本記事では、RAGの性能を高めるための「REFRAG」という手法について、ざっくり理解します。
株式会社ナレッジセンスは、生成AIやRAGを使ったプロダクトを、エンタープライズ向けに開発提供しているスタートアップです。
この記事は何
この記事は、RAGの回答を爆速にする手法「REFRAG」の論文[1]について、日本語で簡単にまとめたものです。
今回も「そもそもRAGとは?」については、知っている前提で進みます。確認する場合は、こちらの記事もご参考下さい。
本題
ざっくりサマリー

REFRAGは、RAGの回答速度を上げるための新しい手法です。「巨額報酬での人材引き抜き」で話題になったMeta社の「Superintelligence Labs」[2]の研究者らによって2025年9月に提案されました。
通常のRAGでは、外部のデータベースから検索した関連文書を、そのままLLMに渡します。しかし、こうした通常のRAGだと入力が長くなり、LLMから回答が来るまでの時間が長くなってしまうという課題がありました。
そこで、「REFRAG」という手法では、検索した関連文書をベクトル化して、ベクトル形式のままLLMに注入します。こうすることで、「LLMから回答が来るまでの時間」を最大で約30倍高速化できます。
ご参考
問題意識
RAG は便利ですが、関連する文書をたくさんプロンプトに入れ込むため、LLMに対する入力文章が長くなり、LLMからのレスポンスが遅くなります[3]。ただ、この論文では、「人間が使う言語って冗長なので、LLMに分からせる目的ならもっと短縮できるよね」 という発想で、情報を圧縮してから、LLMに渡すことに挑戦しています。
手法
普通のRAGでは人間が扱う「テキスト」(日本語とか)を、そのままLLMに入力します。そのため、LLM自身が膨大な計算をしてベクトル化します。この処理には時間がかかるので、この手法では、最初からベクトルで渡してあげることで高速化できるよね、というイメージです。その「テキストをベクトルにする変換器」の作成が大変です。↓
【事前にやっておくこと】
-
モデルの学習
- 変換器を作る。回答生成させるLLM自体もファインチューニングする
- 具体的には、「圧縮された情報から元のテキストを復元する」タスクなどで、お互いを調整
- (詳しいことは、シンプル化のために割愛)
-
(発展)圧縮する/しないの判断を強化学習
- 「全部ベクトル化せず、一部は素のテキストをLLMに渡した方が精度が高い」です。そのため、この「ベクトル化する/しない」の判断基準を強化学習
【ユーザーが質問を入力して来たとき】
-
関連文書を検索
- 普通のRAGと同じ(上図の左上)
-
文書の分割・圧縮
- 検索してきた参考文書を、16文字ずつの「チャンク」に分割
- 準備で作成した「変換器」を使い、各チャンクをベクトル形式に変換(上図の「Encoder」部分)
-
質問テキストをベクトルをLLMに注入
- ユーザーの質問は素のテキスト(トークン)のまま。その後に参考文書をベクトル化したものを入れ込んで、LLMに渡す(上図の右上)
-
最終回答の生成
- 普通のRAGと同じ
この手法のキモは、変換器です。「人間にとって分かりやすい文章は、LLMにとっては冗長なので、もっと圧縮してLLMに渡すべき」という発想はとても面白く、発展の余地があるように感じます。
成果
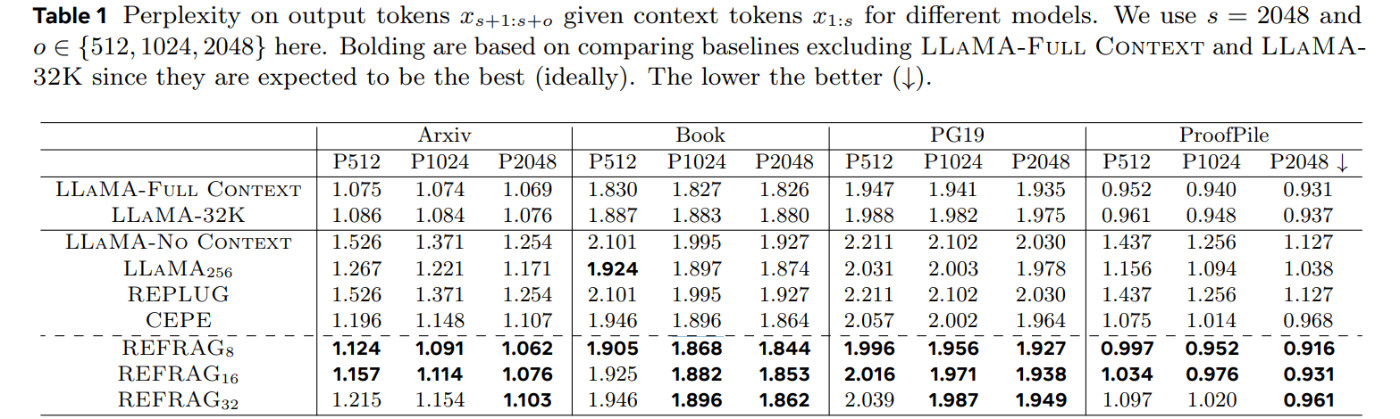
- 最初のトークン生成までの時間が最大30.85倍高速化
- この高速化を、回答の精度(パープレキシティ)を全く損なうことなく達成
- 従来の高速化手法(CEPE)と比較しても3.75倍の速度向上を実現
- LLMが一度に扱えるコンテキストサイズを実質的に16倍に拡張可能に
まとめ
弊社では普段、エンタープライズ企業向けにRAGサービスを提供しています。入力できる文字数(コンテキスト)の長さは、RAGの性能に直結します[4]。特に大企業ほど、一つの業務に対してあらゆる観点を考慮してRAGの回答を作る必要があり、性能を上げるために、入力できる文字数は、多ければ多いほどいいです。
この手法に限らず、入力文字数と回答速度/精度のトレードオフを解決するための手法は、今後も多く出てきそうです。
※ちなみにこの手法、自前のエンコーダ学習、LLMの継続事前学習が必要だったり、かなりGPUが必要です(なのですみません、僕もまだ、手元で試せていません)。ただ、個人的にはこの手法、1-2年後のRAGでは当たり前になると考えています[5]。
ぜひ、みなさまが業務でRAGシステムを構築する際も、選択肢として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていこうと思います。我々が開発しているサービスはこちら。
-
https://www.bloomberg.co.jp/news/articles/2025-06-18/SY0WKMT0G1KW00 ↩︎
-
そう考える根拠は、ここに書くと散らかってしまうので書きませんが、例えばコストについては、富豪企業が「エンコーダと、オープンなLLMを調整した差分」をオープンなライセンスで公開してくれる、ということがあり得ます。また、肝心の「オープンなLLM」自体も、日々急激に性能向上しています。 ↩︎
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion