導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。
今回は、検索結果を効率的にキャッシュすることで、Agentで利用するRAGの速度を高速化することのできる手法「RAGBoost」について紹介します。

サマリー
RAGは検索とLLMを組み合わせることで、チャット形式で情報を検索できる便利な手法です。一方で、検索にかかる時間や、コンテキストの増加によるコストや時間の増加が問題となります。今回紹介する「RAGBoost」は、検索手法の工夫とコンテキストの再利用でRAGの高速化に成功しています。特にAgent内でRAGを利用した際にさらに効果を発揮するなど、活用の幅が広いです。
課題意識
RAGの回答時間
RAGを利用するうえでの大きな課題の一つとして、回答が遅くなる問題があります。これは、長文を入力するとLLMの回答が生成され始めるまでが遅くなるためです。一般的に文章は長いほど回答までの時間は遅くなり、長いコンテキストを入力するRAGはその問題が顕著に現れやすいです。かといって、当然そのまま渡すコンテキストが減れば回答精度も下がるため、簡単にコンテキスト量を減らすことはできません。
手法
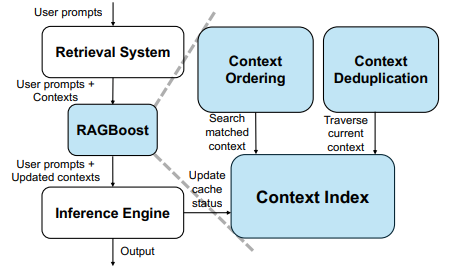
RAGBoostは主に2つの方法で、キャッシュを利用し処理を高速化しています。
1. 過去の検索結果を再利用する

Agentのように繰り返しRAGを利用する場合、検索結果に同じドキュメントが含まれることがよくあります。RAGBoostでは、以前の結果に含まれていたドキュメントは、文章データではなくIDで同じ内容であることをLLMに伝えます。
具体的には以下のようなイメージです。(Docから始まるものが検索結果です)
1ループ目
[システムプロンプト]
-> [Doc 2のチャンク],[Doc 3のチャンク],[Doc 1のチャンク]
-> [ユーザーのクエリ]
-> [LLMからの返答]
2ループ目
[システムプロンプト]
-> [Doc 2のチャンク],[Doc 3のチャンク],[Doc 1のチャンク]
-> [ユーザーのクエリ]
-> [LLMからの返答]
-> [Doc 4のチャンク],[Doc 3のID],[Doc 1のID]
-> [ユーザーのクエリ]
-> [LLMからの返答]
厳密には少し異なりますが、すでに登場したドキュメントであれば、チャンクそのものではなく、前のあのチャンクと同じであることをLLMに伝えるだけになります。
2. LLMのキャッシュを利用する

もう一つ面白い方法がLLMのキャッシュを使用する方法です。LLM側のキャッシュを利用するために、過去の検索結果と可能な限り冒頭が一致するように並び替えたうえで、LLMに検索結果を渡す方法です。
LLMのキャッシュとは?
LLMのキャッシュと聞いて、ピンとこない方もいるかと思いますので、簡単に解説します。通常LLMは文章の頭から連鎖的に文字を解析して、すべて読み込み終えたあとに出力内容を決定します。この性質のため、一部の文章が一致していたとしても結果を再利用できません。
しかし、一つだけ例外があり、それは冒頭から一言一句全て同じ場合です。冒頭から同じ文章であれば、計算結果も一致しているため再利用できます。このため、LLMを提供する各社ではこのキャッシュを利用する場合には、相対的に安い料金でLLMを利用できるように設計されています。(今回の論文では、ローカルのLLMを利用するため、計算資源の削減につながります)

ポイントは、最初から一言一句全て同じ文章、であるという点です。
具体的には以下のようにします。
以前のRAGの利用の結果
[システムプロンプト]
-> [Doc 2のチャンク],[Doc 3のチャンク],[Doc 1のチャンク]
-> [ユーザーのクエリ]
-> [LLMからの返答]
今回
検索の結果 [Doc 4のチャンク],[Doc 2のチャンク],[Doc 3のチャンク]の順序で検索結果が返ってきた。過去の結果と冒頭の順序を一致させるように並び替え、以下のようにLLMに入力します。
[システムプロンプト]
-> [Doc 2のチャンク],[Doc 3のチャンク],[Doc 4のチャンク]
-> [ユーザーのクエリ]
-> [LLMからの返答]
このように冒頭のチャンクを一致させることで、LLMのキャッシュが利くようになり、回答の高速化とコストの低下が見込めます。
評価

各キャッシュ手法の、精度と処理性能(Prefill Throughput)を比較した結果です。細かい説明は省きますが、精度はベースラインと同等以上の精度を維持しつつ、トークンの処理の速さは最も早くなっています。
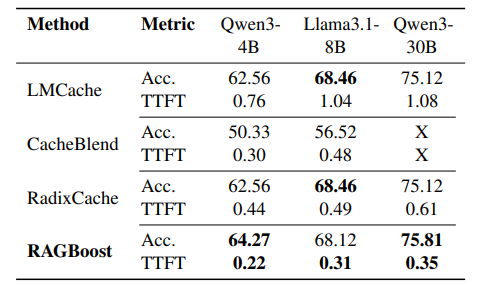
続いて、各手法と最初のトークンが出力されるまでの速さの比較で、これもRAGBoostが最も早い結果となっています。
まとめ
今回はRAGの回答までの速さを2つの方法で高速化する手法「RAGBoost」について紹介しました。RAGを運用しているとどうしても、通常のLLMよりも回答が遅くなってしまう問題に遭遇してしまいます。その問題を、大胆ではありますが、面白い手法で解決しています。特にLLMのキャッシュを利用しやすくするという観点は、LLMの特性をうまく利用した手法でRAGだけではなく他の幅広いAgentの仕組みで応用が利く手法となっていそうです。RAGの速さ、もしくはコストで困っている場合にはぜひご活用ください。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion