SwiftのSIMDとその利用方法
はじめに
CPUにはSIMDと呼ばれる、一つのCPU命令で複数の値を演算できる高速演算機能が存在し
画像・動画・音声処理などパフォーマンスが求められるシーンで広く活用することができます。
実はSwiftにもSIMDがStandard Libraryに存在しており、visionOS開発にも用いるRealityKitでも必要になることがあります。
SIMD型は平たく言えば「演算ができる固定長Array」です。
let a = SIMD4<Float>(1.0, 2.0, 3.0, 4.0)
let b = SIMD4<Float>(5.0, 6.0, 7.0, 8.0)
let add = a + b // 6.0, 8.0, 10.0, 12.0
この型に定義された演算子を使うことによってCPUの高速演算機能を利用することができます。
Floatなど利用する数値の型とハードウェアが対応するSIMD命令の種類にもよりますが、Floatだと理論値的には4-16倍早くなります。
この記事ではSIMD自体の(簡単な)説明をした後、SwiftのSIMDの使い方・型の設計・API一覧などを解説します。
SIMDとは
SIMDはSingle Instruction, Multiple Dataの略で
一つの(機械語)命令で複数のデータを処理する仕組み(もしくは概念)のことを指します。
CPUのSIMD命令
CPUの「命令セット」や「機械語・アセンブリ」などの概念がわからない方はこちら
CPUのキーワード(ブランド、命令セット、マイクロアーキテクチャ、拡張命令セット)の説明
SIMDの概念に基づく高速な処理・演算をCPUの命令として提供するのがSIMD命令です。
通常、基本的な機械語の命令では、演算器で最大64bitのデータ間で演算を行います。これをスカラ演算と呼びます。
スカラ演算のイメージ

現代の多くのCPUのアーキテクチャの命令セット(の拡張命令セット)にはSIMDの概念に基づいたSIMD演算命令(ベクトル演算命令)が存在し、ハードウェアには専用回路のSIMD演算器と64bit以上の長さを持つベクトルレジスタが存在します。演算できるビット長はそのCPUが対応している拡張セットに依存します。
例えばx86_64に存在するSIMD演算命令拡張命令セットAVX2は、最大256bitのデータ間で演算を行います。これをベクトル演算と呼びます。
ベクトル演算のイメージ
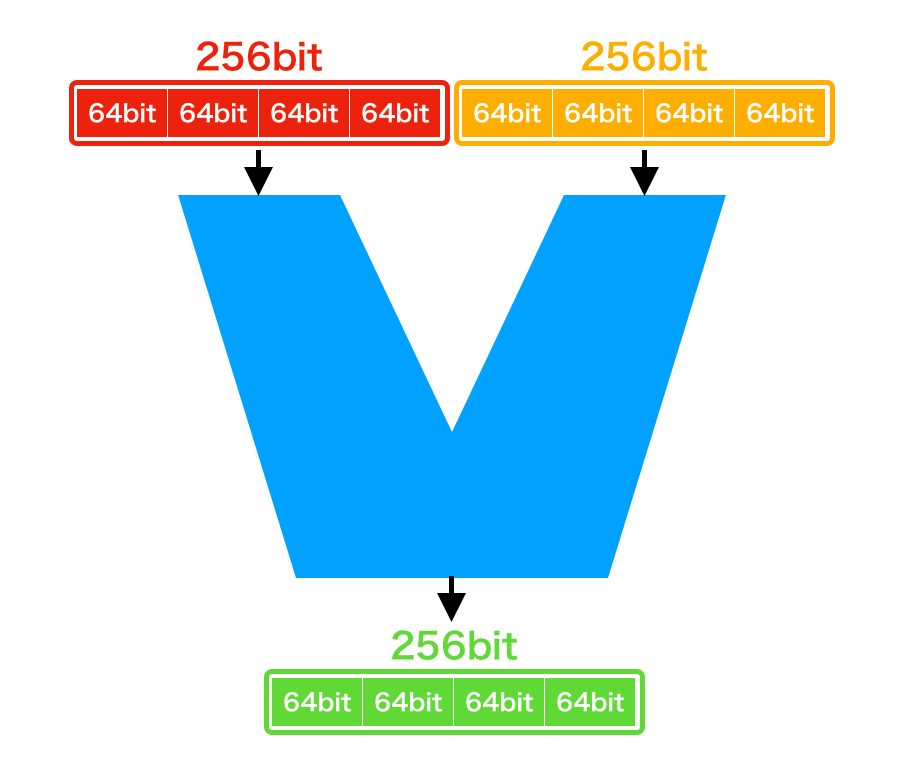
このように複数のデータを同時・並列(データ並列)に計算することで高速化を図るのがSIMDです。
ここで重要なのが、ベクトルレジスタ (ここでは256bit) に複数のデータを詰めることができると言う点です。
例えば、64bit整数は256bitのレジスタに4個詰めることができるため、スカラ演算よりも理論値4倍の演算速度が出ます。16bit整数だと256bitのレジスタに16個詰めることができるため、理論値16倍となります。
(このように、SIMD演算ではビット幅が小さい型を用いることがメリットになります。)

これが基本的なSIMDとSIMD演算の考え方です。
他のSIMD演算命令の拡張命令セットを簡単に紹介すると以下のようなものがあります。
どの拡張命令セットが利用できるかは実際のCPUに依存します。
(が、2024年現在だと大体AVX2とNEONです)
- SSE2 (x86_64, Pentium 4 2000年~): 128 bit
- AVX2 (x86_64, Core i7 4Gen 2013年~): 256 bit
- AVX512 (x86_64, Xeon Phi 2016年~): 512 bit
- NEON (ARM64, armv7 2005年?~): 128 bit
SIMD演算命令を利用する方法
自分のプログラムでSIMD演算命令を利用したい場合、主に以下のような方法があります。
アセンブリ
基本的に機械語とアセンブリは1対1対応なので、冒頭の例のようにアセンブリを記述することでSIMD演算命令を利用できます。
AVX2 (x86_64)
// load
vmovdqu ymm0, [a]
vmovdqu ymm1, [b]
// 加算
vpaddq ymm0, ymm0, ymm1
// store
vmovdqu [result], ymm0
NEON (arm)
// load
ldr q0, [a]
ldr q1, [b]
// 加算
add v0.2d, v0.2d, v1.2d
// store
str q0, [result]
メリット
- 思い通りにSIMD演算命令を利用できるので、最適化の自由度が高い
デメリット
- (ご存知の通り)アセンブリでプログラムを利用するのはかなり難易度が高く、バグの混入、保守性の低さなど様々な問題が発生する
- 命令セットごとにアセンブリ命令が変わるため、x86_64とArmで別々に実装する必要がある
Intrinsics
SIMD演算命令に変換される組込み関数がC言語向けに提供されており、これを用いることでCやC++などを使って言語機能のサポートを得ながらSIMD命令を発行するプログラムを記述できます。
AVX2 (x86_64)
#include <immintrin.h>
// AVX2は最大256bitなのでint64は4つまで
int main() {
// データの初期化
__m256i a = _mm256_set_epi64x(1, 2, 3, 4);
__m256i b = _mm256_set_epi64x(4, 3, 2, 1);
// 加算
// [5, 5, 5, 5]
__m256i result = _mm256_add_epi64(a, b);
// 結果を配列に保存
int64_t res[4];
_mm256_storeu_si256((__m256i *)res, result);
}
NEON (arm)
#include <arm_neon.h>
// NEONは最大128bitなのでint64は2つまで
int main() {
// データの初期化
int64_t a_data[2] = {1, 2};
int64_t b_data[2] = {4, 3};
int64x2_t a = vld1q_s64(a_data);
int64x2_t b = vld1q_s64(b_data);
// 加算
// [5, 5]
int64x2_t result = vaddq_s64(a, b);
// 結果を配列に保存
int64_t res[2];
vst1q_s64(res, result);
return 0;
}
公式ドキュメントも提供されています。
x86_64
arm
メリット
- プログラミング言語上で利用できるため、アセンブリより書きやすく、保守性が上がっている
デメリット
- アセンブリよりはマシだが、可読性が低く専門的な知識が必要になる
- 命令セットごとにIntrinsicsの関数が変わるため、x86_64とArmで別々に実装する必要がある
Intrinsicsのラッパーライブラリ
- libsimdpp
- Appleの
<simd/simd.h>
Intrinsicsを抽象化してラップし型や関数を強化・使いやすくした物です。C++では演算子オーバーロードなどを用いて直感的に操作もできます。
#include <simd/simd.h>
int main() {
// データの初期化
simd_long2 a = simd_make_long2(1, 2);
simd_long2 b = simd_make_long2(4, 3);
// 加算
// 演算子オーバーロード
simd_long2 result = a + b;
// 結果を配列に保存
int64_t res[2];
res[0] = result[0];
res[1] = result[1];
return 0;
}
メリット
- 命令セットのIntrinsics差分をライブラリが吸収してくれるため、単一のコードで複数の命令セットに対応できる
- 可読性が高く必要な専門的知識が少ない
デメリット
- (ラッパーライブラリなため) Intrinsicsに比べるとチューニングできる範囲に限度がある
自動ベクトル化
いくつかのコンパイラにはSIMD演算命令に変換できそうな一連のコードを検知して自動でSIMD演算命令を発行する自動ベクトル化と呼ばれる機能が入っています。
Swiftコンパイラはllvmの自動ベクトル化機能を利用しており、次のコードを-O (リリースビルドのデフォルト最適化) でコンパイルするとベクトル命令が出力されます。
func add(_ a: [Float], _ b: [Float]) -> [Float] {
var result: [Float] = .init(repeating: 0, count: a.count)
for i in 0..<a.count {
result[i] = a[i] + b[i]
}
return result
}
かなり理想的な機能に感じますが、自動ベクトル化は万能ではありません。
例えばappendにするだけで自動ベクトル化が効かなくなります。
appendには配列の実際の長さを調整する処理などが含まれ、単純にSIMDを適応できるプログラムではなくなったからです。
func addArray(_ a: [Float], _ b: [Float]) -> [Float] {
var result: [Float] = []
for i in 0..<a.count {
result.append(a[i] + b[i])
}
return result
}
メリット
- (コンセプトとしては)プログラマが気にしなくてもベクトル演算が利用できる
デメリット
- 現実的には自動ベクトル化の対応範囲は狭く、パフォーマンスが求められる場所で用いるのは現実的ではない
- 実際にベクトル化しているかどうか確認するのにアセンブリを見る必要があるのは現実的ではない
- エンジニアがSIMDを利用したい・プログラムを高速化したい状況では、確実にSIMD演算命令が発行されてほしい
SwiftのSIMD
Swift 5.0からSIMD関連の型がStandard Libraryに実装されました。
公式ドキュメント
アプローチ
SwiftのSIMDは Intrinsicsのラッパーライブラリ のアプローチをとっています。
SE-0229 SIMD Vectorsにおいて、理由として以下が挙げられていました。
- 自動ベクトル化は十分な解決策ではない
- ISAのIntrinsics差分を吸収し、クロスプラットフォームなAPIを提供したい
- Swiftの型システムを生かしたジェネリックなSIMD利用を可能にしたい
また、Swift EvolutionのMotivationで次のようなユースケースが例示されていました。
SIMD演算によるパフォーマンスが必要になる処理(画像・音声処理など)
SIMD本来の用途と言えます。純粋にパフォーマンスが必要で、SIMD演算命令を発行したいユースケースです。
例えば画像処理やデジタル信号処理を行うAccelerateフレームワークがこのユースケースといえます。(今はCやC++で実装されていますが)
(Swift Evolutionからの引用)
Task 1: SIMD programming
Essentially every modern CPU has support for SIMD ("Single Instruction, Multiple Data") instructions in hardware. Without getting into a long discussion of the architectural details, effective use of these instructions allows 2-10x better performance than is otherwise possible for a large class of data-parallel problems, without incurring the synchronization and data-movement hassles of working with the GPU.
最近のCPUは基本的にすべて、ハードウェアでSIMD(「Single Instruction, Multiple Data」)命令をサポートしている。アーキテクチャの詳細について長い議論をするまでもなく、これらの命令を効果的に使用することで、GPUを使用する場合のような同期やデータ移動の煩わしさを伴うことなく、多くのデータ並列問題で他の方法よりも2~10倍優れた性能を発揮することができます。
座標表現(AR, VR, CGなど)
2Dや3Dの座標表現ができるデータ構造、というユーズケースです。
実際にVisionOS開発で用いるRealityKitの座標表現は(一部)SIMD3になっています。
let point = SIMD2<Float>(x: 1.0, y: 2.0)
CoreGraphicsのCGPointやSceneKitのSCNVectorNなど、各ライブラリで2Dや3D表現ができるデータ構造はありましたが、Swiftの標準ライブラリにはありませんでした。このユースケースを標準ライブラリから提供しよう、というモチベーションです。Swiftが共通のデータ構造を提供することでライブラリ間のデータ構差異などがなくなるメリットや、ついでにちょっとした演算や処理でSIMD命令が発行されて高速化されるというメリットもあります。
また、SIMDは要素毎の計算(element-wise, point-wise)をサポートします。これによって座標表現においては配列などよりも表現力の高いデータ構造と言えます。
let a = SIMD2<Float>(x: 1.0, y: 2.0)
let b = SIMD2<Float>(x: 1.0, y: 3.0)
a == b // false 全要素の一致
a .==b // (true, false) 要素毎の一致
Task 2: geometry primitives
There is a large class of computational tasks (graphics and animation, image processing, AR, VR, computer vision) that want to have 2, 3, and 4 dimensional vector and matrix types. For these applications, these types are just as fundamental as Int and Array are for "normal" programming--they are the foundation upon which everything else is constructed.
These tasks require both elementwise operations, as well as some operations on types as abstract vectors--things like the dot and cross products, vector length, and orientation tests.
計算タスク(グラフィックスやアニメーション、画像処理、AR、VR、コンピューター・ビジョン)の中には、2次元、3次元、4次元のベクトルや行列の型を持ちたがるものが数多くある。これらのアプリケーションにとって、これらの型は「通常の」プログラミングにおけるIntやArrayと同様に基本的なものであり、他のすべてが構築される基礎となる。
これらのタスクでは、要素演算と、抽象ベクトルとしての型に対する演算の両方が必要となる。
型と関係
ここからは、SwiftのSIMDの設計と利用方法をまとめていきます。
structは2個だけです。
- struct
SIMDn<Scalar: SIMDScalar>: SIMD - struct
SIMDMask<Storage: SIMD>: SIMD
それに関連するprotocolが3つあります。
- protocol
SIMDScalar - protocol
SIMD - protocol
SIMStorage
SIMD[N]<Scalar>
public struct SIMD2<Scalar>: SIMD where Scalar: SIMDScalar
public struct SIMD3<Scalar>: SIMD where Scalar: SIMDScalar
public struct SIMD4<Scalar>: SIMD where Scalar: SIMDScalar
...
最も基本になるstructです。配列のようなデータ構造だと捉えるとわかりやすいです。
利用者が指定する要素が二つあります。
-
[N]: structが保持する要素数を示します。2,3,4,8,16,32,64が提供されています。- つまり、
SIMD2,SIMD3,SIMD4, ...とそれぞれが別の型として定義されています。 - 要素数は2の累乗です。3だけは3D演算等で使うことが多いため例外的に定義されています。
- つまり、
-
Scalar: 各要素の型を示します。ArrayでいうところのElementです。- 後述する
protocol SIMDScalarに準拠している必要があります。
- 後述する
Scalarの値を元にSIMDを生成します。
let a = SIMD2<Float>(1.0, 2.0)
let b = SIMD3<Float>(1.0, 2.0, 3.0)
let c = SIMD4<Float>(1.0, 2.0, 3.0, 4.0)
structのまま四則演算ができます。
let a = SIMD4<Float>(1.0, 2.0, 3.0, 4.0)
let b = SIMD4<Float>(1.0, 2.0, 3.0, 4.0)
a + b // SIMD4<Float>(2.0, 4.0, 6.0, 8.0)
a - b // SIMD4<Float>(0.0, 0.0, 0.0, 0.0)
a * b // SIMD4<Float>(1.0, 4.0, 9.0, 16.0)
a / b // SIMD4<Float>(1.0, 1.0, 1.0, 1.0)
これでSIMD演算命令を発行できます。
59行目のaddps (output.a : Swift.SIMD4<Swift.Float>)(%rip), %xmm0
要素数が違う型同士は演算できません。
let a = SIMD3<Float>(1.0, 2.0, 3.0)
let b = SIMD4<Float>(1.0, 2.0, 3.0, 4.0)
print(a * b) // 🔴 Binary operator '*' cannot be applied to operands of type 'SIMD3<Float>' and 'SIMD4<Float>'
以上がSIMDの基本です。
型の関係を見ていきましょう。
SIMDScalar protocol
public protocol SIMDScalar : _BitwiseCopyable {
associatedtype SIMDMaskScalar: SIMDScalar & FixedWidthInteger & SignedInteger
where SIMDMaskScalar.SIMDMaskScalar == SIMDMaskScalar
associatedtype SIMD2Storage: SIMDStorage where SIMD2Storage.Scalar == Self
associatedtype SIMD4Storage: SIMDStorage where SIMD4Storage.Scalar == Self
associatedtype SIMD8Storage: SIMDStorage where SIMD8Storage.Scalar == Self
associatedtype SIMD16Storage: SIMDStorage where SIMD16Storage.Scalar == Self
associatedtype SIMD32Storage: SIMDStorage where SIMD32Storage.Scalar == Self
associatedtype SIMD64Storage: SIMDStorage where SIMD64Storage.Scalar == Self
}
SIMDの値として用いることができることを表すprotocolです。以下の型が標準で準拠しています。
Double
Float
Float16
Int
Int16
Int32
Int64
Int8
UInt
UInt16
UInt32
UInt64
UInt8
具体的にprotocolが要求する実装はなく、associatedTypeで型を要求するだけです。
基本的に自分で新しくSIMDScalarを準拠されるようなケースはなく、標準で準拠している型を利用することになります。
SIMD protocol
public protocol SIMD<Scalar>:
SIMDStorage,
Codable,
Hashable,
CustomStringConvertible,
ExpressibleByArrayLiteral,
_BitwiseCopyable
{
associatedtype MaskStorage: SIMD
where MaskStorage.Scalar: FixedWidthInteger & SignedInteger
}
structのSIMDを抽象化するprotocolです。以下3点がrequirementとして存在します。
-
Scalar: 要素の型 -
scalarCount: 要素数 -
subscript: 要素にアクセスする手段
実用例として、すべてのSIMD[N]で使える新しい関数を定義したりできます。
func abs<Vector: SIMD>(_ simd: Vector) -> Vector where Vector.Scalar: FloatingPoint {
simd.replacing(with: -simd, where: simd .< 0)
}
SIMDMask
public struct SIMDMask<Storage>: SIMD
where Storage: SIMD,
Storage.Scalar: FixedWidthInteger & SignedInteger {
public var _storage: Storage
public typealias MaskStorage = Storage
public typealias Scalar = Bool
}
上記struct SIMD, SIMDScalar, protocol SIMDがSIMDの基本要素ですが、もう一つMaskと呼ばれるトピックのための型があります。
SIMDでは各要素毎の比較ができます。この比較もSIMD演算によって高速に動作します。
その結果をmaskと呼び、SIMDMaskは専用の型です。
let a = SIMD4<UInt8>(1, 2, 3, 4)
let b = SIMD4<UInt8>(4, 3, 2, 1)
a .> b // SIMDMask<SIMD4<Int8>>(false, false, true, true)
単純に判定結果をforでループして処理することもできますが、maskを引数にとるメソッド・関数で利用できます。
let a = SIMD4<Float>(1.0, -1.0, 2.0, -2.0)
let mask = a .< 0
// maskがtrueの要素だけ`-a`で置き換える
a.replacing(with: -a, where: mask) // SIMD4<Float>(1.0, 1.0, 2.0, 2.0)
// trueなものが一つでもあるか
any(mask) // true
// すべてtrueか
all(mask) // false
SIMDStorage protocolとSIMD命令
やや複雑なので、このセクションは単純にSIMDを利用する用途では理解する必要はないです。
public protocol SIMDStorage : _BitwiseCopyable {
/// The type of scalars in the vector space.
associatedtype Scalar: Codable, Hashable
var scalarCount: Int { get }
/// Creates a vector with zero in all lanes.
init()
/// Accesses the element at the specified index.
///
/// - Parameter index: The index of the element to access. `index` must be in
/// the range `0..<scalarCount`.
subscript(index: Int) -> Scalar { get set }
}
-
Scalar: 要素の型 -
scalarCount: 要素数 -
subscript: 要素にアクセスする手段
を要求するシンプルなprotocolです。
ここで、SIMDScalarがSIMDStorageに準拠した型を要求する話に戻ると
具体的にprotocolが要求する実装はなく、
associatedTypeで型を要求するだけです。
Scalar側で各要素毎のSIMDStorageの型を提供する必要があります。
各SIMDScalarはSIMDStorageに準拠させたSIMD2Storage~SIMD64Storage型を内部で新たに定義しています。
実際のソースコード
extension Int8: SIMDScalar {
public typealias SIMDMaskScalar = Int8
/// Storage for a vector of two integers.
@frozen
@_alignment(2)
public struct SIMD2Storage: SIMDStorage, Sendable {
public var _value: Builtin.Vec2xInt8
...
}
@frozen
@_alignment(4)
public struct SIMD4Storage: SIMDStorage, Sendable {
public var _value: Builtin.Vec4xInt8
...
}
Builtin.Vec2xInt8, Builtin.Vec4xInt8という見慣れない型が出てきました。
実はこの型はSIMD演算命令を出力する機能を持つ、SwiftのSIMDの実体とも言えるコンパイラの組み込み型です。(逆に言えば、これ以外のstruct SIMDやprotocol SIMDStorage自体は高速化においてなんのトリックもないただの「View」です。)
SIMDに定義されている演算子などもBuiltin.add_Vec2xInt8(_ a:Builtin.Vec2xInt8, _ b: Builtin.Vec2xInt8)のような組み込み関数を呼ぶ実装になっています。
/// The wrapping sum of two vectors.
@_alwaysEmitIntoClient
public static func &+(a: Self, b: Self) -> Self {
Self(Builtin.add_Vec2xInt8(a._storage._value, b._storage._value))
}
/// The wrapping difference of two vectors.
@_alwaysEmitIntoClient
public static func &-(a: Self, b: Self) -> Self {
Self(Builtin.sub_Vec2xInt8(a._storage._value, b._storage._value))
}
/// The pointwise wrapping product of two vectors.
@_alwaysEmitIntoClient
public static func &*(a: Self, b: Self) -> Self {
Self(Builtin.mul_Vec2xInt8(a._storage._value, b._storage._value))
}
この組み込み型は最終的にはLLVMでSIMDを表現する為に存在するFixedVectorTypeに変換、組み込み関数はFixedVectorTypeに対する演算として変換され、LLVMが実際のアセンブリにSIMD演算命令を出力する流れになります。
(一応LLVMの実装・ハードウェア・最適化レベルによっては通常命令にフォールバックされる可能性もあります)
SIMDScalarが2,4,8,16...と要素毎にSIMDStorageを要求する設計にしているのも、Builtin.Vec2xInt8, Builtin.Vec4xInt8, Builtin.Vec8xInt8と組み込み型を変えたい需要があるからだと思います。
問題点
一方でSwiftのSIMDには問題点がいくつかあります。
組み込み関数で実装していない処理が多い
組み込み関数を呼び出すことでSIMD命令を発行していることは先述した通りですが
いくつかの演算子やメソッドが組み込み関数を呼び出していないケースがあります。
一番酷いのは、FloatingPointの四則演算は組み込み関数が実装されていません。
TODO的なコメントと共に、ただのfor文の実装しかありません。
つまり、SIMDn<Float>やSIMDn<Double>の四則演算はSIMD命令が出力される保証がありません。
// Implementations of floating-point operations. These should eventually all
// be replaced with @_semantics to lower directly to vector IR nodes.
extension SIMD where Scalar: FloatingPoint {
public static func +(a: Self, b: Self) -> Self {
var result = Self()
for i in result.indices { result[i] = a[i] + b[i] }
return result
}
}
ただ、実際には自動ベクトル化が効きやすい実装になっているため、自動ベクトル化によってベクトル化されていることが確認できます。
ジェネリクスだと組み込み関数が呼ばれない
例えばprotocolのSIMDを利用してジェネリックな処理を書いた場合
func add<Vector: SIMD>(a: Vector, b: Vector) -> Vector where Vector.Scalar: FixedWidthInteger {
a &+ b
}
この演算子&+の呼び出しは組み込み関数を呼び出しません。
なぜなら、演算子&+はSIMDのrequirementsに存在しないからです。
実際にはprotocol extensionでforループの実装が存在するので、こちらが呼ばれてしまいます。
extension SIMD where Scalar: FixedWidthInteger {
// ただのforループ こっちが呼ばれる!!
public static func &+(a: Self, b: Self) -> Self {
var result = Self()
for i in result.indices { result[i] = a[i] &+ b[i] }
return result
}
}
extension SIMD2 where Scalar: FixedWidthInteger {
// 組み込み関数
public static func &+(a: Self, b: Self) -> Self {}
}
Matrix, quaternionが非対応
座標の三次元回転を扱う際にquaternionという概念を利用しますが、SwiftのSIMDは非対応なのでAccelerate/simdを利用する必要があります。行列も同様です。
API一覧
生成方法
// ラベルあり (SIMD2,3,4のみ)
SIMD3<Float>(x: 1.0, y: 2.0, z: 3.0)
// ラベルなし
SIMD3<Float>(1.0, 2.0, 3.0)
// arrayLiteral
let a: SIMD3<Int> = [1, 2, 3]
// Sequence
SIMD3<Int>([1,2,3])
let array = [1,2,3,4,5,6]
SIMD3<Int>(array[1..<4])
SIMD3<Int>(array.suffix(3))
// すべて0
SIMD3<Int>.zero
// すべて1
SIMD3<Int>.one
// 繰り返し
SIMD3<Int>(repeating: 1)
// 拡張
let simd2 = SIMD2<Int>(1, 2)
let simd3 = SIMD3<Int>(simd2, 3)
let simd4 = SIMD4<Int>(simd3, 4)
// 下位・上位
let simd2 = SIMD2<Int>(1, 2)
let simd4 = SIMD4(lowHalf: simd2, highHalf: simd2)
let simd8 = SIMD8(lowHalf: simd4, highHalf: simd4)
// 乱数
SIMD3<Int>.random(in: 0..<10)
// 浮動小数店から整数に変換
let float = SIMD4<Float>(1.1, 1.2, 1.5, 1.9)
SIMD4<Int32>(float, rounding: .up)
shuffle
let xyz = SIMD3<Int>(1, 2, 3)
let xzy = simd[.init(0, 2, 1)] // SIMD3<Int>(1, 3, 2)
let xy = simd[.init(0, 1] // SIMD2<Int>(1, 2)
subscriptにSIMDを入れることで要素の順序を入れ替えたり抽出したりできます。
本来shuffle/permuteと呼ばれるSIMD命令が存在するのですが、現在 (Swift5.10) ではBuiltin関数を利用しておらず、命令も発行されていないようです。
pointwiseMin, pointwiseMax
let a = SIMD3<Int>(1, 4, 5)
let b = SIMD3<Int>(2, 3, 6)
pointwiseMax(a, b) // SIMD3<Int>(2, 4, 6)
pointwiseMin(a, b) // SIMD3<Int>(1, 3, 5)
二つのSIMDを取り、要素毎のmin,maxを選択したSIMDを返す関数です。
こちらも本来max, minのSIMD命令があるのですが、Builtin関数を利用しておらず命令が発行されていません。
clamp, clamped
let a = SIMD3<Int>(1, 3, 5)
let min = SIMD3<Int>(repeating: 2)
let max = SIMD3<Int>(repeating: 4)
a.clamped(lowerBound: min, upperBound: max) // SIMD3<Int>(2, 3, 4)
min, max
let a = SIMD3<Int>(1, 4, 5)
a.min() // 1
a.max() // 5
こちらは一つのSIMDの要素内でmin, maxを取得する関数です。
sum, wrappedSum
let float = SIMD3<Flaot>(1.0, 2.0, 3.0)
float.sum() // 6
let int = SIMD3<Int>(1, 2, 3)
int.wrappedSum() // 6
FixedWidthInteger(整数)の場合の演算
let a = SIMD3<UInt8>(x: 1, y: 2, z: 3)
let b = SIMD3<UInt8>(x: 1, y: 2, z: 3)
// オーバーフロー加算
a &+ b // SIMD3<UInt8>(2, 4, 6)
Scalarが整数の場合、SIMDはオーバーフロー演算子しか対応していません。(オーバーフロー演算子自体は普通のFixedWidthIntegerに存在する演算子です)
オーバーフロー演算子は、整数がオーバーフローした場合でもエラーにならず、桁上がりして.minに戻ります。
let a = SIMD3<UInt8>(x: 253, y: 254, z: 255)
let b = SIMD3<UInt8>(x: 1, y: 1, z: 1)
a &+ b // SIMD3<UInt8>(254, 255, 0)
一方をスカラにするとスカラを全要素に展開して演算します。(他の演算子でも同様)
let a = SIMD3<UInt8>(x: 1, y: 2, z: 3)
a &+ 1 // SIMD3<UInt8>(2, 3, 4)
// 同じ意味
a &+ .init(repeating: 1) // SIMD3<UInt8>(2, 3, 4)
mutatingな代入演算子&+=にも対応しています。(他の演算子でも同様)
var a = SIMD3<UInt8>(x: 1, y: 2, z: 3)
a &+= 1
a // SIMD3<UInt8>(2, 3, 4)
let a = SIMD3<UInt8>(x: 1, y: 2, z: 3)
let b = SIMD3<UInt8>(x: 1, y: 2, z: 3)
let c = SIMD3<UInt8>(x: 3, y: 2, z: 1)
let d = SIMD3<UInt8>(x: 1, y: 1, z: 1)
// オーバーフロー減算
a &- b // SIMD3<UInt8>(0, 0, 0)
// オーバーフロー乗算
a &* b // SIMD3<UInt8>(1, 4, 9)
// 除算
a / c // SIMD3<UInt8>(0, 1, 3)
// mod
a % b // SIMD3<UInt8>(1, 0, 0)
// ビットNOT
~a // SIMD3<UInt8>(254, 253, 252)
// ビットAND
a & d // SIMD3<UInt8>(1, 0, 1)
// ビットXOR
a ^ d // SIMD3<UInt8>(0, 3, 2)
// ビットOR
a | d // SIMD3<UInt8>(1, 3, 3)
// ビット左シフト
a &<< c // SIMD3<UInt8>(8, 8, 6)
// ビット右シフト
a &>> c // SIMD3<UInt8>(0, 0, 1)
FloatingPoint(小数点)の場合の演算
let a = SIMD3<Float>(x: 1.0, y: 2.0, z: 3.0)
let b = SIMD3<Float>(x: 1.0, y: 2.0, z: 3.0)
let c = SIMD3<Float>(x: 3.0, y: 2.0, z: 1.0)
// 加算
a + b // SIMD3<Float>(2.0, 4.0, 6.0)
// 減算
a - c // SIMD3<Float>(-2.0, 0.0, 2.0)
// 乗算
a * b // SIMD3<Float>(1.0, 4.0, 9.0)
// 除算
a / c // SIMD3<Float>(0.33333334, 1.0, 3.0)
addProduct, addingProduct Fused Multiply Add (FMA, 融合積和演算)
let a = SIMD3<Float>(x: 1.0, y: 4.0, z: 7.0)
let b = SIMD3<Float>(x: 2.0, y: 5.0, z: 8.0)
let c = SIMD3<Float>(x: 3.0, y: 6.0, z: 9.0)
// a + b * c
a.addingProduct(b, c) // SIMD3<Float>(7.0, 34.0, 79.0)
SIMD用のFMA命令があるのですが、Float自体のFMAをループで呼ぶ形になっていて、SIMDになっていないようです。
formSquareRoot, squareRoot 平方根
let a = SIMD3<Float>(x: 2.0, y: 3.0, z: 4.0)
a.squareRoot() // SIMD3<Float>(1.4142135, 1.7320508, 2.0)
これもFloat自体のsquareRootを読んでいて、SIMDのsquareRootになっていません。
round, rounded
let a = SIMD3<Float>(x: 1.0, y: 1.4, z: 1.8)
a.rounded(.up) // SIMD3<Float>(1.0, 2.0, 2.0)
これもFloat自体のroundを呼んでいて、SIMDのroundになっていません。
比較処理
ベクトル全体の比較です
let a = SIMD3<Float>(x: 1.0, y: 2.0, z: 3.0)
let b = SIMD3<Float>(x: 1.0, y: 2.0, z: 3.0)
a == b // true
a != b // false
let c = SIMD3<Float>(x: 3.0, y: 2.0, z: 1.0)
a == c // false
a != c // true
マスク関連処理
.のprefixをつけると要素毎の比較になり、SIMDMaskが返ります。
==と.==を使い分けられるのもSwiftの演算子オーバーロード機能による恩恵です。
let a = SIMD3<Float>(x: 1.0, y: 2.0, z: 3.0)
let b = SIMD3<Float>(x: 3.0, y: 2.0, z: 1.0)
a .== b // SIMDMask<SIMD3<Int32>>(false, true, false)
a .!= b // SIMDMask<SIMD3<Int32>>(true, false, true)
a .<= b // SIMDMask<SIMD3<Int32>>(true, true, false)
a .< b // SIMDMask<SIMD3<Int32>>(true, false, false)
a .>= b // SIMDMask<SIMD3<Int32>>(false, true, true)
a .> b // SIMDMask<SIMD3<Int32>>(false, false, true)
replace, replaceing (ブレンディング)
let a = SIMD3<Int8>(x: 1, y: -1, z: 3)
let b = SIMD3<Int8>(x: 4, y: 5, z: 6)
// aの負の要素だけbで置き換える
a.replacing(with: b, where: a .< 0) // SIMD3<Int8>(1, 5, 3)
SIMDにはblendと呼ばれる該当命令があるのですが、これもSIMDになっていないようです。
SIMDMask同士の演算
let a = SIMDMask<SIMD3<Int8>>(arrayLiteral: true, false, true)
let b = SIMDMask<SIMD3<Int8>>(arrayLiteral: false, false, true)
// trueなものが一つでもあるか
any(a) // true
// 全てがtrueか
all(a) // false
// NOT
.!a // SIMDMask<SIMD3<Int8>>(false, true, false)
// AND
a .& b // SIMDMask<SIMD3<Int8>>(false, false, true)
// XOR
a .^ b // SIMDMask<SIMD3<Int8>>(true, false, false)
// OR
a .| b // SIMDMask<SIMD3<Int8>>(true, false, true)
Discussion