OpenTelemetry Collectorに対するモニタリングとオブザーバビリティ
こんにちは。普段は Splunk でオブザーバビリティの導入支援などを行っています、kntr_nkgm です。
今年は暖冬のようですが、それにしても今日の東京は突然寒くなりまして、とうとう今冬初コートをだしました。
乾燥気味ですし、みなさまお風邪にはお気を付けください。
OpenTelemetry Collector
OpenTelemetry による計装(Instrumentation)では、OpenTelemetry SDK を利用して直接オブザーバビリティのバックエンドにデータを送ることも可能です。それほど対象環境やシステムが大きくなかったり、運用・開発に関わるメンバーが多くなかったりする場合には十分かもしれません。
他方、OpenTelemetry Collector を介することで、テレメトリーデータの処理(リトライ、バッチ処理、暗号化、フィルタリング…)や送信先・方式の管理を集約し、一定の処理を施してバックエンドにデータを送信できるようになるため、一般的には OpenTelemetry Collector の利用は推奨されています。
OpenTelemetry Collector の仕組みとしてはよくこういった図が使われますが、要は、データの受信(Receiver)、加工(Processor)、送信(Exporter)を、パイプラインとして組み立ててテレメトリーデータを柔軟に扱うというものです。
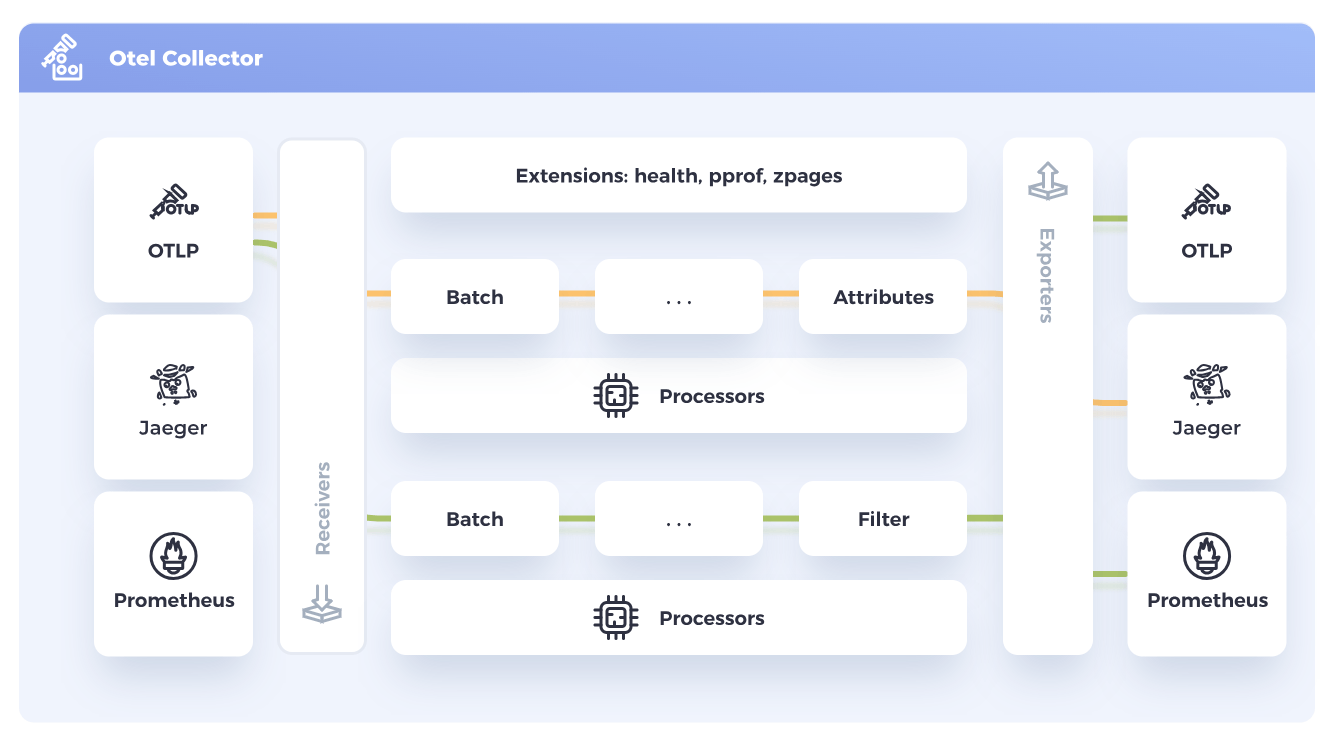
OpenTelemetry Collectorの監視・オブザーバビリティ
さて、システムの監視を考える際に必ず検討することになるのが
「監視システム自体の監視をどう実装するか」
というテーマです。
監視サーバとエージェント(被監視サーバに導入するソフトウェア)から構成される仕組みの場合、例えば、よくあるのは以下のような設計でしょうか。
- 監視サーバ側を冗長に構成し、サービス停止やメンテナンス時に切り替える
(可用性要件次第で「監視の一時的な断絶は許容する」ような割り切りもあるかもしれません) - エージェント側では、サーバ~エージェント間で定期的な通信確認を行い一定時間・回数失敗した場合にアラート発報する
OpenTelemetry Collector もまた、"(鍵カッコつきの)監視"[1] あるいはオブザーバビリティのためのエージェントであることは間違いありません。
では、OpenTelemetry Collector に対する監視・オブザーバビリティをどう考えるのがよいのでしょう。
ちょっと探してみると、実は、OpenTelemetry Collector の Github レポジトリ上にちょうどいい感じの doc が置いてあります。
今後もメンテナンスされていくでしょうから、正式にはこちらをご参照ください。
monitoring.md
observability.md
というわけで、この中でどんなことが書かれているかを簡単にまとめておこうと思います。
(まあ、Google翻訳かけてもらえれば一発なんですが)
※以下、いずれも筆者の拙い英語翻訳と、筆者の理解に基づいて記載していきます。
OpenTelemetry Collectorに対するモニタリング
monitoring.mdで紹介されているのは、主に以下のような内容です。
データ損失やサービス影響の可能性が濃厚なケースを "Critical Monitoring" として定義し、
それほどではないものの注意を要するのが "Secondary Monitoring"、
定期的な傾向などに役立てられそうな指標として "Data Flow" が位置づけられているものと理解しています。
Critical Monitoring
ここは、データ損失やサービスへの影響発生の可能性を示唆する項目のようです。
- データロスの発生を示すメトリクスを確認する
otelcol_processor_dropped_spansotelcol_processor_dropped_metric_points
- CPUリソースの枯渇を示すメトリクスを確認する
- ただし、利用環境やシステム固有の設定によって利用可能なコア数・安全とみなせるCPU使用状況は異なる
Secondary Monitoring
Critical Monitoring ほど明確にデータ損失を意味するものではないものの、継続的に以下の事象が発生する場合はチェックが必要である項目といったところでしょうか。
- Queue Length を確認する
- Exporter はデータのキューイングと再試行を行うため
- リトライキューの容量を示す
otelcol_exporter_queue_sizeと、現在のキューサイズを示すotelcol_exporter_queue_sizeに基づいてキューサイズが十分かを確認する - キューへの追加が失敗したスパン、メトリクス、ログの数を示す以下のメトリクスに基づき、送信レートを下げるか、Collector を水平方向にスケールさせる
otelcol_exporter_enqueue_failed_spansotelcol_exporter_enqueue_failed_metric_pointsotelcol_exporter_enqueue_failed_log_records
-
"Dropping data because sending_queue is full"のログ出力を確認する
- Receiver での受信エラーを確認する
- クライアント側にエラーを返していることを示す
otelcol_receiver_refused_spansとotelcol_receiver_refused_metric_pointsが継続する場合、利用環境やクライアント側の状況によってはデータロスが発生している可能性がある - Collector がデータを想定通りに送信できていないことを示す
otelcol_exporter_send_failed_spansとotelcol_exporter_send_failed_metric_pointsが継続する場合、失敗率が高い場合は、ネットワークやバックエンドに問題が発生している可能性がある(再試行が行われる可能性があるため、これ自体がデータ損失を意味するものではない)
- クライアント側にエラーを返していることを示す
Data Flow
ここでは、テレメトリーデータの受信・送信量の確認方法が触れられています
- テレメトリーデータの受信量
otelcol_receiver_accepted_spansotelcol_receiver_accepted_metric_points
- テレメトリーデータの送信量
otelcol_exporter_sent_spansotelcol_exporter_sent_metric_points
OpenTelemetry Collectorに対するオブザーバビリティ
observability.mdでは、まず目的として以下が定義されています。
The goal of this document is to have a comprehensive description of observability of the Collector and changes needed to achieve observability part of our vision.
(このドキュメントの目的は、Collectorのオブザーバビリティと、私たちのビジョンの一部であるオブザーバビリティの達成に必要な変更に関して包括的に説明することである)
可観測であるために必要なものとして挙げられているのは、以下のようなものです。
基本的に、Receiver - Processor - Exporter の基本的なパイプラインにおける Input/Output と、Collector内での処理におけるリソース、スロットリングにフォーカスを当てているように思われます。
現在の値
- リソース消費量
- CPU、メモリ(将来永続キューを実装した場合は I/O)
- その他のGoアプリケーションで利用可能なメトリクス
- 受信データレート(Receiver別・データタイプ別)
- 送信データレート(Exporter別・データタイプ別)
- スロットリングによるデータドロップ率(データタイプ別)
- 不正なデータ受信によるデータドロップ率(データタイプ別)
- 現在のスロットリング状態
- スロットリングされていない
- Downstreamによるスロットリング
- 内部的なリソース枯渇によるスロットリング
- 受信コネクション数(Receiver別)
- 受信コネクション率(1秒あたりの新規コネクション数、Receiver別)
- メモリ内のキューサイズ(バイト単位、あるいは、単位あたり)
- 永続キューサイズ(サポートされた場合)
- End to Endのレイテンシー(Receiverでの受信からExporterでの送信まで)
- パイプラインの要素別のレイテンシー
累積値
- 受信データの合計値(Receiver別・データタイプ別)
- 送信データの合計値(Exporter別・データタイプ別)
- スロットリングによるデータドロップの合計値(データタイプ別)
- 不正なデータ受信によるデータドロップの合計値(データタイプ別)
- 受信コネクション数の合計値(Receiver別)
- 起動からの継続稼働時間
イベントに関するトレースまたはログ
- Collectorの開始・停止
- Collectorの構成変更
- スロットリングによるデータドロップの開始(スロットリングの理由を含む)
- スロットリングによるデータドロップの終了
- 不正なデータ受信によるデータドロップの開始(サンプルまたは最初の不正データを含む)
- 不正なデータ受信によるデータドロップの終了
- クラッシュの検知(正常停止と区別し、可能な場合はクラッシュデータを含む)
ホストメトリクス
- Collectorが稼働するホストのメトリクス収集
後続では、これらのテレメトリーをどのように公開するかなどについて触れられていますが、ここでは割愛します。
やっていこう!
特に監視としては項目までメトリクスの種類まで明確に提示されているので、これらをダッシュボードに組み込んでみたり、アラート発報の基準にしたりするのはよいかもしれません。
Collectorのオブザーバビリティとしては、データドロップ、データの処理レートなどはまだしも、End to Endでのレイテンシーなどについては、どのように可視化していくか、ちょっと探索してみる必要があるかもしれませんね。
ちなみに、ちょっと宣伝になってしまいますが、
Splunk Observability では、OpenTelemetry Collector用のダッシュボードが組み込みでついています。

中身を開くと、上で記載した、"Critical Monitoring", "Secondary Monitoring" などのカテゴリに即してダッシュボードが用意されていたりします。
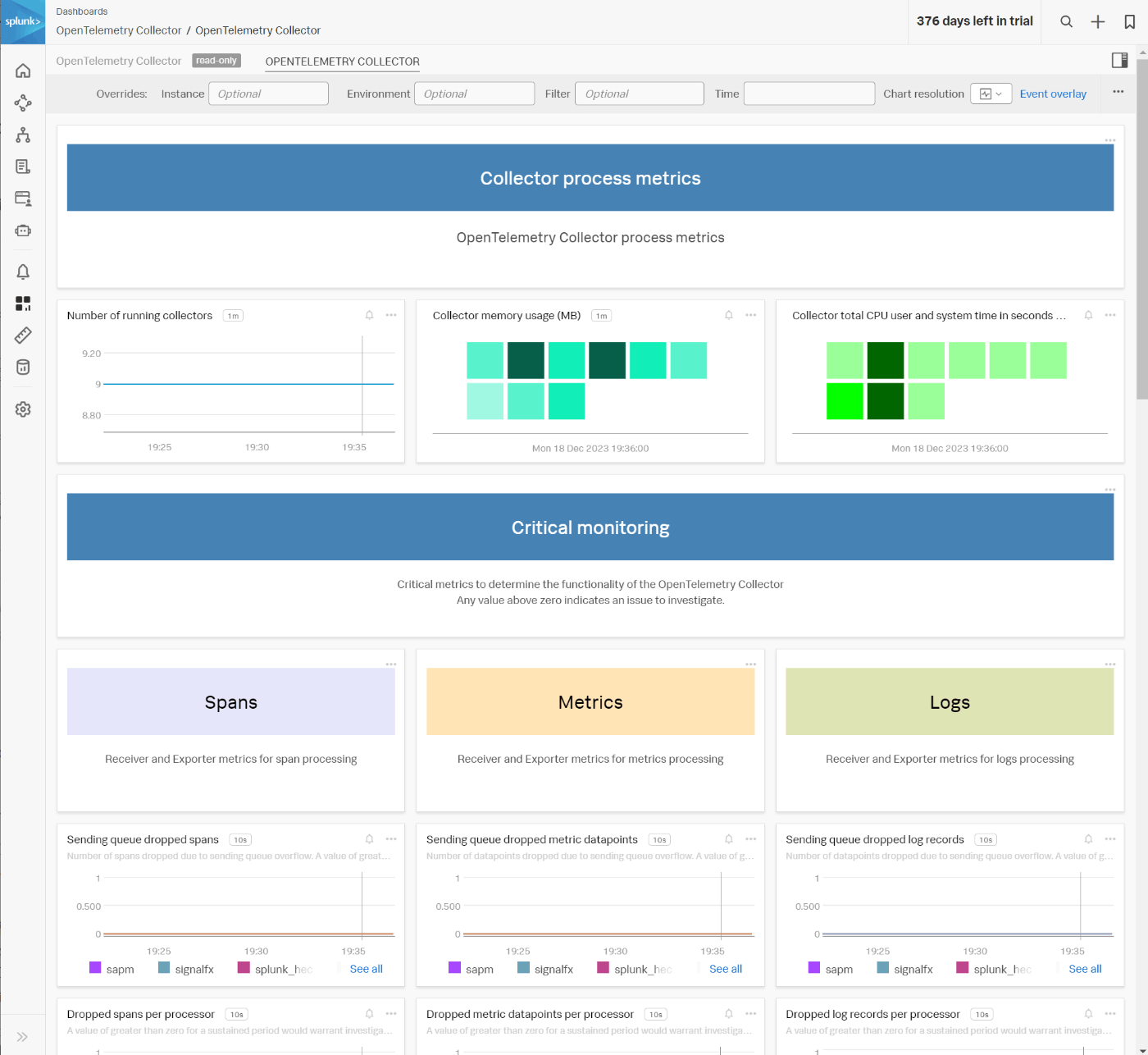
特に、OpenTelemetry Collectorを利用した計装を実施する中で、データ取得がうまくいかないような場合には、こういったダッシュボードを使いながら、トレースやメトリクスが Splunk Observability まで到達しているか、それとも Collector まで到達していないか、などを分析して行ったりもします。
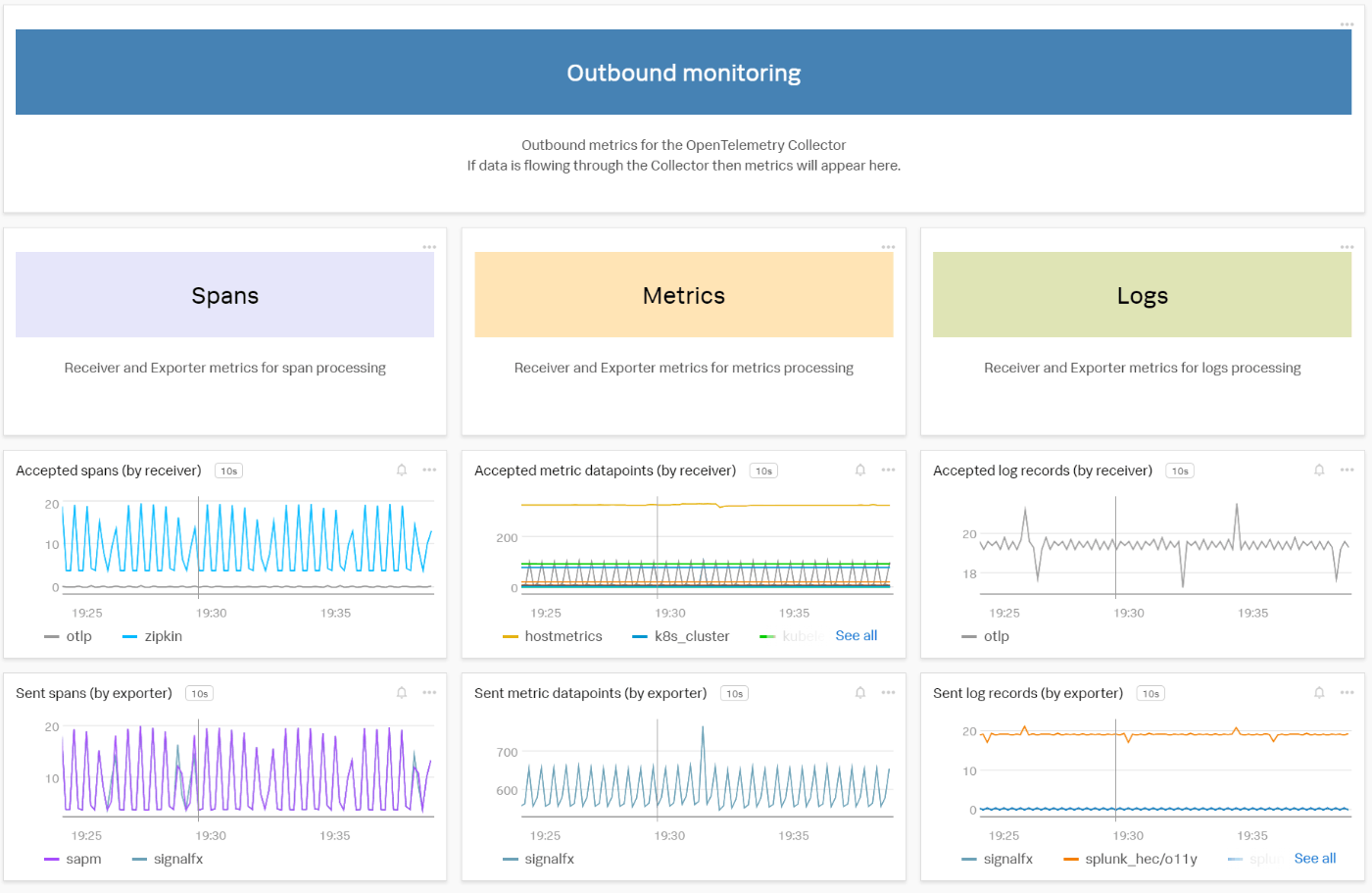
Splunk Observability は OpenTelemetry 完全準拠ですので、まあ、そりゃあこういうのはあるよね、というところです。
おわりに
Gartner "ソフトウェア・エンジニアリングのハイプ・サイクル: 2023年" では、オブザーバビリティは、あと一歩で "幻滅期" に入る "「過度な期待」のピーク期" と位置づけられました。
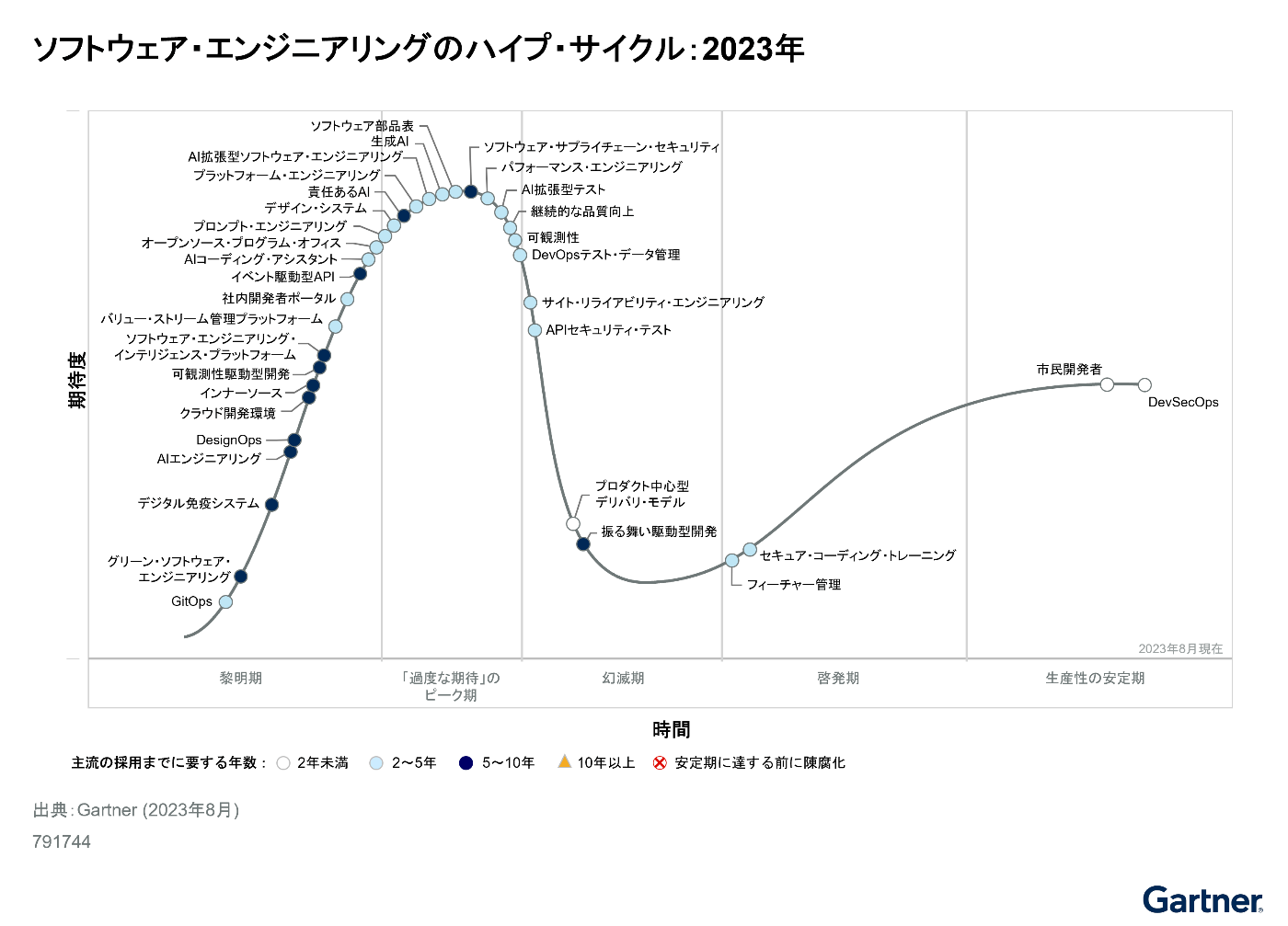
「オブザーバビリティ」は(よくも悪くも、バズワード的にも)だいぶ広がりを持った言葉ですし、広く普及し始めている言葉だと感じています。
「聞いたことはある」「よくわからないけど、なんか良さそう」というような声も聞きますし、一方で「いや、触ってみたけどやっぱりよくわからない」というような声も聞こえてきます。そういった体感からしても、この「幻滅期」と「過度な期待のピーク期」のちょうど境目にあるというのは、非常にしっくりくるなーと思っています。
「オブザーバビリティってなに?」っていうのは非常に難しい質問だと思いますし、多くの人がツールとして OpenTelemetry Collector や APM 製品などに取り組んでみて「うーん、なんか結局よく使いこなせなかった」という感想を持つのもうなずける話だと思います。
その意味で、本記事で取り上げた内容は、OpenTelemetry Collectorという、それほど複雑ではない1つのソフトウェアに対して「こういうオブザーバビリティが必要である」と述べてくれている例ではあると思います。
もしかすると、今後オブザーバビリティに取り組んでみるシステムの担当者の方は、オブザーバビリティを具体的に定義する一つの例として参照するのもよいのかもしれません。
とは言いつつ、頭でっかちになりすぎない程度に、いろいろと触りながら、できることや見えることを少しずつ増やしていくのがよいんだろうなーなどとも思っています。
ややOpenTelemetryの文脈から外れてしまった部分もありますが、ご容赦ください。
それではみなさま、よい年末をー!
-
「監視」と「オブザーバビリティ」というものを、その性質を踏まえて、分けて説明することがあります。OpenTelemetry自体はオブザーバビリティに関するフレームワークでありプロジェクトなので、一応こういった鍵カッコつきの表現にしています ↩︎
Discussion