導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。普段はエンジニアとして、LLMを使用したチャットのサービスを提供しており、とりわけRAGシステムの改善は日々の課題になっています。
本記事では、LLMを使用したレコメンドエンジン作成のフレームワークについて、簡潔に解説していきます。
サマリー
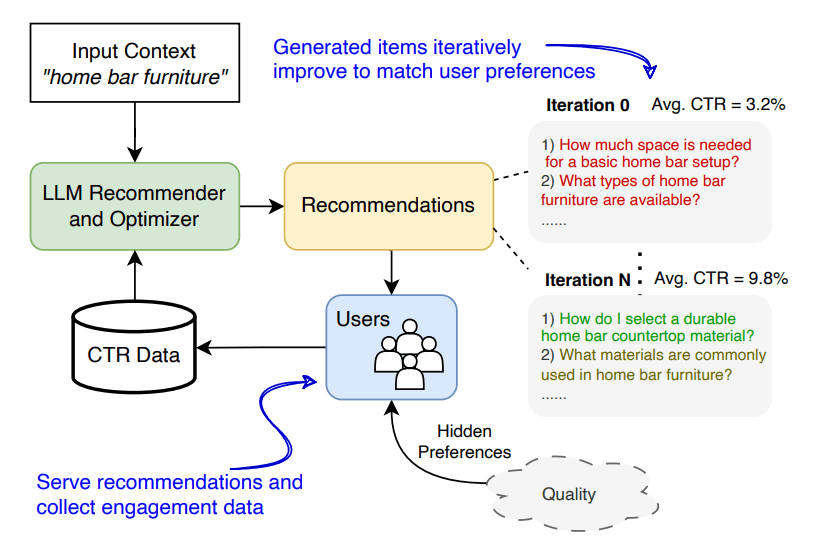
LLMを使用したレコメンドエンジン作成のフレームワーク(以降、「提案されたレコメンドエンジン」)は、Amazonの研究チームによって発表された論文で提唱されました。
このレコメンドエンジンの特徴は、ファインチューニングを利用していないLLMとユーザーの行動(商品のクリックなど)情報を元に、レコメンドの性能を継続的に改善できる点です。ユーザーの行動をもとに、LLMにより関連性の高い商品を推測させることでレコメンドの性能を上げています。
より詳細な解説は以下の記事、もしくは論文を参照してください。
問題意識
従来のレコメンドエンジンの制約
従来のレコメンドエンジンは、定められた数の商品[1]についてユーザーの行動をベースにおすすめする商品を出力します。この性質により、商品の数が増えたり基準とするユーザーの行動を増やすたびに再学習する必要性がありました。
これに対して、生成型のレコメンドエンジン(本記事で紹介するレコメンドエンジンもこれに該当します)は、前提となる知識の豊富さと柔軟性から商品の種類などの制約を受けることなく商品の提案が可能となっています。
従来の生成型のレコメンドエンジンの制約
レコメンドエンジンは、ユーザーの行動を元により適切な出力になるように改善する必要があります。しかし、LLMは基本的にはステートレスで新しい情報を付加するには膨大なコンテキストかファインチューニングが必要となります。しかし、いずれについてもそれを実現するには膨大なコストがかかることになります。
この問題に対して、提案されたレコメンドエンジンではコンテキストとして質問文とユーザーの行動(CTR: Click Through Rateなど)を表す数値を合成しLLMに入力する手法を採用しました。これにより、ファインチューニングや長大なコンテキストによるコストをかけることなく動作するフレームワークの作成に成功しています。
手法
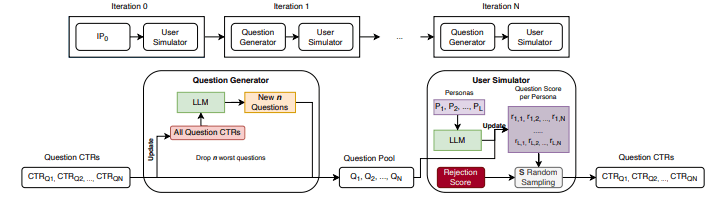
提案されたレコメンドエンジンは、レコメンド対象のアイテムに対する質問と当該のアイテムが選択された確率をLLMにわたすことで、より適切な質問を生成するというフローを繰り返していきます。
少し話がそれますが、質問とクリック率という部分で混乱が起きるかもしれませんが、その点についてはあとの「解説」で、一部筆者の解釈を含めて説明しますのでそちらを確認してください。
事前の準備
- レコメンドの対象となる人物のペルソナをL種類用意する
- レコメンドのグループとなるトピックをM種類用意する
- トピックとペルソナごとに、トピック内でそのペルソナに対してより関連性の高いアイテムを検索できるであろう質問をN個ずつ作成する
継続的な改善
論文内では、実際のユーザーの記録を利用するのではなく、シミュレートされたクリック率というものを採用しています。この値は、LLMを使用して算出されますが具体的な方法は「ユーザー行動のシミュレート方法」を参照してください
以下が改善のフローです。
- 生成した質問をベースに取得されたアイテムのクリック率を集計する
- クリック率の低い質問をn個削除し、LLMに新たにn個の質問を作成してもらう
- 生成した質問を更新し、再度1に戻る
以上の方法でレコメンドに使用する質問を改善していきます。
ユーザー行動のシミュレート方法
レコメンドは、ユーザー個別にではなくペルソナという事前に用意されたユーザーグループを対象に行われます。このため、同じペルソナに含まれるユーザーには同じレコメンド結果となることを前提としています。
そして、シミュレート内では生成された質問とペルソナの説明をLLMに渡し、その関連性を1~10で評価してもらいます。その評価を元に定数で設定されたクリック分布を利用し、ランダムサンプリングで当該の質問がクリックされた確率を算出しています。
成果
論文内では、実験の比較を従来手法ではなく基準となる性能を自身で定義して、それと結果の比較を行っています。このためここでの成果は他手法との良し悪しを比較する事はできません。
以下の項目ごとに比較を行っています。
- NO-DROP: 質問の削除を行わずにイテレーションごとに質問を少しずつ追加していく方針
- PARTIAL-CTR: CTRベースで質問を除外する一方で新しい質問の生成時にCTRをLLMに情報として渡さない方針
- EXPLORE-EXPLOIT: 本命の手法。CTRベースでの質問の除外に加えてCTR情報を付加したプロンプトによる新規質問の作成を行う方針
- RANDOM-CTR: 除外する質問をランダムに選択し、CTR情報を付加したプロンプトにより新規質問の作成を行う方針
- FULL-CTR: 前回生成した質問とそのCTRスコアを元に新しい質問を作成させる方針
以下の図は、縦軸を性能のスコア、横軸をイテレーションの回数と設定したうえでそれぞれの手法ごとの比較を行ったものになっています。
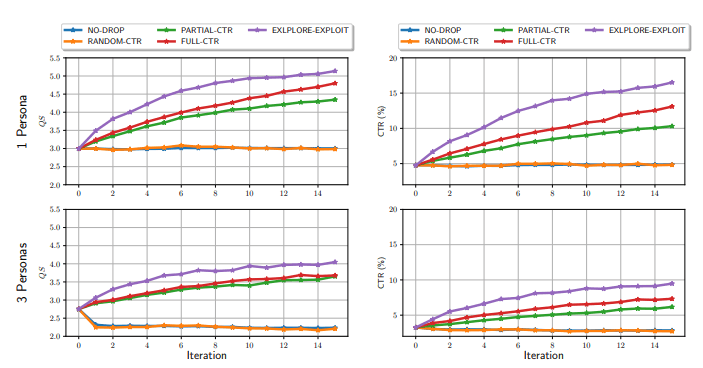
PARTIAL-CTR, EXPLORE-EXPLOIT, FULL-CTRは平均的に性能が改善しており、とりわけEXPLORE-EXPLOITという手法は、改善が進みやすいことが見て伺えます。
解説
ここまで論文に沿う形でかなり簡潔に内容をまとめました。しかし、内容だけを見てみるといわゆるレコメンドエンジンで想定されるような、個人と商品(アイテム)の推薦度を算出するようなモデルとは乖離のあるシステムのように見えます。特に疑問点がなければ、この「解説」は飛ばしてしまっても問題ありません。
ここではいくつかの観点で、補足の説明をしたいと思います。また説明を簡単にするために、レコメンドの対象を商品に限定します。
"質問"とはなにか?
論文内でレコメンドエンジンの最終的な生成目標は質問の作成となっています。本来であれば、商品を対象としそうなところです。どういった質問が生成されるのでしょうか?
実際に生成される質問は以下のようなものになります。
ペルソナ: Ethical Considerations
トピック: Spray Bottles
質問:
How do I identify the recycling code on a spray bottle?
Are there eco-friendly biodegradable options for spray bottles?
質問の内容はそのペルソナがそのトピックに関する情報を取得する際に、どういった質問をするか?という観点で生成されます。なので実際にレコメンドエンジンとして採用するには、この質問を元に更に商品を検索するシステムが必要になります。
提案されたレコメンドエンジンはあくまで、検索の際の観点を正確に補正するところに焦点を当てているということを理解するとわかりやすくなります。
"ペルソナ"とはなにか?
ペルソナとはユーザーの性質を抽象化、ないしはグループ化したものを指します。論文内では、質問の最適化の対象をこのペルソナを対象として行います。本来は個別のユーザーごとに最適化したいはずですが、そのギャップはどのように埋めるのでしょうか?
論文内では、この点については将来的な課題としており、実際に利用するには個別のユーザーをペルソナに結びつけるための実装が必要になります。
考察
まず大前提として、比較している対象は論文内で提案された方法なので、他の論文の手法と比較されていない点に留意する必要があります。
「解説」で述べた通り提案されたレコメンドエンジンは、質問の生成を目標としたフローを利用しています。そして、ユーザーのシミュレート内のLLMでは、その質問とペルソナの類似性を算出します。更にその結果をLLM渡し再度質問を生成します。
論文内の言葉をそのまま借りるのであれば、クリックレートの低い質問を排除し、クリックレートの高い質問を参考に新しい質問を生成するとしています。しかし、実際のフローを考えてみると関連性の低いと思われる質問をLLMに分類させて、関連性の高いとLLMが判定した質問を元に新しい質問をLLMに生成させています。
つまるところこの論文では、ペルソナとトピックを元に最適な質問を生成するのに適切なフローはなにか?という問いに対して、関連性の薄い質問を削除して関連性の高いと判断された質問を生成させる方法が良い。と結論付けていることになるといえるかと思います。なのでこのフローだけをもって性能の高いレコメンドエンジンを実現しているかどうかの判断はできないと言えます。
では今度は生成された質問を定性的に判断してみます。
以下にいくつか具体的な生成された質問を示します。
最初に生成された質問の例(トピックはSpray Bottlesで、ペルソナはEthical Considerationsとします。)
- What are spray bottles typically used for?
- How do spray bottles work?
- What materials are spray bottles made from?
- Are spray bottles recyclable?
- Can spray bottles be reused?
15回のイテレーション後の結果
- How do I identify the recycling code on a spray bottle?
- How do I decode the recycling symbols on my spray
bottle? - What are the steps for disassembling a spray bottle
before recycling? - Are there eco-friendly biodegradable options for
spray bottles? - What items should be removed before recycling a
spray bottle?
質問は確かにペルソナに沿った質問になっているように見えます。そのおかげで、開発者にとってはレコメンドエンジンの改善の様子がわかりやすい点で非常に大きなプラスかと思います。その一方で以下の2つの問題を抱えているように思えます。
- 結局、質問を元に正しく検索できる仕組みを精度高く作らなければならない
- それらしい質問だが、ユーザーが潜在的に欲している要求かはわからない
実際のレコメンドエンジンとして使用するにはこれらの問題が解消されている必要性があるかと思います。
まとめ
今回紹介した手法は非常に抽象的なレイヤでのレコメンドエンジンとなっているため、実際に利用するためには他にも解決しないと行けない問題が非常に多いかと思います。
その一方で学習無しでレコメンドを行うための基礎的な手法の提案としては、非常に面白い検証かと思います。また一見して生成されている質問自体はかなり良いもののように見えるので、質問からアイテムを検索する部分の精度さえ良ければかなり実用に近づくのではないかと思います。
学習無しでレコメンドエンジンを実装したいと思った場合には、是非参考にしてみてください。
-
論文内ではより汎用的にアイテムと表現されていますが、ここではわかりやすく商品という呼び方をしています。 ↩︎
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion