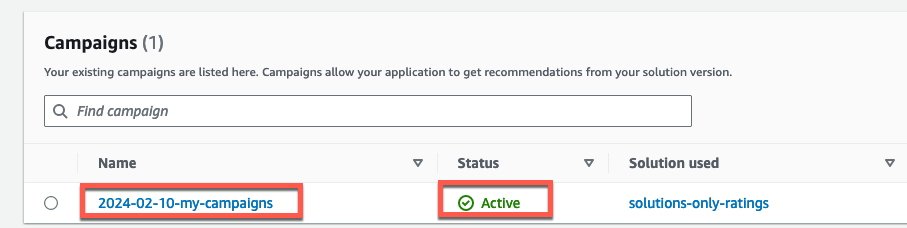
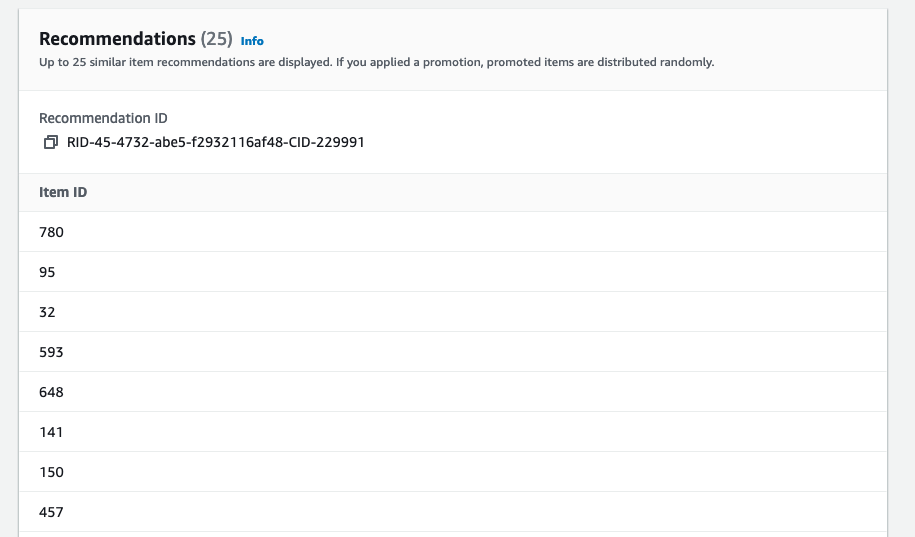
Test campaign results 欄で実際に API のテストができます。item ID 欄にリコメンドを予測したいユーザーの ID を入力して Get recommendations を押しましょう。
テストした結果はこのようになっています。今回はコンソール上からテストしていますが、SDK や CLI からこちらのキャンペーンを叩くことで、任意のユーザーIDに対してリコメンドを行うことが可能です。
5. 環境の削除
削除する際は、依存関係があるため [Campaigns→Solutions→Datasets→Dataset groups]の順番で削除する必要があります。
Discussion