導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。普段はエンジニアとして、LLMを使用したチャットのサービスを提供しており、とりわけRAGシステムの改善は日々の課題になっています。
RAGのシステムの中では、どんな情報にアクセスするかを決定する際に、Embeddingと呼ばれる文章をベクトル化する技術が使用されています。そして多くの場合では小数(float)の多次元ベクトルが採用されています。
しかし、Embeddingの中には各ベクトルの数値を1Bitのデータとして扱うBinary Embeddingというものが存在します。
本記事では、Embeddingの手法の一つであるそのBinary Embeddingについて解説と検証を行います。
サマリー
Binary Embeddingを採用することで以下のような効果を得ることができます。
- 保管するベクトルデータの容量を96%ほど削減できる
- 削減した後でも工夫次第で99%以上の精度を維持することができる
容量が大きすぎることが問題となるデータであれば非常に有用な方法になりうると言えそうです。
この記事について
この記事では、RAGを使用する上で欠かせないEmbeddingの手法の一種である、Binary Embeddingについて紹介します。
発想自体は非常にシンプルで、通常32bitの小数の配列として表現されることの多いベクトルデータを1Bitの配列データとして扱うことにより、容量の減少や検索速度の向上をはかっています。
当然情報量が減ることになるので、精度自体は下がることが想定されますが、それがどの程度なのか。簡単な検証を行なっていきたいと思います。
解説
BinaryEmbeddingの紹介に入る前に、EmbeddingとRAGの関係から触れていきます。
RAGにおけるEmbedding
RAGは簡単に紹介すると以下のようなステップでユーザーの質問に対する回答を生成しています。
- ユーザーの質問を受け取る
- ユーザーの質問をもとに関連する情報を取得する
- 関連する情報とユーザーの質問をLLMに渡し回答を作成する
この中でEmbeddingが関わっているのは2番目の検索の時です。回答に使用する情報をあらかじめいくつかのデータに分解し、その情報をEmbeddingによってベクトルデータに変換、そして検索の際には入力された文字列を同様にベクトルデータに変換し、コサイン類似度の近いものを取得するといった流れで関連度の高い情報を取得しています。
RAGにおけるEmbeddingの課題
RAGの中でも重要な役割を果たしているEmbeddingですが、以下のような問題を抱えています。
- ユーザーの質問に係る情報を正しく集められない
- 保管するデータ容量が多くなってしまう
よく議論されるのは1の精度の部分で、より関連する情報を正確に取得するための手法の検討は、これまで解説してきた通り重要な課題となっています。Embeddingに限定して考えても、文章中の意味合いをより正確にベクトルデータとして表現するためのモデルの開発は盛んに行われています。
以下のようにLLMを提供しているサービスでは、Embeddingも同様に公開されており精度の面でもしのぎを削っています。
その一方でデータ容量とはどういう問題でしょうか?
ベクトルデータのサイズ
Embeddingで生成されるベクトルデータにはさまざまな種類があるため、ここではOpenAI社のtext-embedding-3-smallで考えていきます。
text-embedding-3-smallというモデルでは、ベクトルデータに変換すると1536次元の4byteの小数(float)で表現されるようになります。この時ベクトルデータは、それ単体で6KBとなります。
もちろんこの値だけではデータ容量の問題になるかは分かりません。ここからは、よく利用されるチャンク化手法でドキュメントを保管することを想定して、どの程度のサイズとなるかを確認します。以下に設定をまとめます。
- 保管するファイルはテキストデータとする
- 保管するファイルのデータは100MBとする
- 平均500文字ごとにチャンクが生成される
- ベクトル化には
text-embedding-3-smallを用いる
この時、
生成されるチャンクの個数は
100MB / (500 * 2Byte) = 100,000個
よってベクトルデータの容量は
100000 * 6KB = 600MB
以上のことから、100MBのデータを保管しようとするとその6倍の容量のベクトルデータが必要になることがわかります。保管しているデータそのものよりもベクトルのデータの容量の方が大きくなるというのは予想外に感じる方もいるのではないでしょうか?
BinaryEmbedding
この容量の問題に対して各ベクトル情報を1Bitにまで落とし込んで、容量を削減する手法がBinaryEmbeddingです。元々32Bitのfloatデータだったものを、1Bitにしているのでベクトルに使用するデータ量は96%ほど削減することができます。
また検索の際にはコサイン類似度ではなくハミング距離を用います。ハミング距離とは、端的に言えば二つのBitデータの配列を比較して、0, 1の値が異なるものがいくつ含まれるかで計算されます。ハミング距離が小さいものを関連性の高いチャンクデータとして扱います。
しかし、この手法は小数を無理やり0,1に変換しただけなので当然精度が気になります。この手法がRAGにおいてどういう立ち位置となるかを確認するため検証を行います。
検証と結果
検証は以下の条件で行います。
- データのソースは
wiki40b/jaを使用し、ベクトルデータベースにはFaissを使用する - データの数は 1K, 10K, 100Kで試す。
- データを保管する際には各データの先頭200文字をEmbeddingしたものを使用する
- 検索のクエリは「[
wiki40b/jaのタイトル]とは?」という形式で行なう - 精度の検証は
text-embedding-3-smallで取得される検索結果を正解データとして、どの程度一致するかを検証する
今回精度の検証の際に正解データをtext-embedding-3-smallで取得できたデータとした理由は、その他のEmbeddingがあくまでtext-embedding-3-smallから生成された値であるため、仮にtext-embedding-3-smallで不正解でBinaryEmbeddingでは正解だったとしても、偶然一致していたに過ぎないと判断したためです。
手法
本実験で使用する手法は以下の3つになります。
- binary embedding
- int8 embedding
- binary embedding with rerank
それぞれ簡単に説明します。
binary embedding
こちらの手法は、別の手法で生成される小数のベクトルデータをそれぞれ0か1の値に変換したベクトルデータにする手法となります。本実験では、text-embedding-3-smallで得られた多次元ベクトルデータをそれぞれ、0以上であれば1、0未満であれば0となるように変換します。
なお、Faissを使う都合上ビットデータをそのまま扱えないので8個ずつまとめてバイトの配列にしてから登録しています。
バイトデータへ変換するためのコード
def floats_to_binary_bytes(float_array):
# 1. フロート配列を1と0のバイナリ配列に変換
binary_array = [(1 if x > 0 else 0) for x in float_array]
# 2. バイナリ配列を8ビット毎にまとめてバイトに変換
byte_list = []
for i in range(0, len(binary_array), 8):
byte_chunk = binary_array[i:i + 8] + [0] * (8 - len(binary_array[i:i + 8])) # 8桁に満たない場合は0で埋める
byte_value = sum(bit << (7 - pos) for pos, bit in enumerate(byte_chunk))
byte_list.append(byte_value)
# 3. バイトの配列に変更
byte_array = bytearray(byte_list)
return byte_array
int8 embedding
こちらの手法は、別の手法で生成される小数のベクトルデータを-128 ~ 127の範囲に落とし込み内積を利用して計算する手法となっています。本実験では、text-embedding-3-smallで得られた多次元ベクトルデータを127倍してint8データに切り捨てで変換するという手法を採用しています。
binary embedding with rerank
こちらの手法はbinary embeddingで取得する結果の量を増やし、そこからそれぞれのfloatのEmbeddingを計算し並べ替えを行うという手法です。binary embeddingと比べると時間や費用の面で劣ることになりますが、精度の面で大きなアドバンテージを得ることができます。
こちらの手法は以下の記事を参考に設定しました。
結果
それぞれの手法ごとに、縦軸を精度、横軸をデータ数として結果をまとめます。
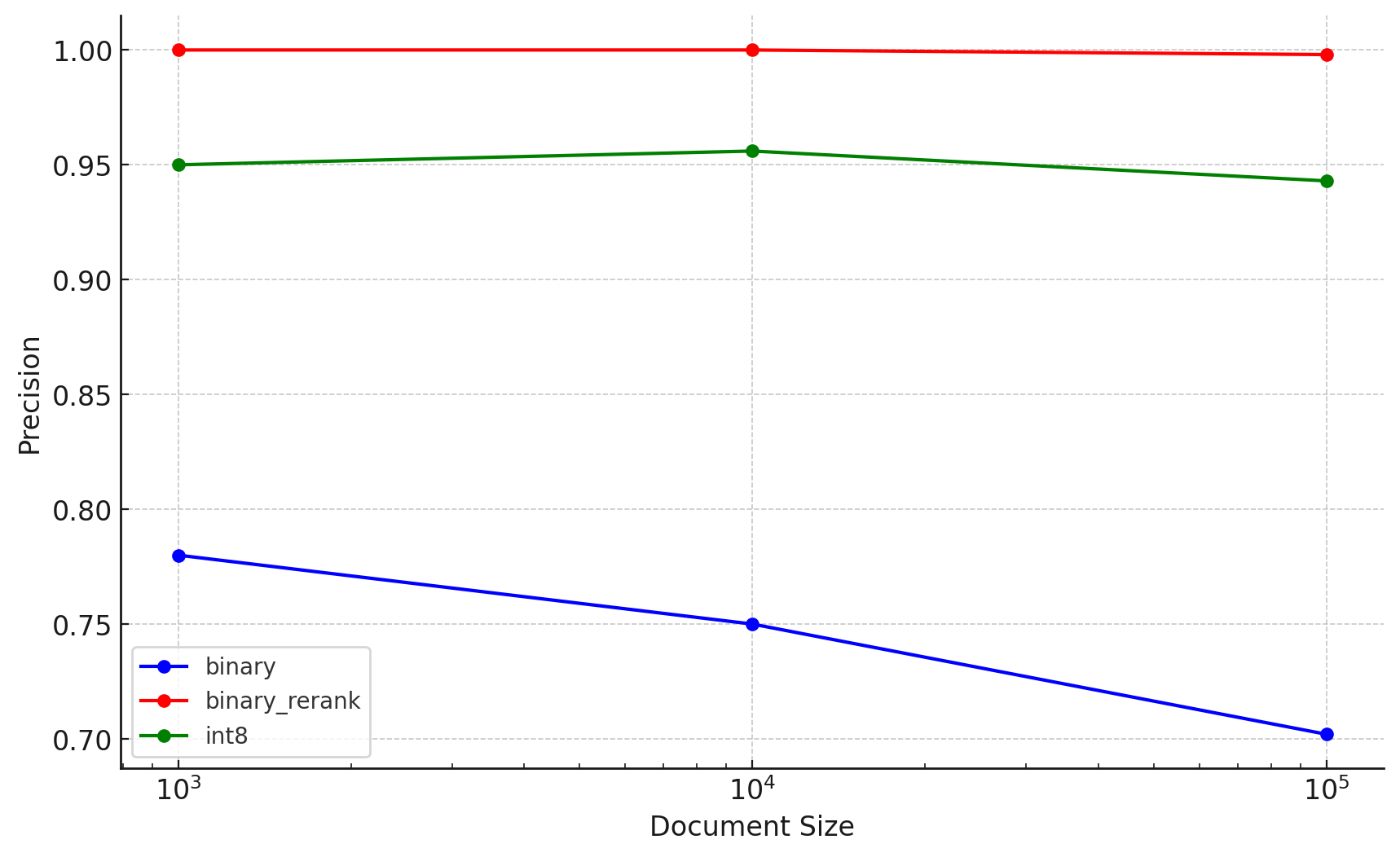
さらに結果を表でまとめてみます。
nameは手法+データサイズ、doc_sizeは検索元のデータ量、precisionは類似度判定の一番が一致した割合、mrrは上位10個以内で一致したものについて計算した結果、をそれぞれ表しています。
| name | doc_size | precision | mrr |
|---|---|---|---|
| binary-1000 | 1000 | 0.780 | 0.856940 |
| binary-10000 | 10000 | 0.750 | 0.823898 |
| binary-100000 | 100000 | 0.702 | 0.789464 |
| int8-1000 | 1000 | 0.950 | 0.975000 |
| int8-10000 | 10000 | 0.956 | 0.976667 |
| int8-100000 | 100000 | 0.943 | 0.969783 |
| binary_rerank-1000 | 1000 | 1.000 | 1.000000 |
| binary_rerank-10000 | 10000 | 1.000 | 1.000000 |
| binary_rerank-100000 | 100000 | 0.998 | 0.998000 |
binary embeddingは軒並み精度が大きく下がり、サイズが大きくなる事に精度をどんどん下げています。
int8 embeddingは精度は95%程度となっていますが、ファイル数の増加に対しては緩やかな精度の低下となっていそうです。
binary embedding with rerankは、精度がほとんど落ちていません。ただし、大きなサイズでは外れている場合も出ているのでさらにファイル数を増加させると精度は下がっていくかもしれません。
考察
意外な結果では無いと思いますが、表現するためのデータ量を減らすごとに、そしてファイル数を増やすごとに精度が下がる傾向にあります。
その一方で、Rerankと組み合わせることで少なくとも現段階のデータ量では元のEmbeddingと同等の性能を出せているといえそうです。ただしその分Embeddingの費用が毎回かかることになるのでドキュメント側は、よく使うチャンクのEmbeddingの結果を一部キャッシュするなどの対応が必要になりそうです。
また今回精度の面で申し分なかったbinary embedding with rerankもよりデータ数が増えた場合には精度が下がるおそれがあるます。精度の最大値を目指したい場合は最新のEmbeddingモデルの結果をそのまま使うことをおすすめします。
まとめ
Embeddingモデルはよくモデル間の精度比較や、Embedding時の費用の観点で考えることが多いため出力されるサイズで考えるというのは新鮮で良い機会だったと思います。特にEmbeddingの結果を複数の段階で絞っていく機能は、今後活用の余地がありそうな考え方かと思います。
とはいえ現時点ではいかにしてRAGの精度を上げるか、という点にフォーカスしたいので容量を削減するために精度を下げるという選択肢はまだ取れないかなと思います。
また、いくつかのベクトルデータを管理するサービスではBinary Embeddingに対応していなかったり、検索の最適化がなされていないことがあるため、採用する場合はデータベースの選定からやり直す必要があることもあります。
Embeddingの精度が十分に上がり、Embedding以外の部分がネックになり始めたときにはこの記事を見返して再度サービスへの導入を検討できればと考えています。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion