導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。
今回は、RAGの文書の検索精度を既存のシステムに付け加える形で、精度を引き上げることのできるRRA(Rational Retrieval Acts)について紹介します。
サマリー
RAGの検索は、Embeddingを用いた検索と登場する単語の重要度を用いた検索(以降「疎なベクトル検索」)の両方を用いることがあります。後者の疎なベクトル検索は未知の語彙や、検索対象のドキュメントに依存する検索で効果を発揮する手法です。
RRAは既存の疎なベクトル検索の後処理として動作するシステムで、ベクトルの重みづけを文書全体の情報を元に調整することで精度を上げる手法となっています。RRAは非常に汎用的な手法なため、あらゆる疎なベクトル検索の後処理として付け加えることでき、さらに検索精度を上げることに成功しています。
従来の疎なベクトル検索とその課題
既存の疎なベクトル検索の手法
疎なベクトル検索はキーワードベースの検索で有効ですが、いくつかの代表的な手法にも課題がありました。
- BM25 *
BM25は登場する単語の頻度を用いて、文書ごとの重要度を計算する仕組みです。基本的には単語の意味を意識することはないため、精度が上がりづらい問題があります。
- Splade *
SpladeはTransformerモデルを用いて疎なベクトルを生成する手法で、単語の意味を用いた重みづけを行うことが可能です。ただし、文書間の相対的な関係性を意識していなかったり、意味を把握できない単語には弱いという特徴があります。
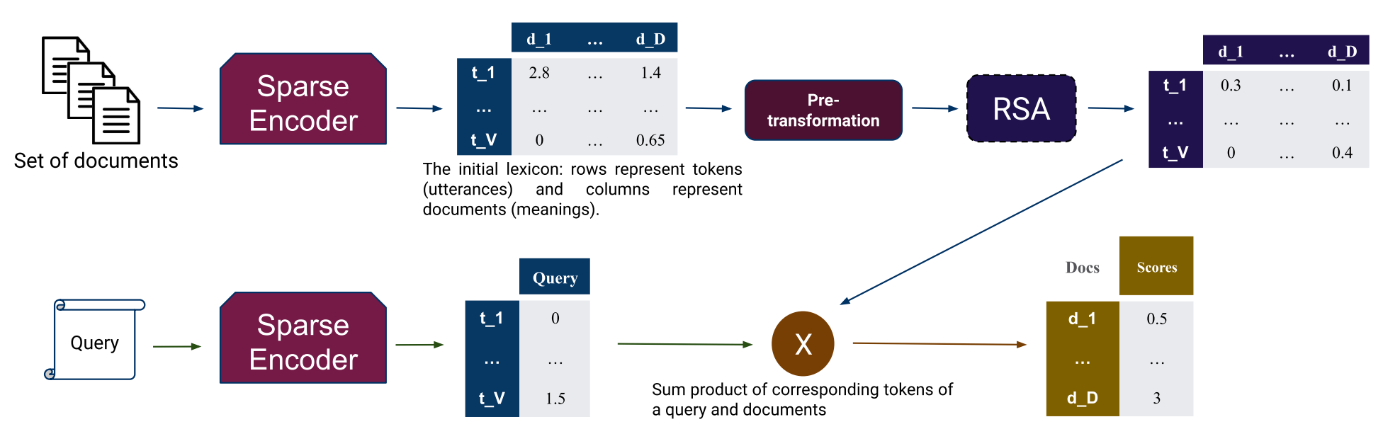
手法
RRAは、既存の疎なベクトルを加工して、新たなベクトルを生成する仕組みです。詳細な計算は元の論文に任せるとして、大まかには以下のような手順で新しいベクトルを生成します。
- 既存の手法(Spladeなど)でドキュメントごとの疎なベクトルを生成します。
このベクトルは、各ドキュメント内でどの単語が重要かを表しています。
- 次に、生成されたベクトルに含まれる各単語の重要度を、ドキュメント全体の情報を考慮して調整します。
具体的には、ドキュメント全体でその単語がどの程度登場するかを計測し、登場頻度の高い単語は重要度を下げて、頻度の低い単語は上げる。という調整を行います。
- 検索の際には、検索クエリも同様にベクトルに変換して類似度の高いドキュメントが選択されます。
成果
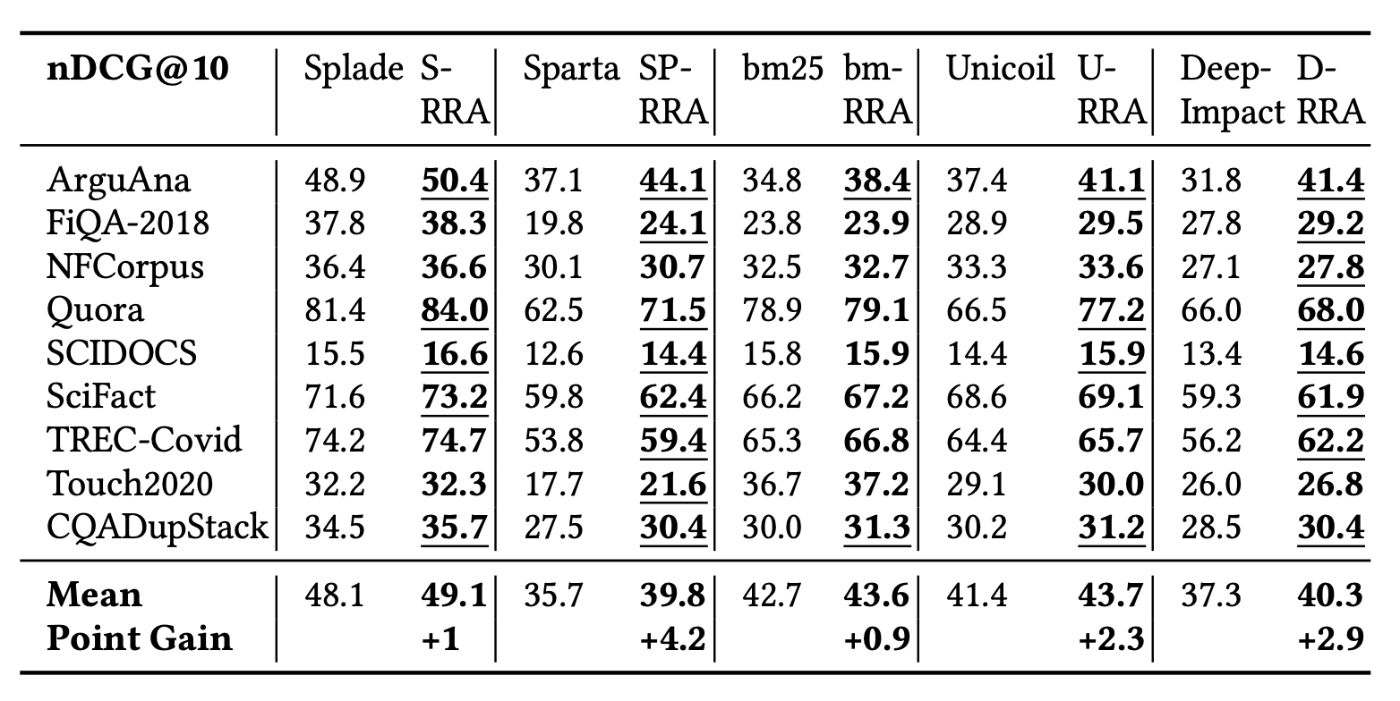
この表は、左側に既存の疎なベクトルを生成する仕組みを用いた場合の精度、右側にはそれぞれのベクトルの生成手法にRRAを付け加えた場合の精度が記載されています。全ての手法で精度が向上していますが、そもそも精度の高いSpladeと方針の似通っているBM25では精度の向上が控えめになっています。
また、個別のデータセットで見るとNFCorpusの検索では精度があまり上がっていません。これは、検索時のクエリが短いためRRAの性能が引き出せないことが原因と考えられます。
まとめ
疎なベクトル検索に付け加える形で、精度を改善できる手法「RRA」について紹介しました。追加で機械学習モデルを導入することなく、精度を引き上げられる手法なためかなり使いやすいです。ただし、実運用で導入する場合考慮しなくてはいけないのは、検索対象が変わるごとに再計算が必要という点です。更新用のパイプラインを用意する、ないしは近似的な手法の導入が必要になってきますが、その点さえクリアできれば実用性の高い手法となりますので、ぜひ最適な場面でご活用いただければと思います。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion