RAGで独自知識を回答~GPTs Actionsで簡単チャットbot開発
はじめに
この記事では、LLM(Large Language Models)に独自の知識を組み込むためのRAG(Retrieval-Augmented Generation)手法の概要と、その実践例を紹介します。
LLMに独自の知識を回答させる方法
ChatGPTを含むLLMは、学習した内容をもとに回答を生成しますが、学習していない内容については正しい回答ができません。
LLMが学習していない独自の知識について回答させる方法は、LLMに追加学習をさせるファインチューニング、外部情報を参照するRAGなどがあります。
ファインチューニングは、ファインチューニングに対応していないLLMもあり、また、機械学習の知識や計算リソースが必要です。
RAGは、LLMに手を加えずに外部システムを参照するだけなので、簡単に独自の知識を回答させることができます。
RAGの概要
RAGでは、データベースなどの外部システムから検索する工程と、LLMを使って回答を生成する工程を組み合わせています。これにより、LLMが学習していない内容についても検索結果をもとに回答することができます。

検索結果が端的で分かりやすい場合は、LLMを組み合わせる必要がないこともあります。しかし、膨大な検索結果に散在したデータを組み合わせて要約したり、質問者が求めている形式の回答文を生成する必要がある場合は、LLMを組み合わせるメリットがあります。例えば、子供が読みやすい簡潔な文章で出力したいケースや、日本語と英語を併記して出力したいケースなどが該当します。
今回のRAG実践テーマ
今回は、国税庁の手引きをデータソースとします。
- 多くの資料は毎年更新されるので、LLMが未学習である可能性が高い
- 資料数・文字数ともに多く、端的にまとまっていない
- 普通の人には読みづらい役所文章である
という特徴があり、RAGを使うメリットがあります。
(LLMが事実と異なる情報を生成してしまう現象をハルシネーションと言います。RAGを使うことでハルシネーションの軽減はできますが、完全に防げる訳ではないため、回答内容は慎重に確認する必要があります。)
アプリケーション構成
外部システムからの検索プロセス
RAGチャットアプリケーションでは、ユーザーからの質問に対して関連する情報を外部システムから検索する必要があります。キーワード検索も一つの方法ですが、表記ゆれや同義語による検索漏れを防ぐため、ベクトル検索の利用が一般的です。
ベクトル検索を用いたRAGの流れ

① 質問の受付:質問者がチャットAIアプリケーションに質問を入力。
② 質問文の処理:アプリケーションが質問文をEmbedding APIに送信。
③ ベクトル化:Embedding APIが質問文をベクトル化して返却。
④ ベクトルデータベースでの検索:質問文のベクトルをベクトルデータベースで検索。
⑤ 関連テキストの取得:検索結果として関連テキストを得る。
⑥ LLMへの入力:検索結果と質問文をプロンプトテンプレートに流し込み、LLMに入力。
⑦ 回答の生成:LLMが回答のテキストを生成。
⑧ 回答の送信:必要に応じた後処理を行い、質問者に回答を送信。
簡単に実現するための構成
チャットAIアプリケーションはLangChainなどを活用すると効率良く開発することができますが、今回はより簡単に実現するためにGPTsを使うことにします。GPTsはChatGPTをカスタマイズしたり公開したりできるサービスです。
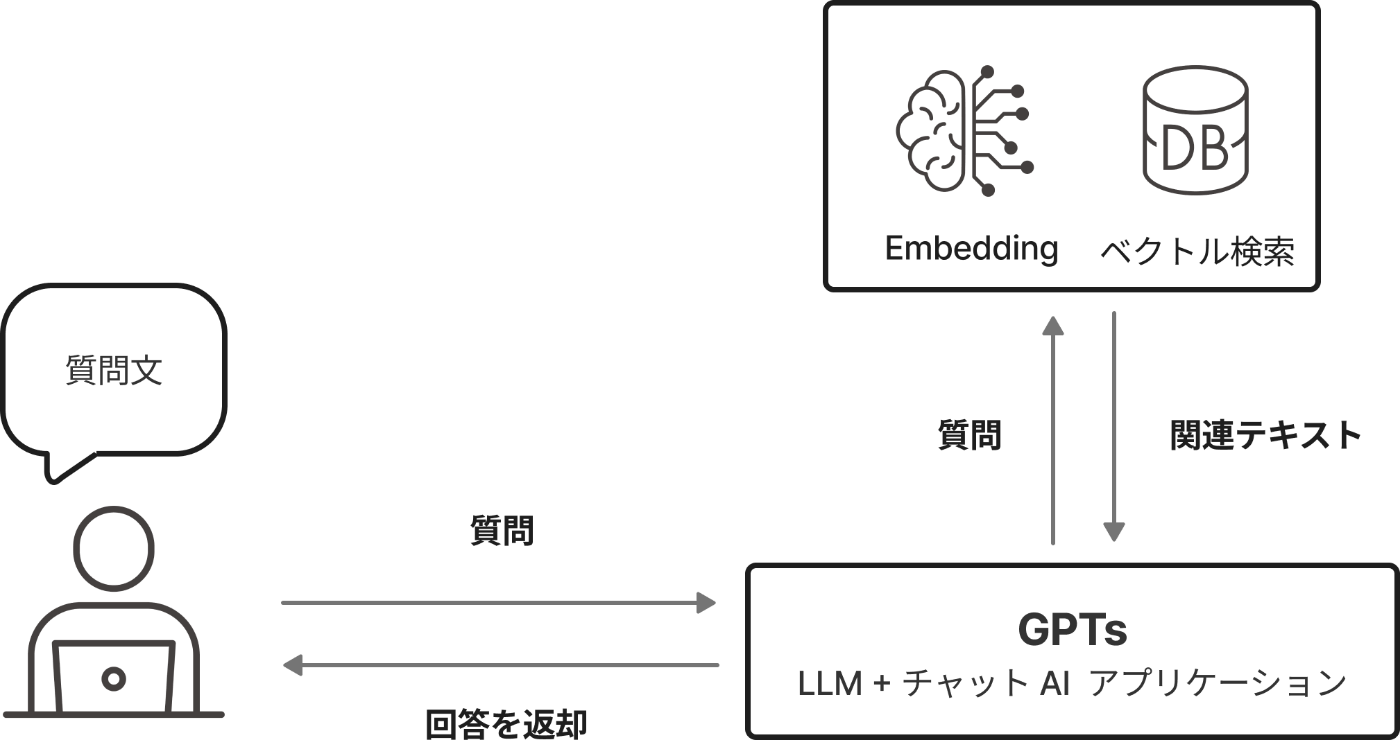
GPTsを利用すれば、Embedding + ベクトル検索ができるサーバーを作って連携させれば完成です。ログイン等を含むチャットアプリケーションの開発や、LLMを連携する処理の実装などが不要になります。
ベクトル検索APIの開発:Flask + Chroma
今回は開発の手軽さを重視し、FlaskとChromaでAPIサーバーの構築をします。FlaskはシンプルなPythonのWebアプリケーションフレームワークで、Chromaは軽量なベクトルデータベースです。
サーバーは、受け取った質問文をEmbeddingAPIにリクエストしてベクトル化し、得られたベクトルを事前準備したChromaデータベースで検索して文章を取得します。

まず、Chromaに国税庁の手引きのpdfをベクトル化して登録します。LangChainがとても便利です。
pdfをベクトル化してChromaに保存して検索する方法は、色々な本・ブログで紹介されているので今回は省略したいと思います。こちらの本がかなり参考になります。
サーバーの開発とデータ挿入が完了したら、好きな環境にデプロイします。
筆者は手軽に安く運用したかったため、Google Cloud Runを利用しました。FlaskサーバーをCloud Runにデプロイする方法は、以下の記事が参考になると思います。
また、GPTsではActionsが参照したURLが出力されるため、エンドポイントには認証が必要です。例えばAPI Gatewayを使うと、CloudRun上のサーバーに認証をつけることが可能です。
GPTsのActionsの設定
作成したベクトル検索APIにリクエストができるようにGPTsのActionsを設定します。
このようにスキーマを設定しておきます。
openapi: "3.0.0"
info:
version: 1.0.0
title: Generic Vector Search API
license:
name: MIT
servers:
- url: https://example.com/api # ベクトル検索APIのURL
paths:
/search:
get:
summary: "指定されたクエリに似た内容のドキュメントを検索します"
operationId: searchByQuery
parameters:
- name: query
in: query
description: "検索するテキストクエリ"
required: true
schema:
type: string
APIに認証をつけている場合は、Authenticationの設定も必要です。
RAGの有無でチャットの回答を比較
RAGを使って独自知識を回答できるようになっているのか、素のChatGPT4と比較します。
RAGなし

RAGあり

どちらが分かりやすいと感じるかは個人差があると思いますが、令和6年の情報が取れるにようになりました。
まとめ
RAGを使うことで以下が実現できました。
- 検索システムを使って未学習データを検索して、それをもとに回答する
- LLMを使って検索結果を要約し、親しみやすい形式で出力
いつまで公開しておくかは未定ですが、ぜひ今回紹介したGPTsも使ってみて下さい。
(某伝説アーティストから影響を受けた命名で「TAX JAPAN」になっています。)
Discussion