導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。
今回は、方針の決定と検索を繰り返すことで複雑な質問に回答するための枠組み「PAR RAG」について紹介します。
サマリー
Deep Researchを皮切りに、検索と推論を繰り返してこれまでよりも精度の高い検索を実現する機能は普及し始めています。Deep Researchでは検索対象をWeb上のデータとしていますが、検索対象は独自データにすることも可能です。それが今回紹介するPAR RAGです。PAR RAGでは、単純な検索の繰り返しだけではなく、検索結果の評価と検索の計画を組み立てることで更に高い検索精度を実現しています。
エージェントの過剰推論問題
検索を繰り返すことによる問題
LLMが検索を繰り返すことで、より複雑な問題を解決するアプローチにはいくつかの問題があります。特に繰り返しによって発生する問題は、「ずれの蓄積」です。検索を繰り返していく過程でコンテキストが大きくなっていき、本来検索したいことから離れていく問題です。
例えば製造業で、発生した問題の過去の対応方法を調べようとした場合を想定すると、
1回目: 「A1234 停止 原因 報告」
2回目: 「A1234 電圧低下」
3回目: 「電力使用量 ピークシフト」
4回目: 「電力契約 更改 資料 2025」
のように、もともと知りたかった情報からだんだんと離れていってしまう可能性があります。この検索の精度はLLMの性能に依存しますが、構造的に入力が増えていくとこうした問題は発生しやすくなっていきます。
手法
PAR RAGは、「ずれの蓄積」を防ぐことを目的とした手法です。具体的には以下の手順で回答を作成します。
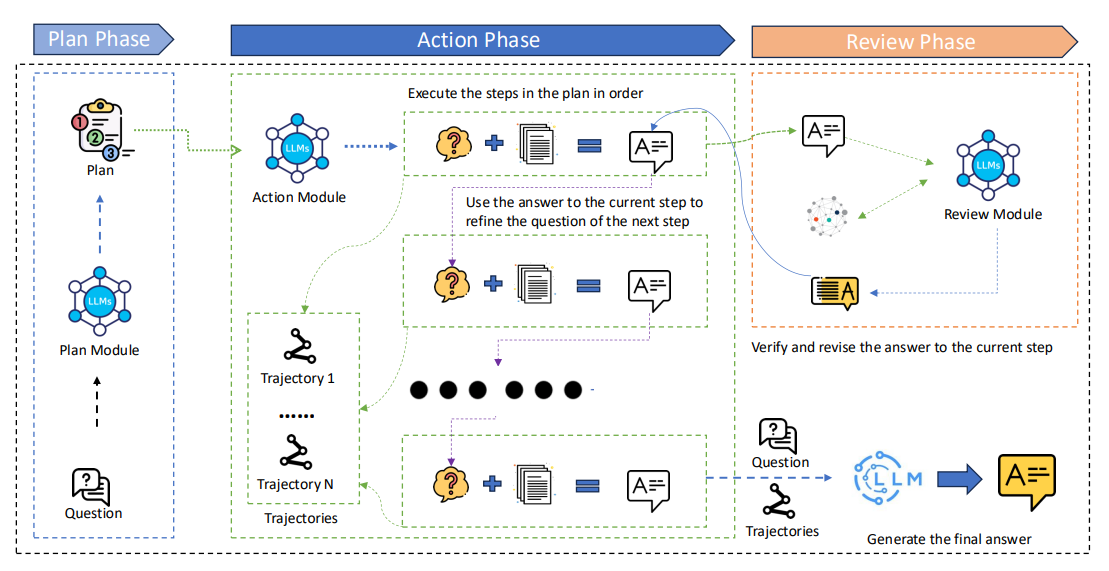
- Plan: ユーザーの入力を元に、全体を見通して、どういった順序で検索と回答生成するべきかの計画を立てます。これにより、調査の方向性が大きくずれることを防ぎます。
- Act & Review: 各ステップを順番に実行します。
a. 現在のステップの質問を元に、まずは大まかに関連する情報を検索します(粗視的検索)。
b. 検索結果を元に、LLMがそのステップに対する中間回答を生成します。
c. 知識グラフを使用して、中間回答の正確性を調査して、修正が必要であれば再度aに戻ります。 - 最終回答: 各ステップでの結果を集約して、LLMが最終的な回答を作成します。
2-cのステップが肝で、一度生成された回答の正確性を調査する過程を挟むことで、「ずれの蓄積」を抑えています。
評価
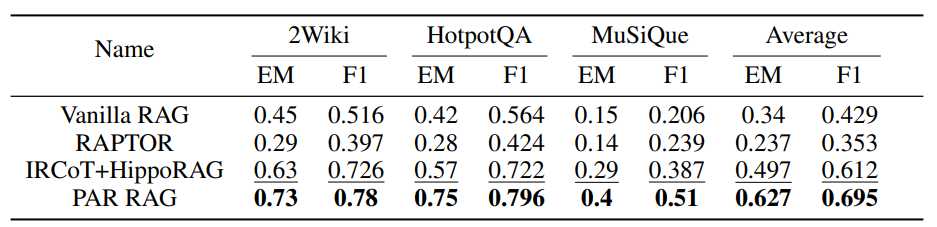
まず他のRAGと繰り返し処理を組み合わせた手法との精度の比較を行っています。CoTとHippoRAGを組み合わせた手法と比較して、F1スコアが0.08ポイントほど上昇しています。

つづいて、PAR RAGの手法と一部の機能を利用しなかった場合の精度比較を行っています。PlanもしくはReviewをなくしてしますと、HotpotQAのタスクにおいてF1スコアが0.12ポイントほどの差が生まれています。

一方で、時間やコスト面では他の手法と比べて劣っており、通常のRAGと比較して、時間にして8倍、コストは13倍となっています。
まとめ
RAGと深い探索、そして「ずれの蓄積」対策を組み合わせたPAR RAGについて紹介しました。深い探索をする分精度は間違いなく向上しますが、その反面時間やコストは大幅に上昇してしまっています。この点はDeep ResearchとLLM+Web検索機能との違いと同じ関係かと思います。
この論文は珍しく、不利になる時間やコスト面での問題点をしっかりと提示してくれているのはありがたい点かなと思います。メリット・デメリットをふまえたうえでぜひ最適な場面でご活用いただければと思います。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion