Swift Syntaxの内部設計を見てみる
この記事はSwiftの構文木・コード生成ライブラリである Swift Syntax について、内部設計などを見ていきます。利用者目線での解説(マクロの作り方など)には触れません。つまりコンパイラ開発的な目線での記事です。
ほぼ個人メモですが誰かの参考になればと思い記事に残します。
(自分はContributorとかではなく、単に勉強でソースコードを読んだ一般人なので、間違ってる点があるかもしれません。見つけたらぜひコメントください)
全体構成
SwiftSyntaxは構文木。ソースコードを解析してSwiftSyntaxを作るのがSwiftParser。
SwiftParserはLexer(字句解析器)とParser(構文解析器)の2システムに大別される。
SwiftParser.mdの Design Principalsにパフォーマンスについての一文があるように、全体的にパフォーマンスに気を使った設計になっている。
Efficient: The parser should provide similar parsing performance to the existing C++ parser implementation that it seeks to replace.
効率: このパーサーは、置き換えようとしている既存のC++パーサー実装と同等のパーシング性能を提供する必要がある。
Lexer(字句解析器)
字句解析器(ソースコードの文字列を意味のある単語に分解する責務のシステム)。分割された単語は Lexeme という型になっています。
コンパイラ開発では字句解析器をTokenizer、分割された単語をTokenと呼ぶ場合もありますが、SwiftSyntaxでは両方の命名が使われているようです。Lexemeという呼び方をしている場所もあれば、変数でtoken: Lexer.Lexemeのように宣言しTokenという呼び方をしている場所もあります。
(この記事では一般的に単語を指す際は「トークン」と呼ぶことにします。)
SwiftParserのLexerはcaseなしenum、つまりただのnamespaceです。
LexemeSequence
Lexerがただのnamespaceなら誰が字句解析をしているのか?という疑問の答えがLexemeSequenceです。
LexemeSequenceは分解されたトークン列それ自体であり、かつ字句解析を行う責務を持っています。
IteratorProtocolとSequenceに準拠しているので、next()メソッドを利用することで次のLexemeが取得できます。また、for-inでLexeme一覧を探索することが可能です。
let lexemeSequence = ...
let nextToken = lexemeSequence.next()
for lexeme in lexemeSequence {
}
LexemeSequenceは現在のソースの位置(cursor)を保持し、next()の操作によってcursorを更新します。
cursorはLexeme.Cursor型で表現されており、最終的に入力を見て字句解析するロジックを持っているのはこのCursorです。LexemeSequenceはCursorを操作するだけです。
-
sourceBufferStart: プログラムの開始地点を示すCursor -
cursor: 現在の次のCurosr -
nextToken: 次のLexeme-
peek()(cursorを更新せず次のLexemeを見る「先読み」)を行うことが多いので、次のLexemeはstored propertyとして保持しています。なので上記cursorは常に「現在」ではなく「現在の次」になっている。
-
Cursor
position: Cursorが指す入力の位置(ポインタ)を持ちます。8ビット単位。
nextToken()
文字列を単語列に分解するロジックを持つ関数です。字句解析のコアロジック。
基本的に8ビットづつCursorのpositionを動かしていき、トークンの区切りに到達したら解析結果であるLexer.Resultを生成する。Lexer.Resultを元にLexemeを生成やCursorの状態(後述)を更新して終了。
なお、記号や文法上のkeywordはascii範囲(8ビット)で表現できるので、基本的に8bitごとの操作で問題ない。identifier(変数名・関数名)などasciiから外れる可能性がある箇所のみUTF-8で解釈する。
trivia
コメントやスペースなど、プログラムの挙動上意味のないトークンはtriviaと呼ばれ、近い単語に引っ付ける形で管理されます。nextToken()で単語を解析する前後にleadingTriviaとtrailingTriviaを解析するロジックが存在する。
解析例
/*a*/ a /*b*/ = /*c*/ 10 /*d*/
// e
identifier (leadingTrivia: "/*a*/ ", trailingTrivia: " /*b*/ ")
equal (leadingTrivia: "", trailingTrivia: " /*c*/ ")
integerLiteral (leadingTrivia: "", trailingTrivia: " /*d*/")
endOfFile (leadingTrivia: "\n\n// e", trailingTrivia: "")
トークン毎にtrailingとleading両方の解析を行う。そのため二つのトークンの中間にあるTriviaは先に来たトークンが解析してtrailingTriviaになりやすい。
ただ、trailingTriviaは改行を解析しないというロジックが存在するため、改行からは次のトークンのleadingTriviaになる。
また、一番最後にendOfFileトークンという仮想のトークンが存在することになっており、入力上で最後のトークンtrailingTriviaにならなかったTriviaはendOfFileトークンのleadingTriviaとなる。
previousTokenKind: 一つ前のtokenのkind
基本的にCursorは前方の文字を見て字句解析を行うが、後方のTokenによって解析結果が変わるケースが存在する。
例: Cursorが指す次の文字が0.1の時、その前のトークンが.だった場合はタプルへのアクセスになる(x.0.1)が、それ以外ならFloatingLiteralとなる。
0.1
↑カーソル位置
// A: カーソルの前がピリオドの時
// identifier, period, integerLiteral, period, integerLiteral
x.0.1
↑
// B: A以外
// floatingLiteral
0.1
↑
また、このようにSwiftParserの字句解析は、特にLiteral周りではある程度構文に依存した解析を行う。(おそらく単一的に記号やidentifirで解析した後、構文解析でLiteralとして再解釈するよりもコスパが良いのだと思われる)
// 同じ `/` でも違うtokenとして解釈される例
// identifier, binaryOperator, identifier
a / b
// regexSlash, regexLiteralPattern, regexSlash
/b/
State, StateStack
また、上記のように前方後方数トークン・文字だけでは情報が足りない場合がある。主にStringLiteralやRegexLiteralで起こるケース。そのための状態がState。
// multiline string内の改行は文字列中の「\n」として認識される
// triviaではなく文字列中の「\n」として解析するためには「今multiline string内にいる」という状態が必要
let a = """
ほげほげ
ふがふが
"""
StateによってCursorは字句解析ロジックを変えている。字句解析モードのような物。
スタックになっているのはStringInterporationの中にさらにStringLiteralやRegexLiteralを書くことができるため。
// n重文字列展開
"aaaa \(hoge + "bbbb \(fuga + "cccc")")"
// 文字列展開の中にRegexLiteral
"\(try! /\d{1}/.wholeMatch(in: "1")!.description)"
Lexeme
分解された単語を表す型。トークン。
トークンの文字列はStringなどで保持しているわけではなく単語の先頭ポインタと単語のバイト数を保持しているだけ。これは主にパフォーマンスのためだと考えられる。
- 単語(
leadingTriviaを含む)先頭ポインタstart - 単語のバイト長
textByteLength - 単語のleading/trailingTriviaのバイト長:
leadingTriviaByteLength,trailingTriviaByteLength
また、単語の種類を識別するためのRawTokenKindも保持されています。
RawTokenKindは記号については各記号毎(!, ?, ->, =)にcaseがありますが、keyword (if, else, do)はkeyword毎にcaseがなく、粒度の違いが気になりました。
keywordは将来的に追加される可能性がありsource breakingになるから...?
Parser(構文解析器)
内部に先述のLexemeSequenceを持ち、Lexemeを読み出しながら構文木 (Syntax型) に変換する責務の型です。
再帰下降構文解析と呼ばれる、再起的に右方向にトークンを見て構文を解釈する手法。
構文解析
基本的に以下の操作をベースに構文解析を行う。
-
eat(TokenSpec) -> RawTokenSyntax- 今のtokenを消費して
RawTokenSyntaxを生成する
- 今のtokenを消費して
-
at(TokenSpec) -> Bool- 今のtokenがTokenSpecに一致するか確かめる
-
consume(if: TokenSpec) -> RawTokenSyntax?- atがtrueならeatする、falseならnilを返す
TokenSpecは先述のLexemeの種類を表すRawTokenKindにKeywordの分類(if func letなど) を加えた物。多分ほぼ同じ役割。
例: functionDecl (関数定義)
Swiftの関数定義は様々なバリエーションがある。
func hoge() {}
// 引数・帰り値あり
func hoge(a: Int) -> Int {}
// ジェネリックパラメーターあり
func hoge<T>(a: T) -> Int {}
// 演算子の場合は記号でもOK
func ~=(lhs: Int, rhs: Int) {}
// whereあり
func hoge<T>(a: T) -> Int where T: Codable {}
一般的にこのような文法は(E)BNF記法と呼ばれる記法で表すことができ、Swiftの関数定義をBNFで表すと以下のようになる。TSPL Summary of Grammer より引用
// <...>は非終端記号、?は省略可能を意味する。
<functionDecl> = func (identifier|記号) <genericParameters>?<functionSignature> <genericWhereClause>? <body>?
基本的にこのBNFの構造をプログラムに起こしているだけなので、構造さえ掴めれば構文解析のロジックも読みやすい。
実際のコードを一部省略して解説
mutating func parseFuncDeclaration(
_ attrs: DeclAttributes,
_ handle: RecoveryConsumptionHandle
) -> RawFunctionDeclSyntax {
// "func"をeat(tokenを一つ進める)
let (unexpectedBeforeFuncKeyword, funcKeyword) = self.eat(handle)
// identifierまたは記号の解析
// `at`でidentifierか記号のどちらなのかを判断
let identifier: RawTokenSyntax
if self.at(anyIn: Operator.self) != nil || self.at(.exclamationMark, .prefixAmpersand) {
// 記号の場合
var name = self.currentToken.tokenText
...
identifier = self.consumePrefix(name, as: .binaryOperator)
} else {
// identifierの場合
(unexpectedBeforeIdentifier, identifier) = self.expectIdentifier(keywordRecovery: true)
}
// ジェネリックパラメータ
// 省略可能なので冒頭の"<"をatで確認し、"<"があった場合は`parseGenericParameters`でパース
// 非終端記号が関数呼び出しに対応している点でもBNFとプログラムの構造が一致していてわかりやすい。
let genericParams: RawGenericParameterClauseSyntax?
if self.at(prefix: "<") {
genericParams = self.parseGenericParameters()
} else {
genericParams = nil
}
// 引数など"(...)"の部分はparseFunctionSignatureでパース
let signature = self.parseFunctionSignature()
// where句
let generics: RawGenericWhereClauseSyntax?
if self.at(.keyword(.where)) {
generics = self.parseGenericWhereClause()
} else {
generics = nil
}
// 関数body
let body = self.parseOptionalCodeBlock()
// 上記情報から`RawFunctionDeclSyntax`を生成して解析完了
return RawFunctionDeclSyntax(
attributes: attrs.attributes,
modifiers: attrs.modifiers,
unexpectedBeforeFuncKeyword,
funcKeyword: funcKeyword,
unexpectedBeforeIdentifier,
name: identifier,
unexpectedAfterIdentifier,
genericParameterClause: genericParams,
signature: signature,
genericWhereClause: generics,
body: body,
arena: self.arena
)
}
異常系
基本操作にはもう一つexpect(TokenSpec)が存在する。
今までに読んだトークンによって構文が確定し、後続のトークンが確定している時、その後続トークンをeatする際に使う。
上記のparseFuncDeclarationでも関数名のパース部分がexpectになっている。
func
↑funcが来たらfuncDeclで確定なので、次は絶対identifierか記号が来るはず
expectはeatを試して失敗した場合「recovery」と「missingToken生成」の二つを追加で行う。これによってある程度不正な構文でも、不必要/不足トークンを判断し、後続の構文解析に影響が及ばないようにできる。
func func ()
↑identifierではない、不必要なトークンと判断して解析継続(Recovery)
↑identifierが無い、identifierが不足していると判断して解析継続(`MissingToken`)
実装はここら辺
Recovery (UnexpectedNodesSyntax)
不要なトークンをパースする処理。期待するトークンまで先読みし、期待するトークンの前に存在した不要なトークンを全てUnexpectedNodesSyntaxとしてパースする。その後期待するトークンをパースする。
func func hoge()
↑UnexpectedNodesSyntax
各RawXXSyntaxはUnexpectedNodesSyntaxを受け取ることができ、recoveryによってパースされたUnexpectedNodesSyntaxはここに格納される。
また、expect()を使わずにUnexpectedNodesSyntaxを生成する処理が書かれていることもあるっぽい。
MissingToken
不足トークンを生成する処理。期待するトークンが存在しなかった場合、presene == .missingなRawTokenSyntaxを生成し通常通りRawXXXSyntaxに格納する。
Lookahead
先読み専用のParser。持っている情報はParserとほぼ同等で、LexmeSequenceを持つ。一つ先のトークンを見るときはParser.peak()で十分だが、k個先を見る場合はLookaheadを使う。トークン列を先に進めてもParserとLexmeSequenceの状態を共有しない。
必要になったタイミングでParserの状態をコピーしてLookaheadを生成する。使い終わったら捨てる。
// 現在のParserの状態をコピーした先読みParserを生成
var lookahead = self.lookahead()
// 一つ読み進める
lookahead.consumeAnyToken()
// 次が`{`かチェック
if lookahead.peek().rawTokenKind == .leftBrace {
...
}
インターフェース (eat,at,consume)はParserと同じだが、帰り値がRawTokenSyntaxではなくBoolとなっているためパフォーマンスが良い。(先読みならトークンの判定だけできれば良いのでRawTokenSyntaxを生成する必要がない)
実はParserとLookaheadは同じTokenConsumer protocolに準拠しており、protocol extensionによってeat,at,consumeの実装の一部がmixinされている。
Lookaheadを使う必要がある例(LL(2): 2つ先のトークンを読まないと構文が確定しない)
// MultipleTrailingClosure
hoge {
}
label: {}
↑現在地点
// TrailingClosure+ラベル付きスコープ
hoge {
}
label: for a in b {}
↑現在地点
現在地点がidentifier(label)、次が:の時、その次が{だったらMultipleTrailingClosureになるが、forやswitchだったらラベル付きスコープになる。
また、先述のRecoveryもLookaheadを使用している。
インクリメンタルパース
SwiftParserにはインクリメンタルパース機能(前回パース時から入力が変更した箇所だけを再パースする、いわゆる「キャッシュ」機能)が存在する。
import SwiftSyntax
import SwiftParser
var source = """
let a = 10
let b = 20
"""
// 初回のパース
var result = Parser.parseIncrementally(source: source, parseTransition: nil)
// letをvarに
source = """
var a = 10
let b = 20
"""
// 2回目のパース、変更点に関連する部分(このコードでは一行目だけ)再パースされる
result = Parser.parseIncrementally(
source: source,
parseTransition: IncrementalParseTransition(
previousIncrementalParseResult: result,
// 変更点を教える
edits: ConcurrentEdits(
IncrementalEdit(offset: 0, length: 3, replacement: "var".compactMap(\.asciiValue))
),
reusedNodeCallback: {
// キャッシュヒットしたNodeをCallbackで教える(どういう用途?)
// let b = 20 が該当
print($0)
}
)
)
parseIncrementallyの返り値の型はIncrementalParseResultとなっており、これはtree: 構文木(普通のparseの結果と同値)に加えキャッシュの実態であるlookaheadRanges: LookaheadRangesを持つ型。
LookaheadRanges
[RawSyntax.ID: Int]を持つ単純な型。Parserのstoread propertyとして保持されている。
-
RawSyntax.ID: RawSyntaxへのポインタ -
Int: 「そのNodeを解析するためにNodeの構文の先頭から何バイト先まで先読みしたか」を表す数字- つまりそのNodeに影響する入力文字列の範囲を表す。この範囲が変更されたか否かでキャッシュの有効性を判断している。
registerNodeForIncrementalParse: キャッシュ登録
lookaheadRengesに書き込むだけのシンプルな関数。
lexemes.lookaheadTracker.pointee.furthestOffsetは現在入力のどこまで先読みしたかを表すproperty。
現状この関数を読んでいるタイミングは以下二つのSyntaxをパースする時。つまりこれらの単位でキャッシュが作られる。
-
RawMemberBlockItem: 型のメンバー(変数・関数) -
RawCodeBlockItem: トップレベルでの1 Statement(型定義・変数宣言・その他if文など)
loadCurrentSyntaxNodeFromCache: キャッシュの読み出し
parseLookup: IncrementalParseLookupのメソッドを読んでいる。この型が具体的なキャッシュ読み出しロジックを持つ。
キャッシュの読み出しタイミングは上記キャッシュ作成タイミングと同じ。キャッシュがある場合は構文解析をスキップしてキャッシュされたNodeを返す。
構文木のデータ構造
RawXXXSyntax
parserによって生成されるRawXXXSyntaxはNodeの情報を直接のpropertyとして持っていません。raw: RawSyntaxが情報を持っており、各RawXXXSyntaxはRawSyntaxの情報を読むための"View"、という構造です。
public var funcKeyword: RawTokenSyntaxのようなpropertyはrawを参照しているcomputed property。
RawSyntax
RawSyntaxもNodeの情報を直接のpropertyとして持っておらず、RawSyntaxDataへのポインタを持っています。RawSyntaxDataがNodeの情報を直接持っている本体。
(多分)ポインタを直接外側に見せないためのラッパーがRawSyntax。
RawSyntaxData
実際に構文木の情報を直接持っている、構文木の本体とも言える型。
enum PayloadでDataの種類が定義されている。
parsedToken, materializedToken: 葉。RawTokenKindなどを持つ。
RawTokenSyntaxのinitではPayload.parsedTokenのRawSyntaxDataを元にraw: RawSyntaxをinitしている。
layout: 子を持つNode。そのNodeの種類(RawXXXSyntaxと1対1対応のenum)や子のRawSyntaxへのポインタを持つ。
RawTokenSyntax以外の(葉でない)initではPayload.layoutを元にraw: RawSyntaxをinitしている。layoutの持つポインタに子のRawSyntaxを代入している。
SyntaxArena
そもそも何でRawSyntaxDataはポインタで扱うの?という疑問の答えがSyntaxArena。
全てのRawSyntaxDataはSyntaxArenaが管理するポインタの先に格納されている。
Contrary to Swift’s usual memory model, syntax node's are not individually
reference-counted. Instead, they live in an arena. That arena allocates a
chunk of memory at a time, which it can then use to store syntax nodes in.
This way, only a single memory allocation needs to be performed for multiple
syntax nodes and since memory allocations have a non-trivial cost, this
significantly speeds up parsing.
Swiftの通常のメモリモデルとは異なり、構文ノードは個別に参照カウントされません。その代わりに、アリーナ内に保持されます。このアリーナは一度にメモリの一塊を割り当て、そのメモリを構文ノードの格納に使用します。この方法により、複数の構文ノードに対して単一のメモリ割り当てのみが必要となり、メモリ割り当てにコストがかかるため、パースの速度が大幅に向上します。
(例えばRawSyntaxDataをclassにして)パース中逐次メモリをallocateするとコストが重いので、SyntaxArenaがパースの最初にドカッっと大量のメモリをallocateし、パース中はそれを割り当てるアプローチにすると速度が大幅に向上する、って感じ?
Parserがarena: SyntaxArenaを持っており、1回のパース内で同じインスタンスを使う(SyntaxArenaはclass)。SyntaxArenaがdeinitされたら全てのRawSyntaxDataも削除されるが、Syntaxのルートノード(SourceFileSyntax)がSyntaxArenaを持っているので、Parserは削除しても大丈夫。
Syntax
RawSyntaxを内部にもつ。つまりSyntaxもRawSyntaxを操作するためのラッパー。
RawSyntaxと違う点としてnodeを書き換えるメソッドなどが生えている。RawSyntaxをさらにラップする意図はこの書き換え機能?
XXXSyntax
SwiftParserの最終的な出力。Syntaxを内部に持つ。つまりXXXSyntaxもRawSyntaxを操作するためのラッパーで、直接Nodeの情報を保持しているわけではない。こちらもnodeを書き換えるメソッドが生えている。
つまり構造的にはこういうこと
RawXXXSyntax(RawSyntax(SyntaxArenaAllocatedPointer<RawSyntaxData>))XXXSyntax(Syntax(RawSyntax(SyntaxArenaAllocatedPointer<RawSyntaxData>)))
雑に図を書くとこんな感じ
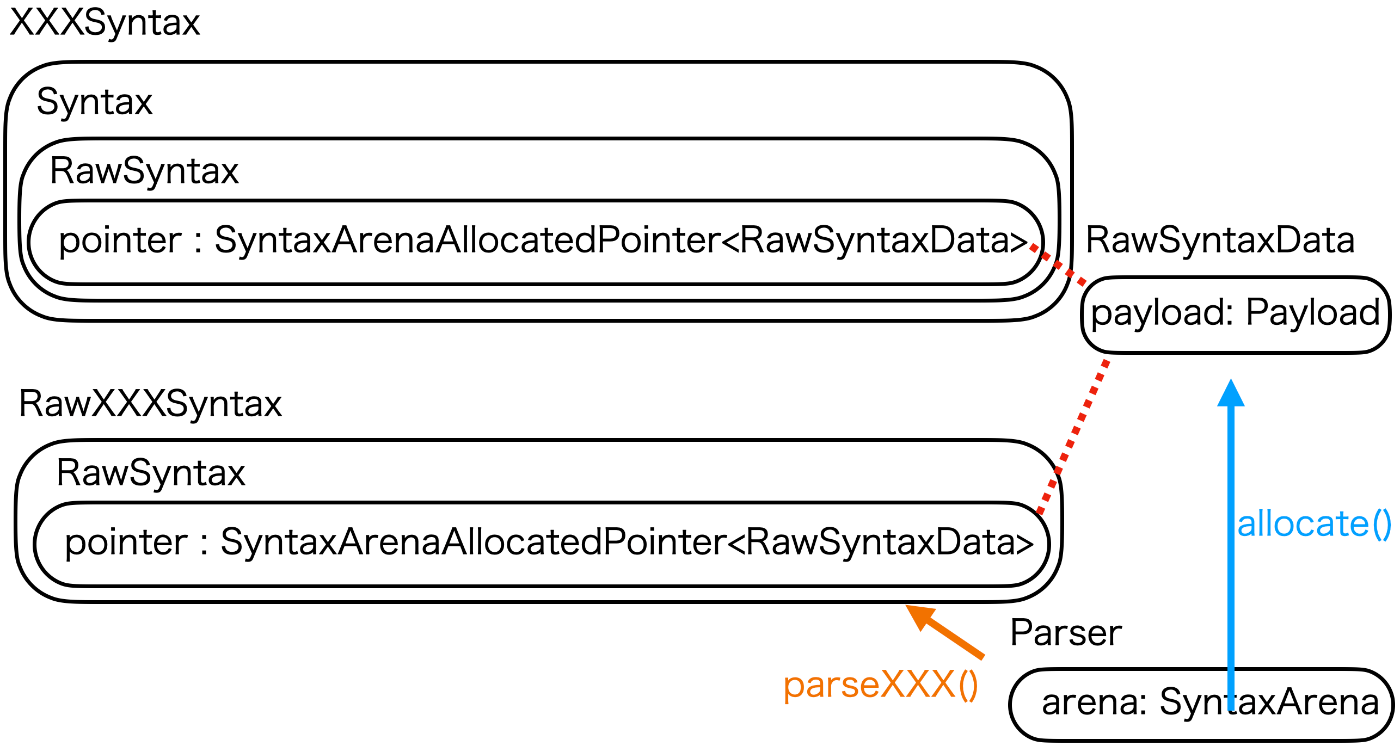
子を持つNodeの場合は、実際にはRawSyntaxDataがRawSyntaxへのポインタを持っており、RawXXXSyntaxはRawSyntaxDataのポインタを通して子のRawSyntaxを参照し、RawXXXSyntaxを生成する。(RawXXXSyntaxはほぼデータを持たずコストが軽いので毎回生成)

CodeGeneration
SwiftParser/Syntaxのコードは一部コード生成されている。(主に型定義部分)それが同リポジトリで別のパッケージであるCodeGeneration。
CodeGenearationのコード生成はSwiftSyntaxBuilderを利用しているので、SwiftSyntaxのソースコードの一部はSwiftSyntaxを使って作られていることになる。(面白い)
SwiftSyntax/generated, SwiftParser/generatedにあるファイルはCodeGenerationによって生成されたものである。例えばRawXXXSyntaxとXXXSyntaxの定義もコード生成されている。
CodeGenerationに存在するNode型で種類や子要素を定義すると
RawXXXSyntax, XXXSyntaxとして書き出されるという流れ。
トークン/構文の間にあるUnexpectedSyntax(先述。異常系のためのSyntax)などもコード生成時に自動で挿入されるっぽい。
入力文字列がSourceFileSyntaxになる流れ
上記データ構造を経由してソースコードの入力文字列がSourceFileSyntaxになる流れを見ていく。
Parser.parse(source: String) -> SourceFileSyntax
内部でParserをinitし、SourceFileSyntax.parseを呼ぶだけ。
Parser.initはSyntaxArenaの生成などを行う他、Lexer.tokenizeを呼ぶことでLexemeSequenceの生成を行いstored propertyに保存する。
- SourceFileSyntax.parse(from: inout Parser)
-
parser.parseSourceFile()によってRawSourceFileSyntaxをパース- 再帰的にプログラム全体をパースするため、ここで
RawXXXSyntaxのパース処理も行われる。
- 再帰的にプログラム全体をパースするため、ここで
-
RawSourceFileSyntax内部のRawSyntaxを元にSyntaxを生成 -
Syntax.castによってSourceFileSyntaxを生成(.castはSourceFileSyntax.initと等価)
つまり平たく書けばSourceFileSyntax(Syntax(RawSourceFileSyntax().raw))となる。
Discussion