SageMaker Jumpstart で BERT を使ったテキスト分類モデルをトレーニング & デプロイしてみる
はじめに
近年、自然言語処理の分野では OpenAI や Anthropic 社の大規模言語モデル(Large Language Model)が大きな注目を集めています。最近では、単なるチャット用途ではなく、システムの内部に API として組み込むような用途で LLM を利用することも増えてきました。
例えば、OCR で読み取ったテキストを仕分けするテキスト分類タスクを LLM に任せてしまう、といった用途がありますね。特に、最新の LLM は 20万トークンといった巨大なコンテキストウィンドウを利用できるため(Claude 3 を想定)、プロンプトに分類の条件などを大量に記述することで、ある複雑な分類タスクもこなすことが可能です。しかし、こうしたアプローチにはいくつかの問題点があります。
まず、大量のトークンをインプットとして利用するため、APIとしてシステムに組み込む場合のコストが懸念されます。また、LLM の特性から、テキスト分類器としての振る舞いが不安定になりがちです。
こうした課題を解決するにあたって、BERT(Bidirectional Encoder Representations from Transformers)のような従来の言語モデルが見直されています。BERTは2018年に登場した言語モデルですが、その汎用性の高さから今なお多くのタスクで活用されており、LLMの台頭によって影が薄くなったわけではありません。
とはいえ、BERT のファインチューニングには機械学習の知識や計算リソースの確保など、いくつかの障壁があるのも事実です。そこで本記事では、AWS の機械学習プラットフォームである Amazon SageMaker の Jumpstart 機能を使って、BERT のファインチューニング〜デプロイまでを簡単に試していきたいと思います。
学習の準備をする
SageMaker Jumpstart の画面を開きます。
Hugging Face や Meta など、いろいろなプロバイダのモデルを利用することが可能です。
今回は検索欄に Text Classification と入力し、テキスト分類モデルを探します。

表示された Hugging Face のモデルを選択します。

モデルの詳細画面が表示され、ファインチューニングする際のデータの形式などについて記載があります。このモデルでは data.csv という形式の CSV ファイルを用意する必要があります。
CSVファイルの中身は{分類ラベルの数値},{分類したいテキスト}の形式にします。
それでは「与えられたテキストがずんだもんのセリフか、そうでないか」を判別するモデルにファインチューニングしていきたいと思います。
今回は以下のずんだもんデータセットをベースに、Claude を使ってサンプルデータを作成しました。
ラベル 1 が「ずんだもんっぽい」、ラベル 0 が「ずんだもんではなさそう」と分類しています。
(実際には Claude で 1000 件ほどのサンプルを作成しました)
1,ボクの名前はずんだもんなのだ。
1,ずんだ餅に関係することはだいたい好きなのだ。
1,オマエは失礼な人なのだ。
1,ずんだもんなのだ。ずんだの妖精なのだ。
0,こんにちは。今日は晴れていい天気ですね。
0,今年の夏は暑かったですね。
0,将来の夢は、医者になることです。
0,私は毎日運動をしています。
0,このレストランはおいしいと評判です。
このファイルを適当な S3 バケットにアップロードしておきます。
学習を開始する
画面右上の Train ボタンを押します。

Model 欄はデフォルトのままで構いません。
DistilBERT がベースになっているようですね。
Data 欄では Enter training dataset を選択し、Browse ボタンから学習用データセットを配置した S3 バケットを指定します。

Hyperparameters はひとまずデフォルトのままにしておきます。
Deployment 欄で学習をおこなうインスタンスを選びます。
今回は ml.p3.2xlarge を選択します。
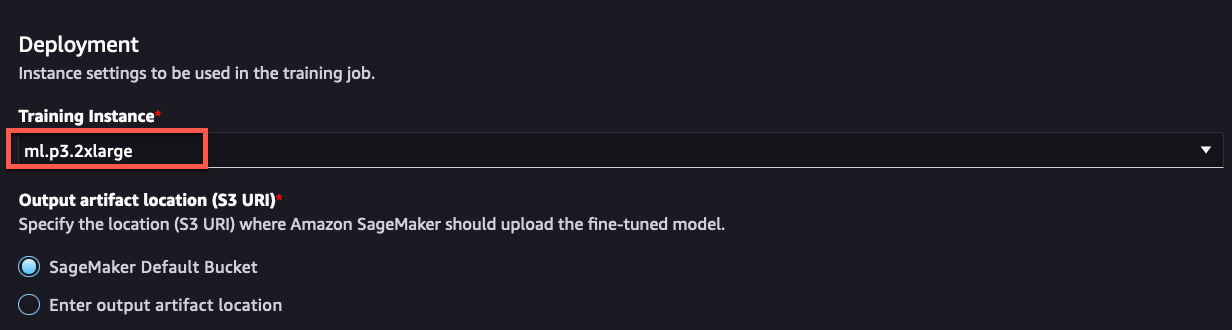
その他の設定はデフォルトのままで大丈夫です。
Additional Information 欄でトレーニングジョブに任意の名前をつけて Submit します。

すると SageMaker 上で Training ジョブが起動し、学習が始まります。
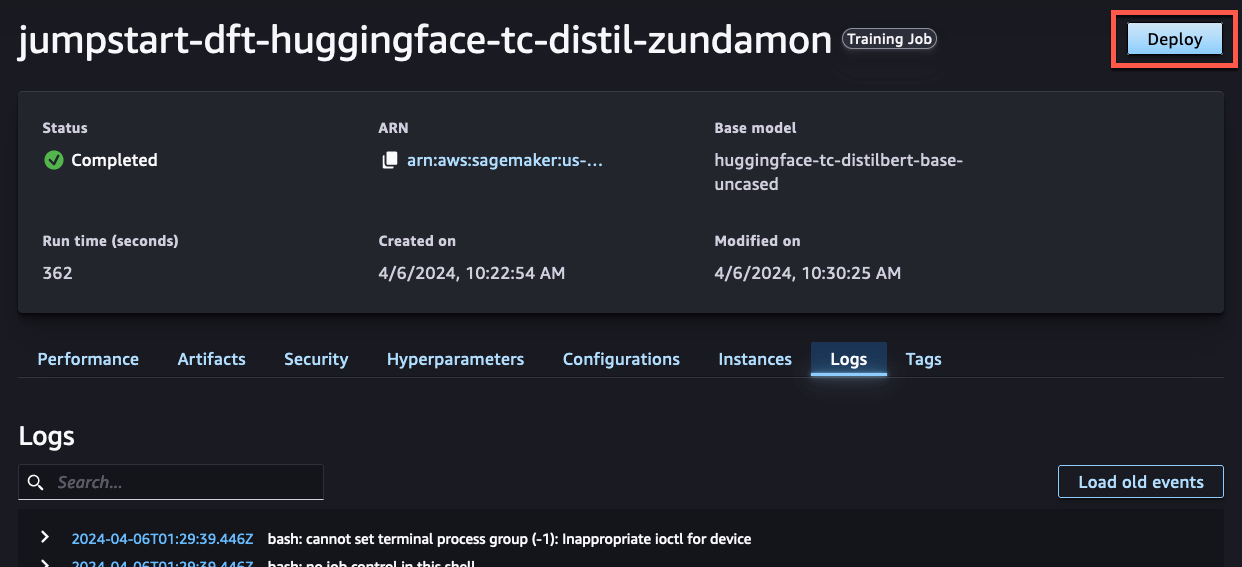
Status が Completed になったら学習は完了です。

学習したモデルをデプロイする
では、実際にモデルを使っていきましょう。
右上の Deploy を押します。
Instance type 欄でインスタンスを選びます。
今回は ml.m5.large を選んでいます。
画面右下の Deploy を押すと、SageMaker のエンドポイントが起動します。

Status が In serive になったらデプロイは完了です。
これで SageMaker エンドポイントを利用した推論ができます。
エンドポイント名(jumpstart-dft-hf-tc-distilbert-base-20240406-013420)は推論を実行する際に利用するので控えておきましょう。
画面下の Test Inference タブを開きます。

テスト用の Python SDK のサンプルコードも書いてくれていますね。

実際に推論してみる
以下のコードを実行して、テキストのずんだもん分類をしてみます。
import json
import boto3
# センテンスペアのリスト
sentence_pairs = [
["今年の夏は暑かったですね", ""],
["ボクはずんだもん!", ""],
["な、なにをするのだ!", ""]
]
newline, bold, unbold = '\n', '\033[1m', '\033[0m'
def query_endpoint(encoded_text):
endpoint_name = '{SageMakerのエンドポイント名}'
client = boto3.client('runtime.sagemaker')
response = client.invoke_endpoint(EndpointName=endpoint_name, ContentType='application/x-text', Body=encoded_text, Accept='application/json;verbose')
return response
def parse_response(query_response):
model_predictions = json.loads(query_response['Body'].read())
probabilities, labels, predicted_label = model_predictions['probabilities'], model_predictions['labels'], model_predictions['predicted_label']
return probabilities, labels, predicted_label
for pair in sentence_pairs:
text = pair[0] # 1番目のセンテンスを使用
query_response = query_endpoint(text.encode('utf-8'))
probabilities, labels, predicted_label = parse_response(query_response)
print(f"Inference:{newline}"
f"Input text: '{text}'{newline}"
f"Predicted Label: {bold}{predicted_label}{unbold}{newline}")
結果は以下の通りです。ずんだもんか、そうではないかうまく分類できています。
Inference:
Input text: '今年の夏は暑かったですね'
Predicted Label: LABEL_0
Inference:
Input text: 'ボクはずんだもん!'
Predicted Label: LABEL_1
Inference:
Input text: 'な、なにをするのだ!'
Predicted Label: LABEL_1
後片付けをする
検証が終わったらエンドポイントを削除して課金を止めましょう。
SageMaker Studio の左ペインのメニューから Deployments -> Endpoints を選択します。

エンドポイントを選択し Delete を押すと、エンドポイントを削除することが可能です。

おわりに
SageMaker Jumpstart を使うことで、ほぼノーコードで BERT のファインチューニングを行い、エンドポイントとしてデプロイすることができました。Jumpstart には最新の LLM をはじめ、豊富なモデルが存在するのでぜひ試してみてください。
Discussion