導入
こんにちは、株式会社ナレッジセンスの須藤英寿です。普段はエンジニアとして、LLMを使用したチャットのサービスを提供しており、とりわけRAGシステムの改善は日々の課題になっています。
この記事では、学習不要な方法で文章のEmbedding性能を向上させる手法 GenEOL について紹介します。
サマリー
GenEOLは、文章をLLMを使用して複数の文章に変換し、ベクトルデータを計算する手法となっています。LLMとEmbeddingを組み合わせたベクトル化の手法はこれまでにも提案されて来ましたが、構造の変換と要約の作成を組み合わせることで、性能を高めています。
問題意識
ドキュメントのチャンクをそのまま埋め込む問題点
一般的なRAGにおけるテキストのベクトル化は、ドキュメント内の文章を一部切り出した文章を入力としてEmbeddinigモデルを介したベクトルデータの変換が行われます。しかし、切り出されたチャンクは多くの場合は不均一で冗長であったり、構成が異なることがあります。
このため、チャンクをベクトルに変換する際に内容だけではなく、それ以外の構造などに影響を受けたベクトルが生成される可能性が高くなってしまいます。結果、Embeddingを用いた検索での性能低下が発生してしまいます。
手法
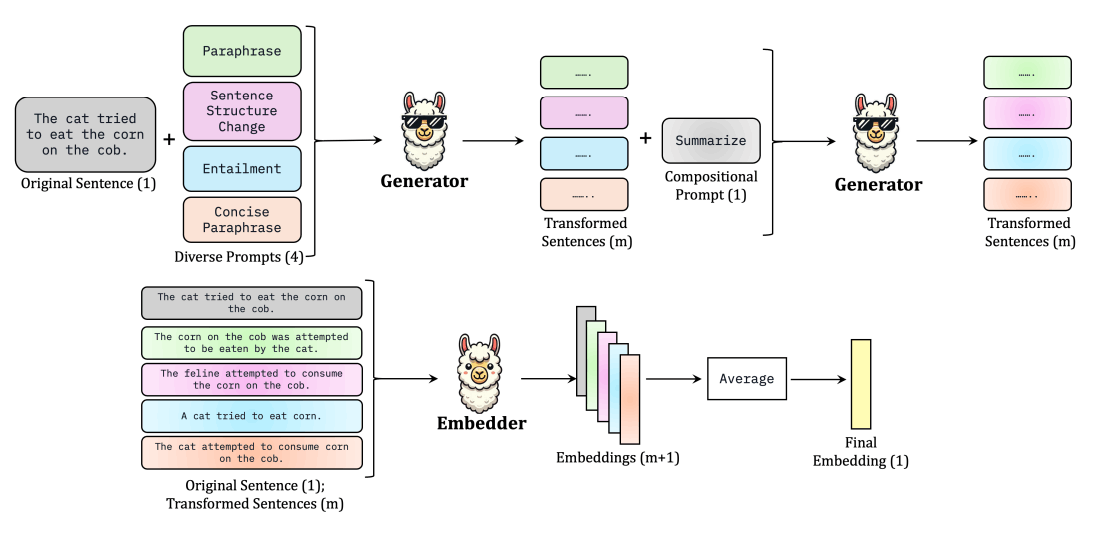
GenEOLはドキュメントをベクトルデータに変換する際に、複数のステップを経る必要があります。
- ドキュメントを複数の手法で構造の異なる形式で文章化
LLMを使用して、ドキュメントのテキストを複数の方法で別の文章へと変換します。構造を変換する、簡潔にする、言い換えるなど様々な方法がありますが、共通して元の文意を残したまま文章を変換することがポイントです。
- 変換後の文章を更に要約を作成する
作成された文章をそれぞれLLMを利用して、さらに要約した文章を作成します。このプロセスは1で出力された文章全てに適用されます。
- 文章ごとにベクトル化して平均を算出する
文章ごとにEmbeddingモデルを使用してベクトルを計算し、それらの平均を取ったものをドキュメントのベクトルデータとします。
成果
今回紹介している論文では、様々な軸で性能に関する評価を行っているので順を追って説明していきます。なお、論文内で登場するSTSは文意の近さを評価するための手法で、複数種類登場するのはこれまでに複数回手法に関する発表があったためです。

GenEOLが性能の向上に寄与していることを確認するため、工夫なしのBaseLine、複数の方法で置き換えた手法、そしてGenEOLの手法を比較しています。結果は、GenEOLがもっとも良い性能を示しています。

続いて、他の手法との比較をSTSの種類、Embeddingモデルの種類の軸で他の手法との性能を比較しています。最大3.87ポイントの性能向上を確認できます。

最後に、生成する文章の種類数と性能の関係をグラフに示したものです。生成する文章の種類を増やすごとに性能は上がっていきますが、段々と頭打ちになっていることが確認できます。ただし、二種類生成するだけで、既存の手法以上の性能が期待できます。
まとめ
この論文では、LLMによる二段階の文章の変換を利用してEmbeddingモデルの性能を引き上げるための手法について述べられていました。文章を複数種類の別の文章に変換することで、文体など内容にかかわらない純粋な情報に焦点を当てたベクトルデータを生成できます。ただし、この影響で物語などの表現が重要な文章では他の手法と比較して性能が低下することが確認されているようです。
もし実用化を考える場合には以下の観点を考えてみるとよいかもしれません。
- モデルの学習をしないで済む方法を採用したい
- 費用、時間が数倍になってもいいので性能を上げたい
- 文章の内容そのものが重要になってくるドキュメントを使用している
試すのも比較的簡単な手法で、直感的にもわかりやすい手法なので是非試してみようと思います。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion