導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。
今回は、RAGの認知の階層を分析して、ハルシネーションを防ぐ手法「LFD」について紹介します。
サマリー
以前の我々のブログでLLMに無関係な文書を渡すことでRAGの性能が向上する、という突拍子もない論文を紹介したことがありました。
今回紹介する論文では、その無関係な文書がLLM内部でどのような役割を担っているのかを分析し、原因を突き止めました。さらにそこから一歩踏み込み、無関係な文書を渡すことなく、同等の性能を向上させる手法「LFD」を発見しました。
課題意識
RAGのハルシネーション
RAGはユーザーの知りたい情報を検索して、検索結果をLLMに渡すことで、LLMの知らない情報も回答できるようにする為の技術です。しかし、LLMは自身の知る知識と検索結果を明確に区別できないために、たとえ正確に情報を検索できたとしても、正しい情報を回答できないことがあります。(ハルシネーション)
解説
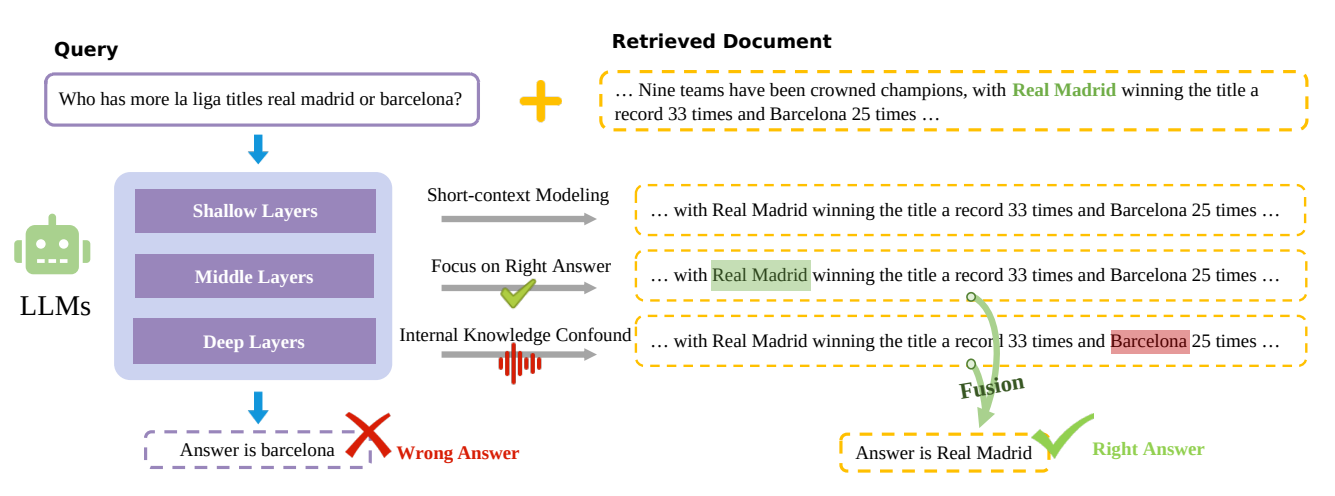
LLMが回答に至るまでの3つの層とハルシネーションの原因

まずこの論文では、LLMのTransformerの層を3種類に分解しており、それぞれ以下のような役割があるとしています。
- 浅い層: 各トークン同士の狭い範囲での関係性を考慮している層。全体の文脈等は考慮していない
- 中間層: 入力された文章の中から重要な文章を見つけ出す層。RAGでは、質問に対する回答として適切な文章を見つける役割を果たしている
- 深い層: モデルが持っている知識を利用して回答する層。RAGでは、ハルシネーションの原因になりうる
浅い層から深い層に順番に処理が行われて、回答が生成されます。
正しい知識を与えたにもかかわらず、ハルシネーションを引き起こしてしまうのは、中間層では正しい回答を見つけられるものの、深い層で内部の知識と混同して正しい回答ができなくなってしまうためです。
無関係な文書がRAGの性能を向上させる理由
ポイントは中間層での正解文書の扱いです。無関係な文書が含まれると、正しい文章のみの場合と比較して、正しい文章に対するLLMの注目度がより高くなります。
これによって、深い層に処理が移行してもLLMとしては、正解の文章に対する注目度が高くなっているため、ハルシネーションが起きにくくなります。
手法
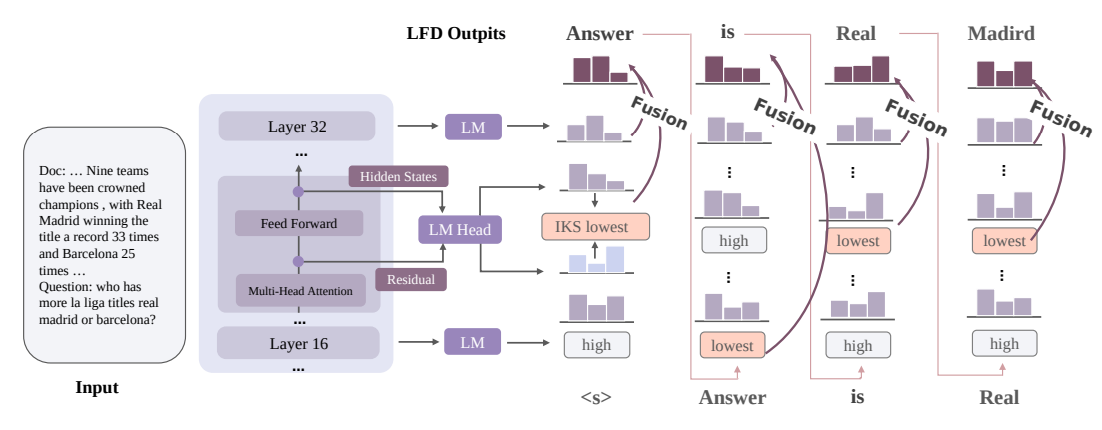
「LFD」はこの前提を基に、関係のない文章を追加することなく、追加した場合と同等の性能を引き出す手法です。以下の二段階の処理を組み込んでいます。
- 外部知識を利用して重要な文章を探している層を数式を用いて探し出す。
- 特定した層と、最終層の出力を統合して、生成するトークンを決定する。
外部知識を使っている層の出力を利用することで、ハルシネーションの発生を防いでいます。
評価

正しい回答があるうえでの出力の精度を比較した表です。GD(X)はXの数値が大きいほど、無関係な文章が入っていることを示しています。LFD (Random)はLFDの1段階目の層の選択をランダムに行った場合の精度を示しています。
多くのモデルと検証データの組み合わせで、LFDの精度が高くなっていることが確認できます。
まとめ
今回は、「無関係な」文書をLLMに渡すことでRAGの精度が上がる原因と、その知見を基に、無関係な文書なしでRAGの精度を上がる手法「LFD」について紹介しました。外部の知識をうまく利用してもらう場合と、LLMが持つ知識を利用してもらいたい場合とで考え方が大きく変わるというのは非常に面白い話だったかと思います。
LLMの中間層の出力を利用する必要があるため、API経由で利用するLLMにこの手法を直接適用するのは難しいですが、ローカルLLM+RAGの組み合わせでは非常に重要な考え方になりそうです。回答に必要な文書を渡しているのにLLMが正解を回答してくれない、という場面でぜひご活用ください。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion
cool
ローカルLlM+RAGをまさにやろうとしてました。勉強になります!