はじめに
この記事は、「KNOWLEDGE WORK Blog Sprint」第2日目の記事になります。
ナレッジワークのソフトウェアエンジニアの 38tter です。
今回は Go のプロファイルに基づく最適化(PGO)についてご紹介し、Go のアプリケーションのパフォーマンス改善のためにどのように応用できるかを検討します。
Go のコンパイラ最適化技術が、実際にサービス運用の中でどのように導入できるかを知りたい方に役立つ内容となることを目指しています。
プロファイルとは
プロファイルに基づく最適化(Profile-guided optimization, PGO) は、Go 1.21 で正式に導入されたコンパイラを最適化する技術です。ここではプロファイルについてご説明します。
そもそも Go でのコンパイラの最適化とはどのような技術があるのでしょうか。以下に主な最適化の技術を列挙してみます。
- インライン展開
- エスケープ解析
- ゼロサイズ最適化
- ゼロクリア最適化
- キャスト最適化
例えばインライン展開は関数の実装を呼び出し元に展開することで、関数呼び出しのオーバーヘッドを削減します。こうした最適化はそれぞれ実行時間の短縮などに寄与する効果があるものの、愚直にすべてを適用するとかえって最終的な性能は落ちてしまいます。
Go コンパイラは最適化を実行する際にコードを静的解析し、経験則に基づいて最適化を行っています。
例えばインライン展開の場合は関数の複雑さをスコア化し、そのスコアがある値を下回っている場合にインライン展開する、というように適用されます。
ここで、実際のアプリケーションで頻繁に実行されるコードをコンパイラが知ることができたら、より効果的な最適化ができると考えられないでしょうか。プロファイルはコンパイラにその情報を伝えるための統計情報です。PGO はプロファイルに基づいてコンパイラが最適化を行うことを指します。
Go では ビルド時にメインパッケージと同じディレクトリに CPU プロファイルを置くことで自動的に PGO が有効になります。
気になる点
上でご紹介したコンパイラ最適化の手法は、アプリケーションのパフォーマンス向上の観点では、特に留保せずに有効にするべきように思われます。特に CPU がボトルネックになる複雑な計算処理(CPU バウンドな処理)には効果を発揮しそうです。
一方で、日頃開発で携わる SaaS 等の Web サービスのバックエンド開発は単純化すると RDB への CRUD 処理が多く、データの入出力がボトルネックになる処理(I/O バウンドな処理)が多いと考えられます。
そういった状況でコンパイラ最適化がどこまで有効なのか、アプリケーションの処理内容の特性(CPU バウンドな処理が多いか、I/O バウンドな処理が多いか)によっては、思うような効果が得られないこともありそうです。
プロファイリングの効果検証
それでは実際の Go アプリケーションで、PGO がどの程度パフォーマンスに寄与するかを調べてみましょう。
検証の流れは以下の通りです。
- プロファイルを使わずに Go アプリケーションを起動する
- アプリケーションに対して負荷計測を行い、プロファイルを収集する
- プロファイルを使って Go アプリケーションを起動する
- 再び負荷計測を行う
- 1 と 4 で CPU 使用率、リクエスト処理時間を比較する
検証環境の詳細
今回は Google Cloud 環境で、Go アプリケーションのプロファイルを取得し、外部からのリクエストをエミュレートし、ビルド時のプロファイルの有無がアプリケーションのメトリクスにどの程度影響があるかを検証してみたいと思います。
今回の検証では、CPU バウンドな処理に対する PGO の効果と、I/O バウンドな処理に対する PGO の効果を分けて測定します。
そこで、アプリケーションの処理内容を CPU バウンドな処理と I/O バウンドな処理に分け、それぞれを別のエンドポイントとして公開しました。
アプリケーション
まず、Google Cloud のサーバーレス実行環境である Cloud Run で Go アプリケーションを起動します。以下の 2 種類のエンドポイントを公開しました。
/prime
CPU バウンドな処理として素数判定のアルゴリズムを実行します。以下はリクエストのハンドラの詳細です。
func isPrime(n int) bool {
if n < 2 {
return false
}
sqrtN := int(math.Sqrt(float64(n)))
for i := 2; i <= sqrtN; i++ {
if n%i == 0 {
return false
}
}
return true
}
func primeHandler(w http.ResponseWriter, r *http.Request) {
const limit = 10_000_0
count := 0
for i := 2; i < limit; i++ {
if isPrime(i) {
count++
}
}
fmt.Println("Prime count:", count)
}
/file
I/O バウンドな処理として外部ストレージからのファイルの読み込みを行います。
func fileHandler(w http.ResponseWriter, r *http.Request) {
ctx := context.Background()
start := time.Now()
rc, err := storageClient.Bucket(bucketName).Object(objectName).NewReader(ctx)
if err != nil {
http.Error(w, fmt.Sprintf("Failed to open object: %v", err), http.StatusInternalServerError)
return
}
defer rc.Close()
// ファイル内容を全部読み込む
data, err := io.ReadAll(rc)
if err != nil {
http.Error(w, fmt.Sprintf("Failed to read object: %v", err), http.StatusInternalServerError)
return
}
elapsed := time.Since(start)
w.Header().Set("Content-Type", "text/plain")
fmt.Fprintf(w, "Read %d bytes from GCS in %s\n", len(data), elapsed)
}
Cloud Run の主な設定は以下の通りです。
オートスケーリングによる CPU 負荷分散の影響を避けるため、最大インスタンス数は 1 で固定しました。
| vCPU 数 | メモリ | 最大インスタンス数 | 最小インスタンス数 |
|---|---|---|---|
| 1 | 2GiB | 1 | 0 |
負荷計測
負荷ツールとしては k6 を採用しました。
余談ですが、k6 で負荷計測のワークロードを構成するメリットとして、RPS (Request-per second) ベースで外部からのトラフィックをエミュレートできます。
実際のサービス運用では SLO/SLA といったスループット目標から逆算して何 RPS を捌けるサービスが必要となるか?という発想が多いと思われるため、こうした点をメリットと感じて採用しました。
設定は以下の通りです。ファイル読み込みは 429 too many requests エラーを避けるため、RPS を少なめにしています。また、Executor は平均負荷テストとして一般的な設定としました。
| エンドポイント | RPS | 実行時間(分) | Executor |
|---|---|---|---|
| /prime | 100 | 1 | 'constant-arrival-rate' |
| /file | 5 | 1 | 'constant-arrival-rate' |
$ k6 run script.js
/\ Grafana /‾‾/
/\ / \ |\ __ / /
/ \/ \ | |/ / / ‾‾\
/ \ | ( | (‾) |
/ __________ \ |_|\_\ \_____/
execution: local
script: script.js
output: -
scenarios: (100.00%) 1 scenario, 50 max VUs, 1m30s max duration (incl. graceful stop):
* constant_request_rate: 30.00 iterations/s for 1m0s (maxVUs: 20-50, gracefulStop: 30s)
running (0m15.7s), 07/20 VUs, 464 complete and 0 interrupted iterations
constant_request_rate [========>-----------------------------] 07/20 VUs 0m15.7s/1m0s 30.00 iters/s
プロファイル収集
Google Cloud の Cloud Profiler は本番環境でのアプリケーション実行を元にしたプロファイルを実行可能です。
プロファイルの収集はアプリケーションから Profiler API によりプロファイルデータをキャプチャして送信することで行われます。
プロファイリングとしては、Go では CPU 時間やヒープ割り当てを収集することができるようです。
これまた余談ですが、Cloud Profiler のドキュメントでは公式にサポートされている構成の中に Cloud Run は見当たりませんが、特に問題なくアプリケーションに組み込むことができました。
下記の通り、コードベース上はアプリケーション起動時に数行の設定を追加するだけでプロファイル収集を行うことができるため、実運用にも組み込みやすそうです。
import (
// ...
"cloud.google.com/go/profiler"
// ...
)
func init() {
// プロファイラの設定
cfg := profiler.Config{
Service: "pgo-test",
ServiceVersion: "1.0.0",
}
if err := profiler.Start(cfg); err != nil {
panic(err)
}
// 中略
// ハンドラ
mux := http.NewServeMux()
mux.HandleFunc("/prime", primeHandler)
mux.HandleFunc("/file", fileHandler)
functions.HTTP("FuncMux", mux.ServeHTTP)
}
Cloud Profiler を使う注意点として、プロファイリングデータの収集は 1 分間ごとに 10 秒間行われると記述されています。
検証
/prime
まず、/prime の負荷計測で取得したプロファイルを可視化してみます。Cloud Profiler では取得したプロファイル項目(CPU 時間、ヒープ、スレッド等)それぞれを可視化することができます。今回は CPU 時間を確認してみましょう。
以下は、CPU 時間のプロファイルを可視化したフレームグラフと呼ばれるグラフです。大まかな見方として、横軸が各関数が占める CPU 時間で、関数内で呼び出された別の関数の CPU 時間が順に下に表示されています。
フレームグラフの読み方の詳細についてはこちらをご参照ください。
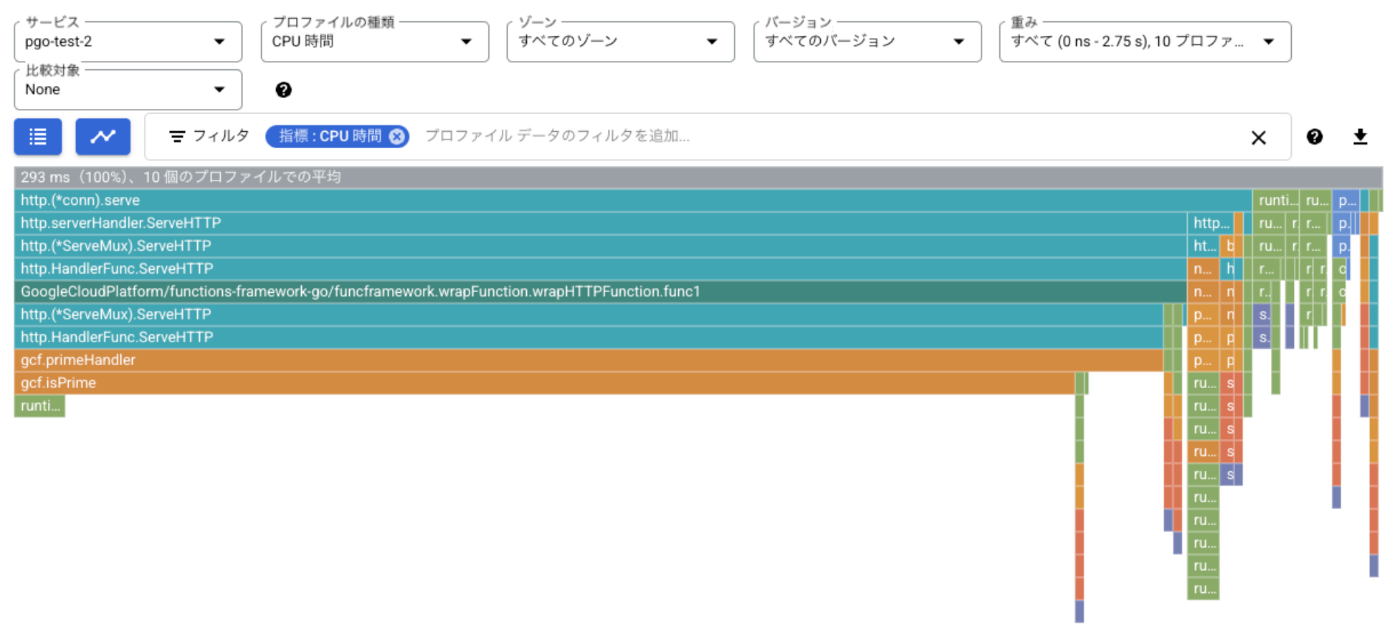
素数判定の処理のハンドラに対応するのが gcf.primeHandler で、サーバーの CPU 時間の大きな割合を占めていることがわかります。見たところ、こういった処理には PGO によるコンパイラ最適化が効いてきそうです。
実際にプロファイラなしの場合とプロファイラありの場合とで CPU 使用率を Cloud Run のメトリクスから抜粋して比較したのが下記の図です。

ピークの CPU 使用率が低下しているのがお分かりになると思います。
また、k6 による測定結果からリクエスト処理時間の比較は下記の表です。
| プロファイラの有無 | 平均値(ms) | 中央値(ms) |
|---|---|---|
| なし | 537.4 | 568.3 |
| あり | 488.5 | 515.7 |
平均値で 9.1%、中央値で 9.2% 程度の改善が見られました。平均値と中央値が同程度に改善していることから、各リクエストで平均的にパフォーマンス改善の効果が見られるようです。
/file
続いて、/file への負荷計測で取得したプロファイルを見てみましょう。
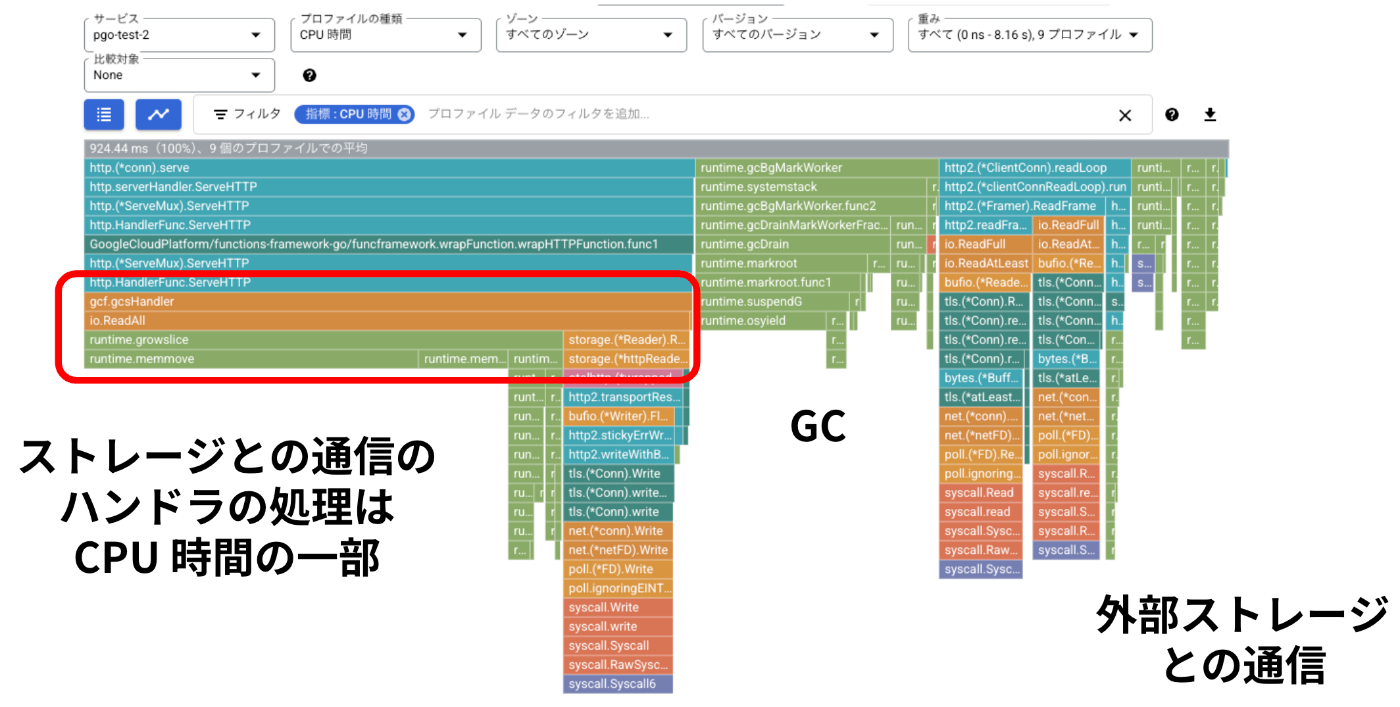
今度は様子が異なり、ハンドラの処理が CPU 時間に占める割合は一部で、GC や 外部ストレージとの通信の処理が多く見られます。
このような場合にプロファイラ指定はどの程度の効果があるでしょうか?

ピークの CPU 使用率はむしろ上昇しているようです。
また、k6 による測定結果からリクエスト処理時間の比較は下記の表です。
| プロファイラの有無 | 平均値(ms) | 中央値(ms) |
|---|---|---|
| なし | 947.9 | 850.9 |
| あり | 1050.0 | 1020.0 |
平均値で 10.8%、中央値で 19.9% 程度悪化しています。平均値と中央値の推移の度合いが異なることから、各リクエストごとに異なる程度に遅延したようです。もちろん外部サービスとの通信の影響もあるため、PGO による影響がどの程度あるかは一概には言えませんが、今回の設定では改善の効果は見られませんでした。
まとめ
Go 1.21 で正式に導入された PGO は、CPU プロファイルにより実際のアプリケーションで頻繁に実行されるコードをコンパイラに伝えることで、より効率的なコンパイラ最適化が期待されます。
また、Google Cloud で検証環境を立てたところ、アプリケーションへの導入は容易にできそうな所感を持ちました。
一方で、PGO の導入がアプリケーションのパフォーマンス向上に寄与するかどうかは、ボトルネックとなる処理に依存する部分が多そうです。
筆者がこれまで経験のある SaaS や EC サイトといったユーザーフェイシングで CRUD 処理がメインとなるサービスでは、期待できる効果は限定的で、むしろそれらと連携するデータ集計処理や、ファイル加工処理といった複雑な計算処理を担うサービスでの導入に適しているといえそうです。
参考
KNOWLEDGE WORK Blog Sprint、明日の執筆者は筆者と同じくバックエンドエンジニアの yuma です。ご期待ください!

Discussion