Closed6
Cloud SQL x Datastream x BigQuery の分析基盤を構築してみる
概要
- Cloud SQL の設計は、アプリケーションの要求に応じて迅速に読み書きを行う OLTP(Online Transaction Processing)に最適化されている
- Cloud SQL の設計は、分析用途には向いていない
- なので Cloud SQL と Looker Studio を直接接続すると Cloud SQL に高い負荷がかかり、アプリケーションのパフォーマンスに影響してしまう
- ベストプラクティスとしては、 OLAP(Online Analytical Processing)に最適化された BigQuery に、負荷がかからない形で Cloud SQL のデータを流し込み、BigQuery と Looker Studio を接続すること
- Cloud SQL に負荷がかからない形で Cloud SQL のデータを流し込むには、Datastream というサービスを使う
- Datastream はデータベースの変更履歴を読み取ってデータを複製する CDC(Change Data Capture)という仕組みを採用している
- CDC はデータベースのログを読み取るため、アプリケーションのパフォーマンスへの影響を限りなく小さくできる
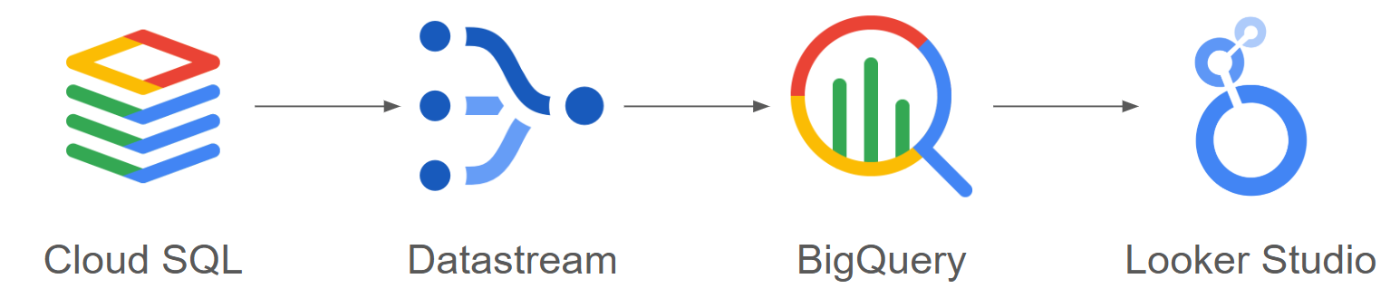
構成図
- イメージとしては、Cloud SQL と BigQuery の両方に同じデータが存在するようになるイメージ
ストリームの作成について
- Datastream を使ってデータを流し込むためには、まず ストリーム を作成する必要がある
- ストリームを作成するには、ソースの定義(Cloud SQL からデータを取得するための定義)と
宛先の定義(BigQuery にデータを流し込むための定義)を設定する必要がある - ソースの定義と宛先の定義はどちらとも 接続プロファイル を作成することで定義できる
接続プロファイルの作成について
- 接続プロファイルを作成するには、接続方法の定義 を設定する必要がある
- 接続方法は プライベート接続 を選択
他の選択肢として、「IP許可リスト」「フォワードSSHトンネル」というものがあるが、
今回の要件の場合、Google Cloud で完結できるので、Google Cloud の安全な内部ネットワークで通信できる最も安全な接続方法である「プライベート接続」が選択可能 - プライベート接続をするには、プライベート接続構成 を設定する必要がある
- プライベート接続構成の設定の プライベート接続方法 は、「PSC(Private Service Connect)インターフェース」と「VPCピアリング」がある
- PSC インターフェースの方がより新しい接続方法で安全で管理が楽
- Datastream は Google 所有のプロジェクトの VM にホストされている
下記サイトではそのプロジェクトを プロデューサープロジェクト と呼んでいる
https://cloud.google.com/datastream/docs/psc-interfaces - Datastream = Private Service という認識で良いのかな?
- PSC インターフェースで接続する場合、下記リンクから Datastream プロジェクトが Cloud SQL のプロジェクトにアクセスできるように ネットワークアタッチメント を作成する
https://console.cloud.google.com/net-services/psc/list/networkAttachments
ネットワークアタッチメントの設定の「承認済みプロジェクト」と「不承認となったプロジェクト」は空で作成する(あとでGoogle 所有の Datastream が存在するプロジェクトを設定する) - そして、プライベート接続構成の作成画面から作成したネットワークアタッチメントを適用する
- その後、「許可リストを更新」ボタンを押すことで、Google 所有の Datastream が存在するプロジェクト がネットワークアタッチメントの承認済みプロジェクトに設定される
- ひとまずここまでの設定で接続プロファイルの接続テストをしてみたが、タイムアウトエラーが発生
- 接続プロファイルの Cloud SQL の IP をパブリック IP アドレスにしていたところを内部 IP アドレスに変更したら、接続テストに成功した
ソースの構成について
- 接続テストが完了したソースのどのテーブルを使用するか選択する
- CDC メソッドを選択
「GTID(Global Transaction Identifier)べースのレプリケーション」か「バイナリログベースのレプリケーション」 - GTID ベースのレプリケーションの方がフェイルオーバーをシームレスにサポートしてくれるので、
特別な理由がない限りは GTID ベースのレプリケーションがおすすめっぽい
MySQL のバージョンが 5.6 以前の場合には GTID ベースのレプリケーションに対応していないっぽいので、そういう場合にはバイナリベースのレプリケーションを使用する
https://cloud.google.com/datastream/docs/sources-mysql
最終確認
- 最後のストリームの検証時に警告が出た
- 警告の指示通りに Cloud SQL インスタンスのフラグを修正
このスクラップは2日前にクローズされました