過学習からLLMへ
0.前書き
はじめまして。株式会社Knowhere CTOの今井と申します。
私たちは、「誰もがスポーツが上手くなれる環境を」をミッションに掲げ、AIなどのテクノロジーの力を用いたソフトウェア等の研究開発を行なっています。
テック企業の一員として、私たちが学んだり開発したりした技術や知識を発信していきたいと思います。どうぞよろしくお願いいたします!
1.はじめに
2023年4月現在、ChatGPTをはじめとしたLLM(Large Language Model, 大規模言語モデル)の発展によって、世界中でAIの研究開発が更なる加速を始めています。この発展の一因には、「Large」の名前が示す通り、AIモデルの大型化による性能向上の発見が挙げられます。
実は機械学習の世界では、モデルを大きくし過ぎると過学習という現象によって性能が低下してしまうことが昔から常識のように考えられていました。ところが近年の深層学習の研究の積み重ねによってこの常識は少しずつ見直されていき、やがてはLLMの成功へと繋がっていきました。
この記事では、過学習とは具体的にどういうことかから説明を始め、現代のLLMに至るまでにどのような研究が進められてきたかの一例を紹介していきます。近年のブームに伴って把握しきれないほど膨大な研究結果が生み出され続けていますし、一方でまだ完全に解明できていないところもいくつもありますが、深層学習研究の歴史の雰囲気が少しでも伝われば幸いです。
前提知識
- 必要な前提知識は、高校程度の数学・統計レベルに留めたつもりです。
- 登場する機械学習の用語や概念はほとんど記事内で説明しています。
- 超最新の専門的な研究については触れていません。
- プログラミング言語やライブラリには触れていません。それらの前提知識は不要です。
ただ、全くの未経験よりは、機械学習のサンプルコードを動かしてみたことくらいはある方が理解が早いかもしれません。
2.過学習とは
2.1 機械学習の基礎の基礎
機械学習とは、コンピュータがデータから何かを学習し、それに基づいて予測や分類を行う技術のことです。この、データから学習を行なったり、未知のデータに対して予測を行ったりするモノ(アルゴリズム・AI・etc)は、機械学習の世界ではモデルとも呼ばれています。
例えば、次のシンプルな例は、二つの数値の関係性を一次式のモデルに学習させたものです。

このデータは人工的に作ったものなので実際には決まっていませんが、例えば、
もし、青丸のデータがたくさんある場合に、
予測モデルの構造(=データの関係に関する仮説)は不都合がない限りどのような形でも構いません。まずは
学習データの各々の

一次式に限らず一般的に、学習アルゴリズムによって調整されるモデルの変数はパラメータと呼ばれます。また、モデルに含まれるパラメータの数のことをモデルサイズやモデルの複雑さなどと呼んだりします。
最後に、英語の論文などでは学習(learn)と訓練(train)は別のテクニカルタームとして区別して使われますが、この記事では他の日本語文書の慣習と同様にごっちゃになっています。
2.2 モデルサイズと過学習の関係性の一例
どんな構造のモデルでも、どんな学習アルゴリズムでも、どんな訓練データでも、高性能な=誤差の小さなモデルが得られるかといえば、もちろんそんなことはありません。
例えば先ほどのグラフをよく見ると、訓練データ(観測データ)は直線ではなくやや下に凸な曲線の上に乗っているように見えます。にも関わらず予測モデルが一次式では、パラメータ
それならばと、一次式の代わりに二次式

誤差(RMSE)は
それでは、もっと大きな次数の多項式のモデルを使用してみるのはどうでしょうか?人間がデータの大まかな形を調べてから次数を選ぶのは、不便ですし、データの真のルールの曲線の形によっては視覚的に判断するのが難しかったりします。また、高次の項の係数を
実際にやってみましょう。例えば30次式で学習した結果は次のようになります。

誤差は
このように、古典的なモデルでは、モデルが訓練データに過度に適合してしまうと、予測に使いたい未知の新しいデータに対してうまく汎化できなくなる現象が発生します。これが過学習の一例です。
多項式モデルの次数を増やすということは、一般的な言い方をすると、モデルサイズを増やしたということに相当します。この節では目的変数と従属変数が一つずつの多項式回帰モデルの例を紹介しましたが、他のタスクやアルゴリズムの場合でも、モデルサイズを過度に大きくし過ぎることで過学習が発生する場合があります。
なお、今回の例では学習後の予測モデルをグラフ上にプロットして形を確認しましたが、この方法は一元方程式以外では難しいです。一般的には、手持ちの全データを、モデルを訓練するための訓練データと、モデルの汎化性能を検証するための検証データに分割して、それぞれの損失を比較するという方法で過学習の発生を確認します。30次式の誤差は2次式よりも下がりましたが、これは(訓練データを分けずに全て使った)訓練誤差が小さくなっただけであって、(未知の新しいデータに対する)検証誤差が小さいわけではないことを意味しています。過剰なモデルサイズによる過学習が発生している場合には、訓練誤差と検証誤差とモデルサイズの関係は以下のようなグラフになると考えられています。

3. Bias-Variance分解とトレードオフ
次に、モデルサイズを増加させると何故過学習が生じるのか、という議論においてよくセットで語られるBias-Variance decomposition(バイアス-バリアンス分解)およびBias-Variance tradeoff(バイアス-バリアンス トレードオフ)について説明します。
結論を先に述べると、古典的な機械学習においては、検証誤差をBiasとVarianceという二つの項の和に分解した場合に、モデルサイズに対して二つの項が次のグラフのようにトレードオフ的に変化するために検証誤差全体がU字曲線になる、と考えられていました。

以下の節では、この分解とトレードオフについて詳しく説明していきます。
3.1 Bias-Variance分解
まず、分解は、深層学習も含めて全てのモデルで正しく成立する数学的な理論です。
この記事ではこのページの定義をお借りして説明します。
- データの目的変数を
y x x x - 以下の議論では、モデルの訓練に使用する学習アルゴリズムは何らか特定のものに固定します。
- 訓練データおよび検証データは分布
P (x, y) \sim P -
P n D D \sim P^n -
y x y \bar{y}(x) - データセット
D \sim P^n h_D D h_D - 様々なデータセットで学習したモデルの期待値
E_{D \sim P^n}[h_D] \bar{h}
このとき、訓練データをランダムにサンプリングして学習した時の検証誤差(MSE)の期待値
-
第一項
E_x[(\bar{h}(x) - \bar{y}(x))^2] -
第二項
E_{x, D}[(h_D(x) - \bar{h}(x))^2] -
第三項はあまり決まった名前はありませんが、モデルに関する変数の含まれていない、データ固有のノイズ・削減不能なノイズの分散です。
先に述べた通り、この分解は深層学習も含めた任意のモデルのMSEについて成立します。また、ここまでの理論だけでは、モデルの汎化性能についてこれ以上何かが言えるわけではありません。
3.2 Bias-Varianceトレードオフ
目的変数やモデルに具体的な定義を与えない限りはこれ以上議論が進まないため、ここでは前節で説明した多項式モデルを例にバイアスとバリアンスがどうなるかを考えてみましょう。
学習データ
それでは、先にバリアンスの方を見てみましょう。バリアンスの定義は



1次式、2次式は、そもそも多様な形の曲線を取れないこともあって、異なる
次にバイアスの方を見てみます。
まず、1次式、2次式は次のようになりました。

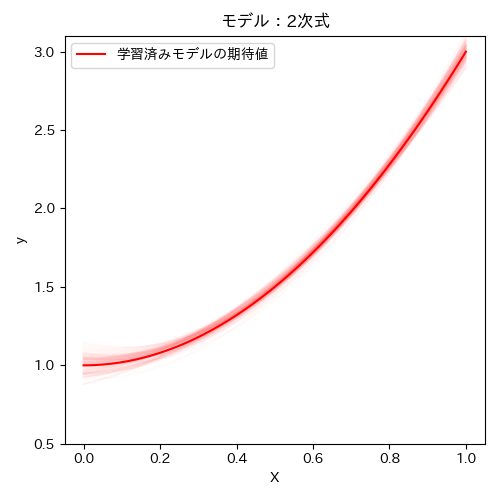
10万全ての学習結果の平均が濃い曲線です。薄い線は最初の100個のデータセットの学習結果を薄く重ねてプロットしたものです。
2次式の方は、
なお、30次式の場合はどうなるかというと、実は次のようになりました。

あくまでも
ただし、
4. 深層学習モデルの汎化と性能向上
前節では、ある特定のモデル(およびタスク・学習方法)において、モデルサイズを大きくするとバリアンスが増大して過学習が発生する例を紹介しました。それでは、古典的な常識の通り、モデルサイズを変化させた場合のバイアスとバリアンスのU字曲線のトレードオフは、任意のモデル・タスク・学習方法で発生するのでしょうか?
過学習が生じる
この節では、古典的な常識を打ち破って、LLMが非常に高い性能を叩き出すまでに至った過程の研究の一部を紹介していきます。
4.1 Double Descent
ディープニューラルネットワークを用いたモデルでも、多くの場合は多項式の次数のように、一個または数個のハイパーパラメータを変更することで形や大きさを容易に変更することができます。
様々なモデルとデータで研究が進むにつれ、サイズ以外は同種のモデル構造の学習に関して、モデルサイズと検証誤差が以下のような関係になる現象が確認されてきました。これがまさに、検証誤差が単なるU字カーブにはならないという反例の一つです。

このように、検証誤差が始めはU字カーブを描き、ある閾値を超えると再び下がり出す=すなわち誤差が2回下降する現象はDouble Descentと呼ばれています。
もし閾値よりも右の領域で左のU字領域よりも検証誤差が下がるのであれば、モデルサイズを大きくすればするほど漸近的に性能が改善するという一つの例となります。なお実際には、閾値付近の山が小さくほぼ単調に誤差が減少する場合や、右の領域で左のU字領域の下限よりも高い誤差値に収束してしまう場合など、多様なパターンが確認されています。
Double Descentに関する研究は、何回も学習プログラムを動かして実験的に検証誤差の変化を計測したものもあれば、特定のタスクやモデルに関してモデルサイズと検証誤差の関係式を数学的に証明したものもあります。また、検証誤差だけでなく、バイアス-バリアンス分解についても計測または立式・証明を行った研究も存在します。一例を以下に列挙しました。
- Reconciling modern machine learning practice
and the bias-variance trade-of - Two models of double descent for weak features
- A Farewell to the Bias-Variance Tradeoff?
An Overview of the Theory of Overparameterized Machine Learning - Memorizing without overfitting: Bias, variance, and interpolation in overparameterized models
なお余談ですが、モデルサイズ以外にも、Double Descentは学習エポック数、訓練データ数、訓練データのラベルノイズなど様々な要因で発生することが知られています。例えば、ハーバード大とOpenAIのメンバー(当時)の論文"Deep Double Descent: Where Bigger Models and More Data Hurt"に様々な事例がまとめられています。以下のページなどでこの論文の日本語解説も読むことができます。
- https://www.acceluniverse.com/blog/developers/2020/01/deep-double-descent-where-bigger-models-and-more-data-hurt.html
- https://zenn.dev/hnishi/articles/20201015-deep-double-descent
4.2 正則化
それでは何故(Double Descentに限らず)大きな深層学習モデルで過学習が発生しないかというと、正則化が働いて表現能力を自動調整しているからだという仮説があります。
例えば、書籍「ディープラーニングを支える技術2」では、以下のように述べられています。
(前略)
ニューラルネットワークはモデルの表現力を必要最小限に抑えるしくみが備わっていたためです。
あらかじめ大きめの表現力を持ったモデルを使っておき、問題に応じてこの表現力を適切なサイズまで自動的に小さくしていっているとみなせます。
また東大の鈴木先生のスライドでも、(深層学習モデルでは)
見かけの大きさ (パラメータ数) よりも実質的な大きさ (自由度) はかなり小さいはず.
という仮説について説明されています。
正則化とは、何らかの方法で過度に複雑なパラメータが得られないようにするための手法や仕組みのことです。これ自体は深層学習のブームより以前に考案されたもので、広く知られていました。例えば、L2正則化(リッジ回帰)という方法を用いて30次式モデルを学習すると、実は過学習は起こらずに以下のような結果になります。

L1正則化、L2正則化、early stoppingなどの正則化手法は深層学習以外の機械学習モデル・手法でも幅広く使用することができます。また近年の人気の機械学習ライブラリでは、一部の正則化手法がデフォルトで使用されるようになっています。言い換えると、エンドユーザが何もしなくても既に学習が正則化され、過学習がある程度抑制されているのです。
ニューラルネットワークに固有の正則化手法としては、ドロップアウトというものが有名です。これは、(ここまでニューラルネットワークの内部構造に一切触れてこなかったので説明が難しいですが)学習時にニューロンをランダムに不活性化することによって、アンサンブル学習と呼ばれる手法に似た効果を生じる方法です。
しかし実は、前の節で述べた論文の一つDeep Double Descent: Where Bigger Models and More Data Hurtでは、正則化手法を使っていないのにDouble Descentが生じたという旨が記載されています。また、次の節で詳しく紹介するLLMに関するOpenAIの論文でも、正則化は明示的に調整していない旨が記載されています。
どうやらニューラルネットワークは、その構造自体が何かしらの陰的正則化機能を含んでいるとの説があります。非常に高度な数学理論を駆使してようやく一部が解き明かされつつあるような状況のようですので、この記事で説明するのは難しいですが、先に挙げた書籍やスライドなどにもう少しだけ説明が載っていますので興味のある方はそちらをご覧ください。
4.3 Neural Scaling Laws
厳密で詳細な理屈はさておき、深層学習においては(実験した範囲では)モデルサイズを大きくするほど汎化性能が向上するという現象がいくつも確認されています。
GPTのOpenAIを始めとして、大規模モデルを研究してきた研究者・組織は、ニューラルネットワークのモデルサイズや訓練データ量とモデルの(汎化)性能の関係は冪乗則に支配されていると主張されています。
例えば論文"Scaling Laws for Neural Language Models"では、ある種の深層学習モデルのパラメータ数
という関係があったとのことです。この式を片対数グラフにプロットすると下記のようになります。

TransformerやLSTMなど、複数のモデルで同様の実験を行なっても、指数の大きさは違えど同様の冪乗則が確認されています。この論文は2020年1月発表で、GPT-2と同様の15億のパラメータ数までが調査されています。この論文では他にも、大きなモデルの方が、少ないデータサンプル数の学習で同程度の性能に到達する例などを紹介しています。
他にも、GPT-3の論文"Language Models are Few-Shot Learners"においても、モデルサイズとベンチマークタスクの損失の関係性が報告されています。最大1750億パラメータのGPT-3でも同様の冪乗則が確認されたようです。
5. 終わりに
2023年4月現在、AI研究は更なる加速を見せています。
OpenAIは今後は情報を非公開にしていく方針のようですが、同規模のLLMを自分達で開発しようと試みる組織が増えていますので、更にモデルサイズを増加させたら一体どうなっていくのか、近い将来にわかるのではないでしょうか。
一方で、現段階のLLMでもかなりのハードウェアリソースが要求されている上、モデルサイズの増加に伴って学習に必要なリソースも冪乗で増えてしまいますので、モデルサイズのスケーリングの意味での競争は今後減速していくのではないかという声も聞こえてきます。また、OpenAIの現CEOアルトマン氏は「巨大なモデルを用いる時代は終わりつつあると思います」と語ったらしいです(筆者は一次ソースは追えてないですが)。
またこれまでの歴史を振り返ると、モデルの大規模化による性能向上が進むたびに、なるべく少ない計算リソースやモデルパラメータで同等の性能を目指す試みが繰り返されています。少し前の話ですが、例えば、2018年に発表されたBERTという言語モデルに対して、2019年にはALBERTなどといった軽量モデルが開発されています。SNSやGitHubなどでは、ChatGPTやGPT4の発表を受けての軽量化の試みがすでに広がっています。
正則化の節で紹介した通り、大規模モデルでも実質的なパラメータの数は見かけのモデルサイズよりは小さいらしく、実際、学習されたパラメータの中身を見てみると、使われていなかったり冗長だったりするパラメータがあるらしいことは既に知られています。特に、学習前にランダムに初期されたパラメータのうち、一部分のみが最終的な性能に寄与するという宝くじ仮説という学説も研究が進んでいます。相対的に小さなモデルでも最大の大規模モデルと同程度の性能を達成できる可能性もまだまだあるのではないでしょうか。ただし、最終的に使われるのは一部だとしても、ランダムなパラメータの中の当たりクジが増えるため大きいモデルの方が汎化しやすくなると、前述の書籍などでは説明されています。当たりくじの存在が最終的な性能に対して支配的な要因だとすると、モデルのサイズを増やさずに当たりくじを得るためには何らかの工夫が必要になりそうです。
最終的にはどんな未来に辿り着くのか、今から待ち遠しいです。今後の研究動向や関連研究についてもブログ記事で紹介していきたいと思います。
Discussion