導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。普段はエンジニアとして、LLMを使用したチャットのサービスを提供しており、とりわけRAGシステムの改善は日々の課題になっています。
本記事では、問題解決を効率的に行うエージェント集団を構成する手法、Captain Agentについて簡単に解説していきます。

サマリー
このCaptain Agentの特徴は、任意の問題に対してエージェントを用いて問題を解いた後に、その結果に対してフィードバックを行い、問題を解くためのエージェントを再構成する点にあります。
問題ごとに必要なエージェントを自動的に構成することから、特定のタスクに合わせて事前にエージェントを作成する必要がありません。さらに、動的にエージェントを作成することで問題に対してより柔軟な対応が可能となっています。
より詳細な内容は、以下の論文がもととなっていますので、そちらを参照してください。
問題意識
エージェントの制約
そもそもエージェントとは、LLMが任意の操作や外部の情報を取得するためのツールを利用できるようにするためのフレームワークです。単体のエージェントであっても、Webを介した検索やメールの送信など調整次第で様々な操作を実現できます。一方で、複雑なタスクに対する精度の面で問題がありました。
複数エージェント利用の設計の問題
エージェントの精度面の問題を克服するために、目的を絞ったエージェントを複数作成しタスクに合わせてそれらを組み合わせる手法が有望視されています。しかし、それらをどのように設計するかについては依然としてスタンダードな方法は確立されていません。
この問題に対して、Captain Agentはいかに効果的なエージェント群を構築するかという点に着目し問題解決を目指しました。結果的にこの手法はこれまでに提案された複数エージェントを使用する手法と比べて高い問題解決能力を発揮することができました。
手法
Captain Agentは、以下のフローを経て結果を出力します。
- 与えられたタスクに対して、タスクを解決するまでの手順を考える
- 解決までの手順をサブタスクに分解する
- サブタスクを解決するのに必要なマルチエージェントチームを作成する
- エージェントチームがサブタスクを解く
- サブタスクが完了したのち、そのプロセスをレビューし振り返りを出力する
- フィードバックに基づきサブタスクやエージェントチームを調整して4からやり直すか、タスクを終了して最終結果を出力する。
各方法のより詳しい内容は以下を参照してください
より詳細な手法の説明
マルチエージェントチーム構築
Captain Agentは与えられたタスクをサブタスクに分割し、必要な役割を割り出します。エージェントとツールを、それらの構成を保管しているライブラリから取得し、適切なエージェントのチームを構成します。このとき、必要な役割を果たせるエージェントが存在しない場合は、ツールを元に新たに構築しそれを利用します。
サブタスクの解決
エージェントチームは会話とそれぞれのツールを用いてサブタスクを解決します。サブタスクが完了したら、反省用のLLMが会話の履歴をレビューして、Captain Agentに対して、反省レポートを提供します。このレポートに基づき、Captain Agentはチームの再構成、サブタスクの追加の指示、もしくはタスクの完了を決定します。
エージェントチームの会話
選ばれたエージェントはサブタスクを解決するために、AutoGenというフレームワークを利用してエージェント同士で会話を行いタスクを解決していきます。詳しい内容はAutoGenの論文を確認してみてください。
反省プロセスの詳細
反省レポートは、エージェントチームの会話と出力された結果を元に、以下の項目を含む反省レポートを作成します。
- 解いたタスクの概要
- タスクを解決した結果
- その結果が導き出された理由
- 会話内の問題
- 再検証の必要性の有無
- その他の追加の情報
この反省のプロセスでは主に、会話の内容や結果の矛盾を検出することに焦点を当てています。更に再確認が必要かどうかも判断を行い、再度エージェントチームを作り出す必要があるかをフィードバックします。
成果
論文内では、まず既存の複数エージェントを使用したタスク解決手法との精度面の比が行われています。比較は6個の項目で行われています。

ここで提示されている比較項目については、すべての項目について3~5%程度の精度の改善が見られているようです。
さらに、世界情報検索シナリオという、情報を効率的に検索して必要なデータや情報を迅速に集めるというタスクに対しては以下のような結果となりました。

こちらについても、比較している手法の中では最も優れた結果を出しており、なおかつプロンプトエンジニアリングを最小に抑えられたことに触れられています。
次に、動的にエージェントのチームを再構成する手法が有用かを検証するために固定のエージェントのチームと動的に生成する場合とで精度の比較を行っています。

物理のタスクを除いて、ほぼすべてのタスクについて性能が向上していることを示しており、動的にエージェントのチームを生成することの有用性を示しています。
最後に、使用するエージェントやツールを事前に定義しておきそれらを読み込めるようにすることによる性能の改善について比較を行っています。
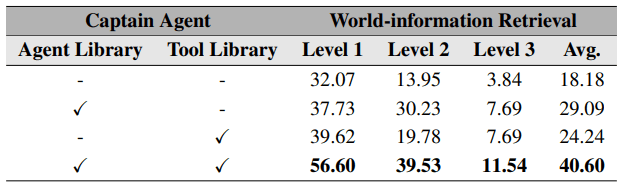
世界情報検索シナリオにおいては、事前にある程度エージェントやツールの定義をつくっておくことでかなりの精度を改善していることがわかります。
考察
今回紹介した論文では現実世界で想定されるタスクに対して、LLMを使用して効率的に問題解決する新しい手法について紹介されていました。比較に用いられたタスクの多くはLLMの単純な実行では解決が難しくタスクの分解を必要としています。そのタスクに対して従来の手法以上の成果をあげていることから、この手法の性能の高さを伺うことができるかと思います。
また、固定のエージェントチームと動的に変化するエージェントチームとの性能比較で、性能が向上していることからこの手法特有の動的にエージェントチームを生成することの有用性が示せているのもポイントかと思います。
一方で、成果の中の最後に示した表から、事前に定義されたエージェントやツールの存在が精度の向上に必要なことが示されています。このため、他の手法と比較した成果については、必ずしもその手法による精度の差ではなく事前に用意されたプロンプトの性能の差であることも考えられるので、その点は注意が必要そうです。
加えて実行時間についても、論文内ではその点については触れられていませんが、チームの構成を考えるという操作が入ることにより大幅に伸びていることが想定されます。
以上の二点については、実際に利用していくうえでは事前に検証しておく必要がありそうです。
まとめ
LLMが一般に大きく普及して以来、ツールを使用するエージェントについて様々な研究が行われ、更に精度を改善するためにそのエージェントを複数動かすという研究が行われるようになりました。その最新の研究の一つが今回紹介したCaptain Agentという手法になります。
この論文で特筆すべきは、動的なエージェントの再構成が精度面に寄与しているという点ではないでしょうか。これはつまり、問題に対して必要な解決手段を認識して適切に選び取ることがLLMには可能であることを示しており、より複雑なタスクに対しても対応できる可能性を示唆しているように思います。
複雑な問題をLLMを使用して解決したい際には、是非参考にしてみてください。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略などについて知見を共有していきます。
Discussion