画像からStableDiffusionのプロンプトを探索 (CLIP Interrogator)
CLIP Interrogator
例えばStyleGAN等であれば画像から潜在変数を求めるGAN inversionという手法があります。
ならばText-to-ImageのPrompt inversionもきっとできるだろうと思い調べてみると既にCLIP Interrogator by @pharmapsychoticというものがあったので試してみました。
Colabで動かす
モデルの選択
StableDiffusionを使う場合、ViTL14を選択しろとセルに書かれているのでそうします。
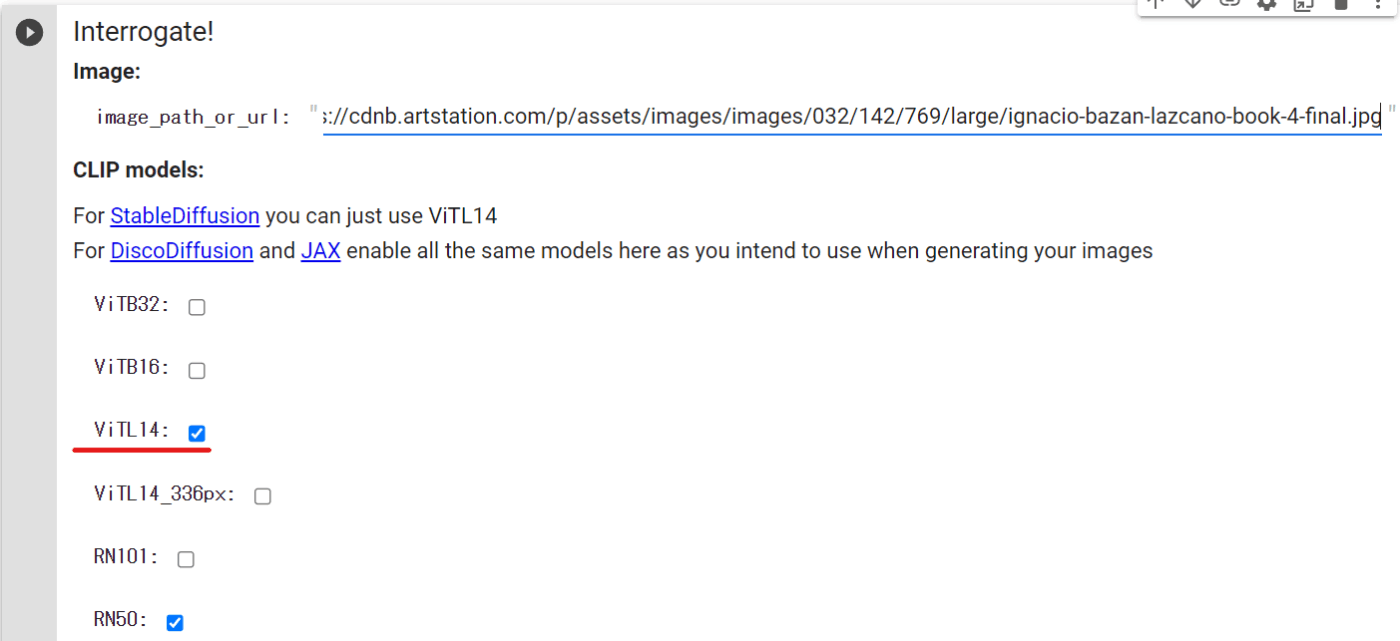
HuggingFaceのモデルリポジトリを見に行くと、確かにtext encoderの設定ファイルにはopenai/clip-vit-large-patch14 とあるのでこれっぽいです。
推論
サンプル画像を用いてテキストプロンプトを探索すると "a man standing on top of a bridge over a city, cyberpunk art by James Gilleard, cgsociety, retrofuturism, cityscape, synthwave, matte painting" という結果が生成されました。

画像生成
HuggingFace spacesで実際に生成させてみます。

完全に同一のものにはなりませんでしたが、雰囲気や構図はそこそこ似ているものができています。Unsafe contentを生成しようとしていた点も気になりますね…
他の画像
Stable Diffusionでkawaiiを出力しようと奮闘したまとめの記事で使われている画像で試してみます。
image path: https://storage.googleapis.com/zenn-user-upload/2d4af558ef43-20220824.jpg

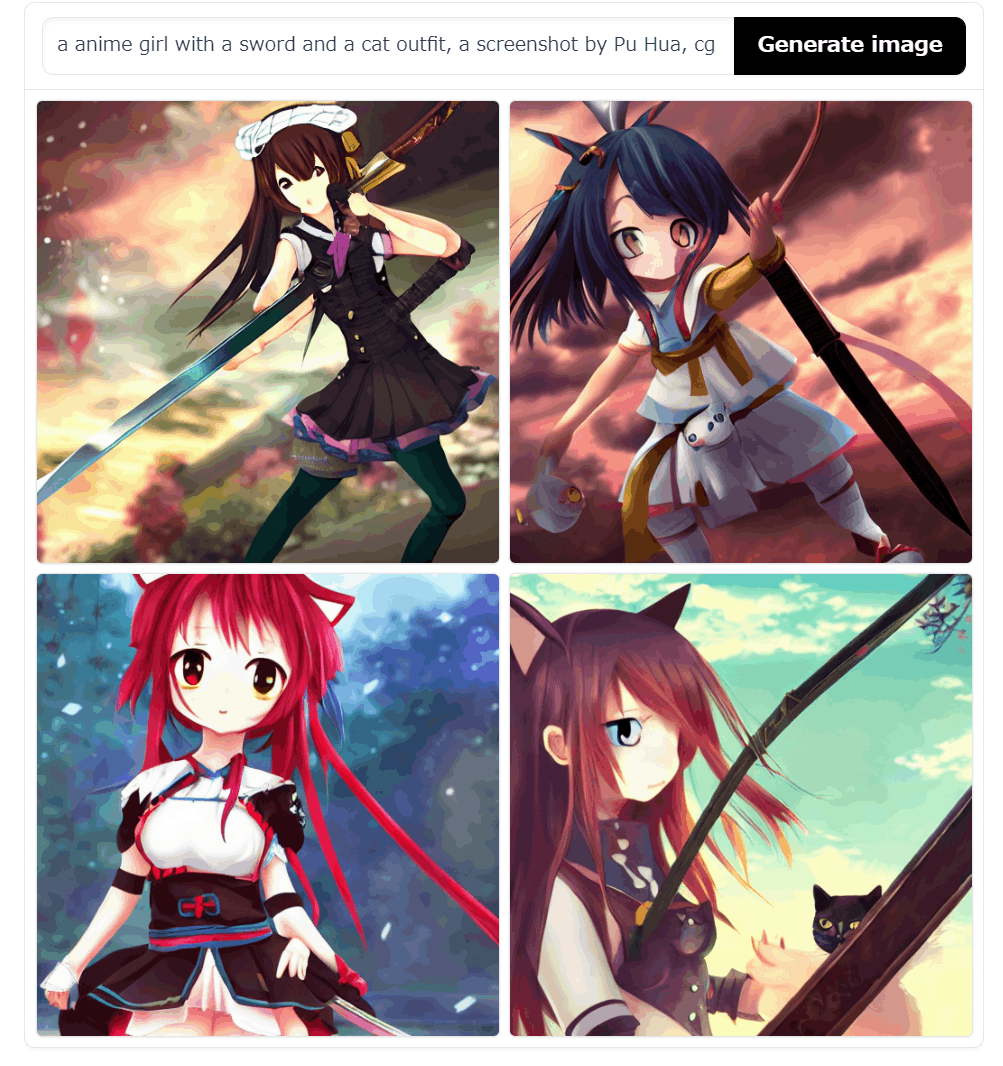
CLIP Interrogator: "a anime girl with a sword and a cat outfit, a character portrait by Pu Hua, cg society contest winner, rayonism, pixiv, hd mod, booru"
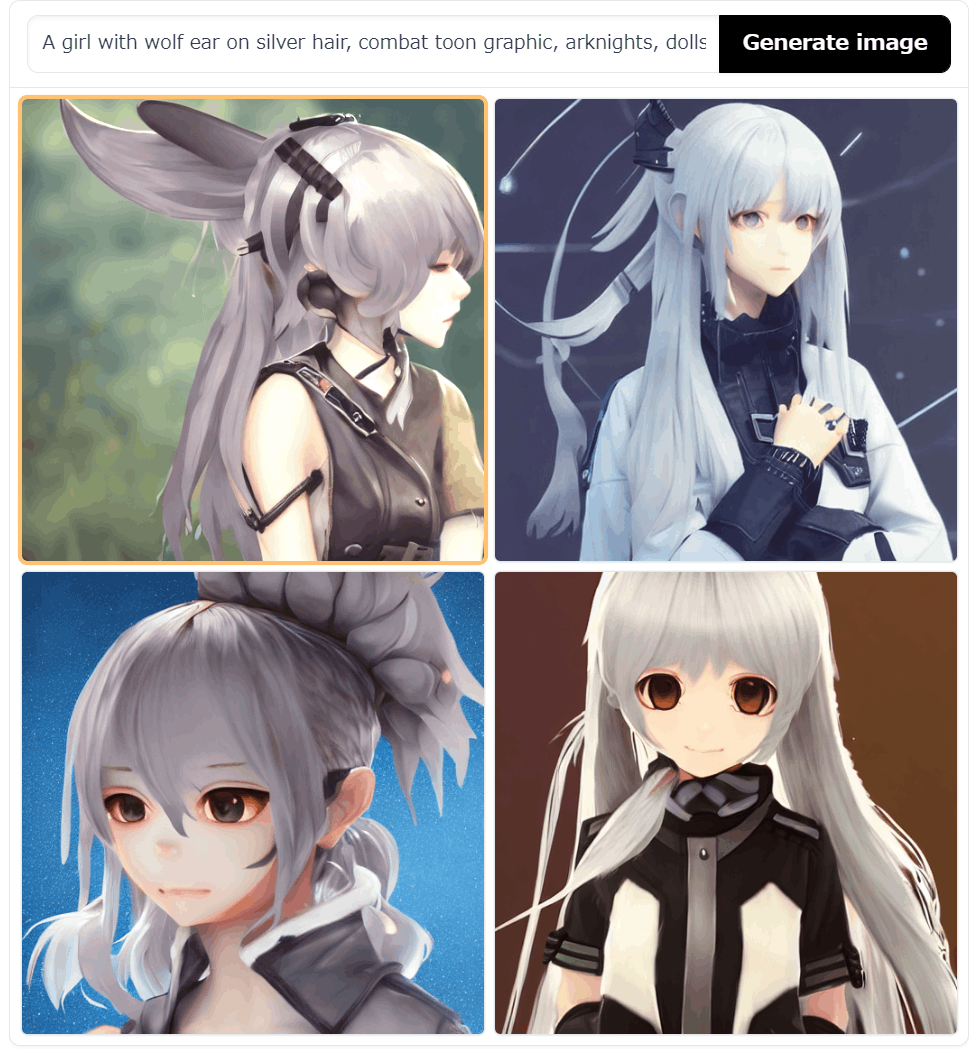
実際のプロンプト: "A girl with wolf ear on silver hair, combat toon graphic, arknights, dolls frontline, pixiv"
出力画像
CLIP Interrogator:
Grandtruth
感想
完全に任せるのは厳しいかもしれませんが、プロンプトエンジニアリングの補助として使えそうです。
Discussion