はじめまして。ナレッジセンスの門脇です。生成AIやRAGシステムを活用したサービスを開発しています。本記事では、「RAG vs ファインチューニング」について、DSL(ドメイン固有言語)をコーディングする性能という観点から比較した論文を、ざっくりまとめます。

この記事は何
この記事は、RAG vs ファインチューニングに関する論文[1]を、日本語で簡単にまとめたものです。
「RAG vs ファインチューニング」の論文は、他にもあります。例えば、時事問題などのシンプルな知識の質疑応答であれば、RAGの方が優れています。[2]
今回の論文では、「ドメイン固有言語(DSL)をコーディングする性能」をに焦点を当てて比較しています。一見するとファインチューニングの方が有利そうなタスクについて比較しているのが面白い点です。
本題
ざっくりサマリー
この論文では、RAGとファインチューニングの性能比較をしています。特に、「ドメイン固有言語(DSL)をコーディングする能力」という観点で比較しています。つまり、「独自のAPI仕様書に基づいてコーディングする能力」で比較するイメージです。結果として、RAGが、ファインチューニングと同等の性能を達成しています。面白い点は、RAGの性能を最大限引き出すための工夫です。通常のRAGで扱うような、単純なドキュメントだけでなく、コーディング例をデータベースに大量に保管しておき、ユーザーの質問に合わせて引き出して使う、という工夫が登場します。
問題意識
大規模言語モデル(LLM)は便利ですが、ニッチな情報にはあまり強くありません。つまり、一般的なプログラミング言語(Python、C++など)は得意ですが、特定のタスク専用のプログラミング言語(DSL)については不得意です。DSLにはカスタム関数名が多かったり、頻繁に更新されたりするため、LLMがハルシネーション(存在しない関数やパラメータの生成)やシンタックスエラーを起こしやすいという問題があります。
手法
ファインチューニング
こちらはシンプルに、OpenAIのCodexというコード生成モデルを、約67,000の自然言語-DSLペアを使ってファインチューニング
最適化されたRAG
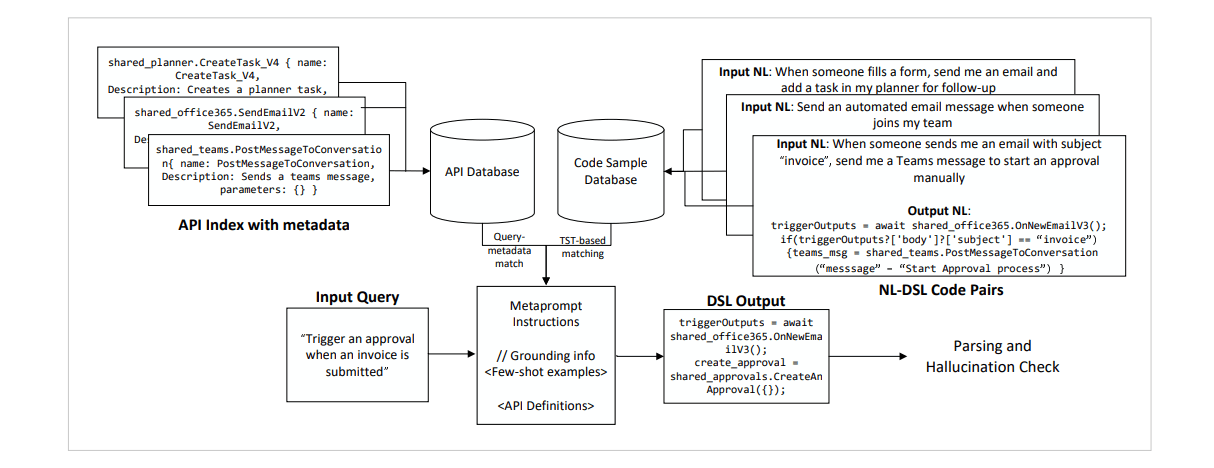
ユーザーの質問に関連するコーディング例・仕様書をそれぞれデータベースから引き出し、LLMに渡すという点が特徴的です。
- 自然言語-DSLのコーディング例をDBから取得(上記の図の右上部分)
ユーザーの質問に基づいて、動的にコーディング例を取得します。(※詳細:埋め込みモデルをファインチューニングしているのも特徴。Target Similarity Tuningという手法を活用) - APIの仕様書をDBから取得(上記の図の左上部分)
1のコーディング例には無い、最新のAPIの仕様を補うために重要です。こちらも、ユーザーの質問に基づいて、関連する仕様をLLMに渡します。
今回の論文のRAGが一般のRAGと違う点は、仕様書だけでなく、「類似した回答例」もLLMに渡している点です。これは、いわゆるFew-Shotプロンプティング[3]というプロンプトエンジニアリングの手法をRAGに応用しているものです。Few-Shotプロンプティングとは、質問と回答の例をいくつか示しながらLLMに質問する手法です。これにより回答精度が向上することが知られています。(以前、こちらでも紹介しています。)
成果
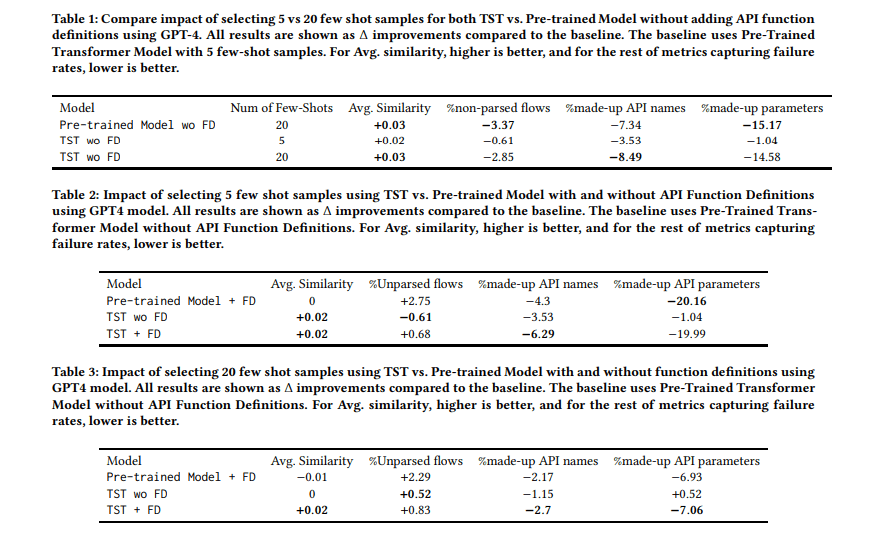
- Few-ShotでLLMに渡すサンプル数は多いほうがいい
- 5件より20件の方が回答精度がいい
- それ以上多くてもあまり変わらなかった
- RAGの性能 (vs通常のLLM)
- API名のハルシネーション率が6.29ポイント減少
- 引数キーのハルシネーション率が約20ポイント減少
- ファインチューニングとの比較
- RAGは、ファインチューニングとほぼ同等の成果を出したと言えそう
結論として、性能が同じなのであれば、新しいAPIの仕様が追加されたときに更新コストが低いRAGを利用した方が、メリットがありそうです。
まとめ
驚いたのは、「独自のAPI仕様書に基づいてコーディング」させるという、通常、ファインチューニングした方が精度が出そうなタスクであっても、RAGを使って同等の性能を引き出せたということです。
今回の論文から得られる抽象的な学びとしては、「ファインチューニングに使えるペアデータがあるんだったら、それをRAGに使えば同じ精度出るし運用コストも低いので、まずはRAGでいいのでは?」ということでしょうか。
みなさまが業務でRAGシステムを構築する際も、精度を上げる工夫として参考にしていただければ幸いです。今後も、RAGの回答精度を上げるような工夫や研究について、記事にしていきます。我々が開発しているサービスはこちら。
株式会社ナレッジセンスは、「大企業の知的活動を最速にする」をミッションに掲げ、社内データ検索ができるAIチャットボットを開発・提供しているスタートアップです。このブログでは、LLMや検索技術、RAGの実装戦略について知見を共有します。生成AIやRAG技術を使って最高品質の実装をしたいエンジニア向けのコンテンツです
Discussion