導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。
今回は、RAGで数値情報を正しく認識できるのかを調査した論文を紹介します。

サマリー
RAGはユーザーの質問に対して、意味的な類似度から関連性の高い情報を検索して、ユーザーの質問に回答します。この意味的な類似度の検索がRAGの技術を支えていますが、その性能に関しては様々なベンチマークが乱立しており、体系的に把握されていないことも多く存在します。
今回は、数値にフォーカスして、RAGが正確に数値を把握できているかの調査結果とその分析をしていきます。
課題意識
類似度検索の限界
意味的な類似度による検索は、一見万能に見えますが苦手もあります。一般的には、固有名詞、特に社内用語などの一般には知られていない単語や言葉の使い方が登場すると、類似度検索の性能は大きく下がります。これは、学習の段階で登場しない単語の類似度を判定できないためです。そして、数値も数字の大きさ自体に意味的な情報が含まれないため、認識が困難だと考えられています。
手法
論文内での実験内容とその結果についてまとめていきます。
テスト方法はまず以下のような3種類の文章を用意します。
- Q: 数値的な条件を含む質問文
- A+: 質問の数値条件を満たす回答文
- A-: 質問の条件を満たさない回答文
この三種類の文章をEmbeddingモデルを利用して、ベクトルに変換しQとA+, A-のそれぞれの類似度を計算。A+の方が高い類似度を示した割合を「正解率」として扱います。
例
Q: この試合で3点以上の得点を獲得したのは誰ですか?
A+: 山田さんはこの試合で5点獲得しました。
A-: 山田さんはこの試合で2点獲得しました。
結果
数値の種類ごとの性能
質問と回答に使用する数値の種類ごとの実験結果です。
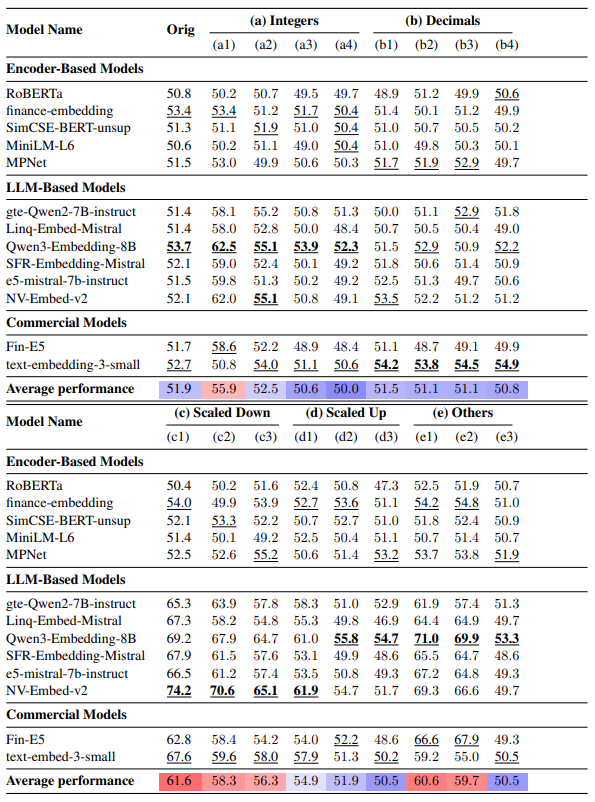
- 全体的な性能
複数の実験の結果、正答率の平均は54%でした。そもそも二択なのでランダムに選択したとしても50%は正解できるので、ランダムよりもわずかに正答率が高いという結果になりました。
- 数値の大きさによる性能差
数値そのものの大きさによって性能に差が生まれます。0.7といった1以下の小数は平均正答率が61%だったのに対して、1234といった4桁の数値は平均正答率が50%とランダムと変わらない結果となりました。
比較方法ごとの性能
質問文の条件に「より大きい」と「より小さい」を含めた際の実験結果です。

ほとんどのモデルで「より大きい」のほうが「より小さい」という質問文と比較して、高い正答率になっており、最大で30%近い開きになっています。
「24」と「にじゅうよん」の性能
数字を「24」のようなアラビア数字で表記した場合と「にじゅうよん」のように文字表記にした際の実験結果です。(ただし、比較に用いられているのは英語なので、日本語の場合と結果は一致しない可能性があります。)
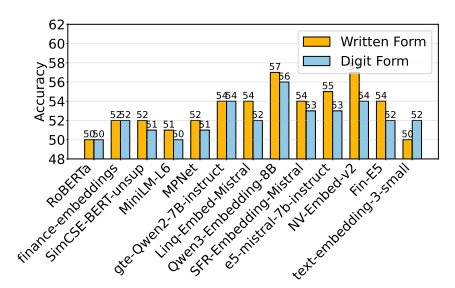
わずかではありますが、文字にしたほうが性能が向上しています。
まとめ
今回は、数値的な条件をRAGが認識できるかを実験した論文を紹介しました。結論としては、2択をほとんど当てられていないという点から、数値的な条件を判断するのは難しそうという事がわかりました。実際のRAGの中では数万チャンクから適切な情報を検索する必要があるため、このような数値的な条件の認識精度の低さは大きな課題となり得ます。
もし数字を正確に比較する必要がなければ、この問題を気にする必要はないですが、比較する必要がある場合は、数字部分だけを切り出して、数値比較でフィルタをかける機能を用意するなどのベクトルデータ以外の手段を用意する必要があるかと思います。
これからRAGを導入しようとしている場合は、どんな目的で利用するかをあらかじめ分解して、数値的な比較が必要なケースかどうかを判断することをおすすめいたします。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion