導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。普段はエンジニアとして、LLMを使用したチャットのサービスを提供しており、とりわけ文字起こしシステムの改善は日々の課題になっています。
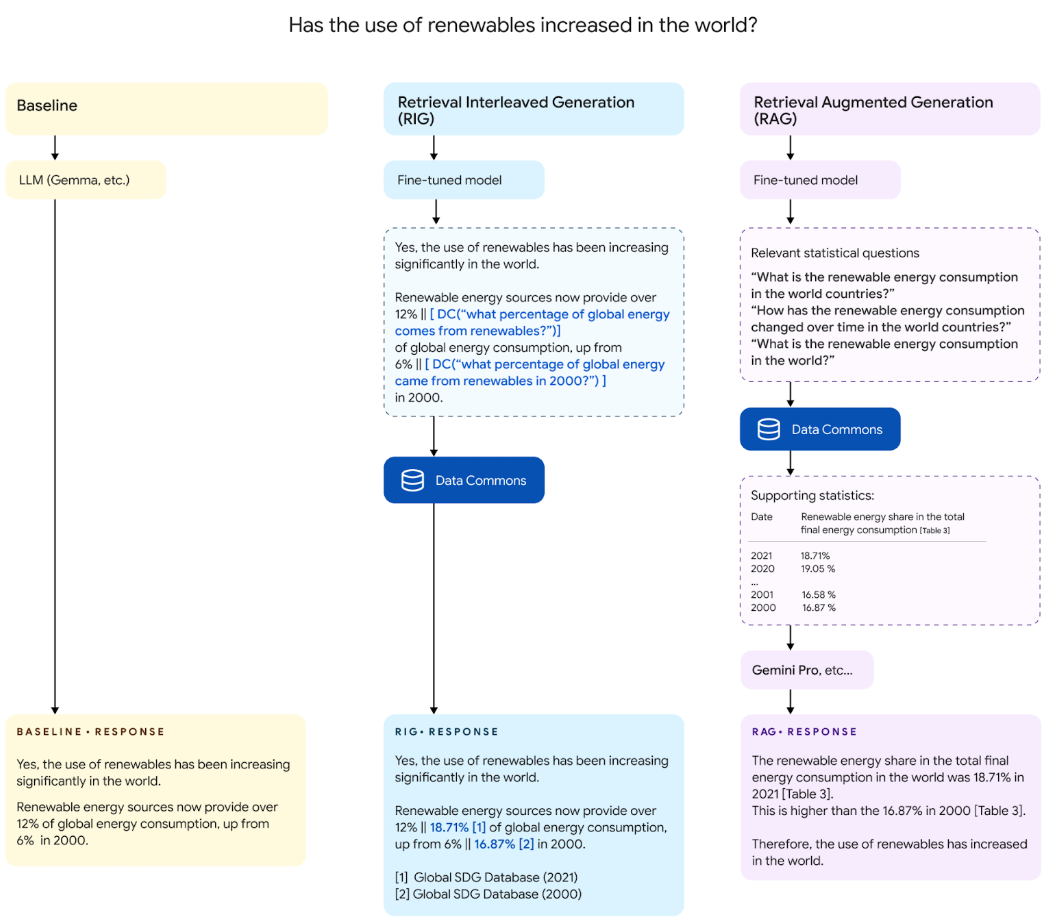
今回は、LLMの幻覚を検知するための仕組みとしてGoogleが紹介する「RIG(Retrieval Interleaved Generation)」について解説します。
ちなみにこのRIGは2024年の9月には公開されていたのですが、最近再びポストされていたので、せっかくのこの機会に紹介できればと思います!
サマリー
LLMはその性質上ハルシネーションを完全に避けることが難しいです。このため、LLMの利用には利用者側がある程度正確に情報を判断する必要があります。
しかし、その生成された文章の中に情報の参照元があるだけで、真偽の判断の難易度はぐっと下がります。「RIG」はLLMをファインチューニングすることで、LLMの出力とData Commonsに含まれる参照用のデータを結びつけることができるようになります。
これにより、LLMの出力をより信頼性の高いものへと変えることが可能になります。
問題意識
LLMのハルシネーション
LLMは、ハルシネーションと呼ばれる誤りを含む可能性があります。さらに、出力された文章に関連する知識がない場合、その誤りに気づきづらいという問題点もあります。このため、LLMを使用することで事実を誤認してしまう可能性や、そもそもLLMの解答が信頼できず利用しづらいといった問題が発生します。
RIGとは
概要
RIGは、LLMの生成した回答が正しいかを判断するための仕組みです。LLMの生成した回答に対して、関連する情報をData Commonsという大規模なデータベースから検索し取得、その結果を根拠として提示します。この根拠を得られることでユーザーはLLMの示した情報をより信頼性のあるデータとして取り扱うことができます。
手法
RIGがどのようにして根拠となる情報を取得しているかを説明します。
手順は以下のようになります。
- ファインチューニングされたLLMでユーザーの質問に回答。このファインチューニングは、自然言語検索クエリを回答文中に埋め込めるように学習されています。
- 出力に埋め込まれた検索クエリを抽出。下の図で言うところの[DC(...)]の部分です

- LLMの出力した検索クエリをData Commons内のデータを検索できるクエリに変換。Embeddingやテンプレートパターンを用いて変換されます。
- クエリで検索した結果を検索クエリの部分に当てはめて出力。

詳細な特徴
RIGはいくつかの工夫により、高い精度で事実に即したデータを取得しています。
LLMの推論を利用しない
LLMが幻覚を起こす原因は、推論によるところが大きいとされています。そこでRIGは、推論ではなくデータの変換、自然言語検索クエリへの変換に限定してLLMを利用しています。
自然言語クエリの利用
RIGでは、情報を検索するためのクエリは自然言語で取り扱うようにしています。正確にはある程度フォーマットの決まったクエリではあるのですが、Jsonのような検索に最適化されたクエリのフォーマットを利用していません。その目的としては、LLMの出力は自然言語が適していることと、そしてより簡潔であることを論文中ではあげています。
検索クエリへの変換
Data Commonsの検索では、Embeddingを用いた検索ではなくルールベースのクエリ生成を元にした検索を行っています。Data Commons内にはデータのまとまりごとにテーブルが存在し、その中にはさらに場所や属性に結びつく具体的なデータが保管されています。
具体的にはまずRIGがでは、クエリに含まれる重要な単語を抜き出します。抜き出す単語は、トピックや場所、属性を示す単語、などがありトピックはEmbeddingを用いてテーブルの決定に、その他の情報はテーブルから実際に取り出す値の決定のために利用されます。
そして取り出された情報とクエリの情報から、クエリの形式を分類します。

これらの情報を元に最終的にData Commons内の情報を取得するための構造化クエリを生成します。
RAGとの違いからみる特徴
データベースから情報を取得してユーザーに提供するという点で、RIGもRAGも似たもののように思います。しかし、その目的やそれを実現するための手段は異なるのでその点について整理します。
| 観点 | RIG | RAG |
|---|---|---|
| 目的 | LLMの宣言が正しいかどうかの根拠を示す | ユーザーの求める情報を検索と推論を元に回答する |
| 検索 内容 |
検索すべき内容が決まっている | 検索すべき内容を推論する |
| 検索 方法 |
LLMを使用しない変換ロジックで検索 | 文章をベクトルに変換して検索 |
| 出力 | 多くの場合、単一のデータ | 質問に沿った自然な文章 |
RIGは、RAGと出発地点が異なります。繰り返しにはなってしまいますが、RIGは出力された文章をベースにその内容が正しいかを確認します。もしくは、RIGはRAGよりも目的を絞ることによって、目的に対する精度を向上させている手法、ということもできます。
成果
ここからは、RIGを利用することでどの程度正しい情報を知れるようになるかという点と、RIGとRAGがどういった原因で不正確な情報を提示してしまうかをまとめた結果を紹介します。

この表から、まずLLMが質問にそのまま答えられた確率は5-17%なのに対して、RIGが正しい結果を取得できた確率がおおよそ58%と大幅に改善されていることを示しています。その反面、27-32%の確率でどちらも正しい結果を返せていないことを示しています。

この表は、RIGが正しい結果を返せなかった根拠を分析したものとなっています。正しい結果を返せなかった原因のおおよそ75%は自然言語検索クエリから構造化クエリに変換する過程のミスで、残りのおおよそ25%は自然言語検索クエリを生成する段階でのミスと分析されています。
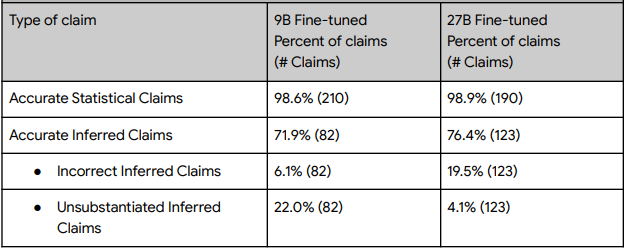
続いてはRAGを用いた、回答の正確性に関する結果です。統計的な値をそのまま検索するようなタスクの場合、その正確性はおおよそ99%と高いものとなっています。そこから推論を用いて主張を行おうとすると正確性が22-27%下がってしまっています。
原因を分析すると、性能の低いモデルではデータにない情報を推論で出力する傾向にあり、性能が高いモデルでは、誤った推論(見落とし)を出力する傾向にあります。
なおこの結果は、正しい情報を取得できたうえで正しい回答に結びついているかの確率を表しており、そもそもデータの検索に失敗したものは考慮していない点に注意して下さい。
まとめ
LLMのハルシネーションを検知する「RIG」について紹介しました。この機能の目的やRAGとの違いについて整理できれば幸いです。ここからはいくつかの観点で個人的な感想を交えて、RIGについてまとめたいと思います。
惹かれた点
この手法で特に面白いと感じるポイントが2つあります。
目的を限定的にすることで精度を向上させようとする試み
RAGの手法というのは、カバーする範囲が広いため、精度が高いとされる手法も目的が違うと精度が出ないこともしばしばあります。RIGは、真偽の確認、とりわけ統計的な値の真偽の確認に着目して、精度を向上させる取り組みを行っており、その点で面白い考え方だと思います。
データの検索方法
一般的にRAGでは自然言語をそのままEmbeddingでベクトルに変換し検索を行うか、構造データをそのまま生成させて検索することが多いです。これに対してRIGでは、フォーマットに則った自然言語による検索を利用しています。すでに触れていますが、これにより自然言語による簡潔な検索の表現と、構造化データによる厳密な検索の利点の両方を取ることができています。(もちろん双方の欠点を受け継ぐこともあるでしょうが。)LLMとデータベースが歩み寄るための面白い手段だと思います。
おすすめのユースケース
ここからはRIGを使う上でのおすすめのユースケースについて、紹介します。なおここで提案する内容は検証等が済んでいない点に注意してください。
RAGの回答文中の参照の提示
RAGの回答の中で、その回答がどういった情報を元に発せられているのかを示すのに適しているように感じました。応用方法はいくつかバリエーションがあり、例えば検索済みのソースデータと結びつけるのに利用したり、RIGと同様にもう一度データベース内から検索を行ってダブルチェックを行うなどが考えられます。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion