🐥
【LLM】Coursera Generative AI with Large Language Models - Week 1
Introduction to LLMs and the generative AI project lifecycle
Course Introduction
- Andrew Ng 先生
- AWS のエキスパート 3 人が解説
- prompt engineering から fine tuning まで学べる
- 実習は AWS の無料枠で完結する
Introduction Week 1
- transformer がすごい、という会話
Generative AI & Models
学術界での定義
- prompt のことを context window と呼ぶ
- model への input, output のことを context, completion と呼ぶ
- この授業では fine tuning の方法も学べる

LLM use cases and tasks
- LLM は会話のみならず、伝統的な言語タスクもできる
- 翻訳
- 文章生成
- コーディング
- named entity recognition
- week3 で外部 API との接続を学ぶ
- パラメータが増えると、モデルの主観的な理解力(基礎力みたいなもの)も向上する
- subjective understainding of languages processes, reasons, and solves the tasks
- week2 で smaller model の fine tuning の方法を学ぶ
- ここ数年の LLM の進展はアーキテクチャがキーだった
Text generation before transformers
- Text generation before transformers | Coursera
- transformer の前は RNN が使われていた
- RNN の欠点はスケーラビリティ。多くの計算リソースとメモリが必要だった。
- transformer により、そのスケーラビリティの問題が解決され、大きなデータセットで大きなモデルが作れるようになった
- マルチコア GPU
- 入力データの並列化
Transformers architecture
- Transformers architecture | Coursera
- Self Attention によりモデルの言語理解が向上した

- Self Attention: 入力された文における単語の関係の強さを全て学習する機構
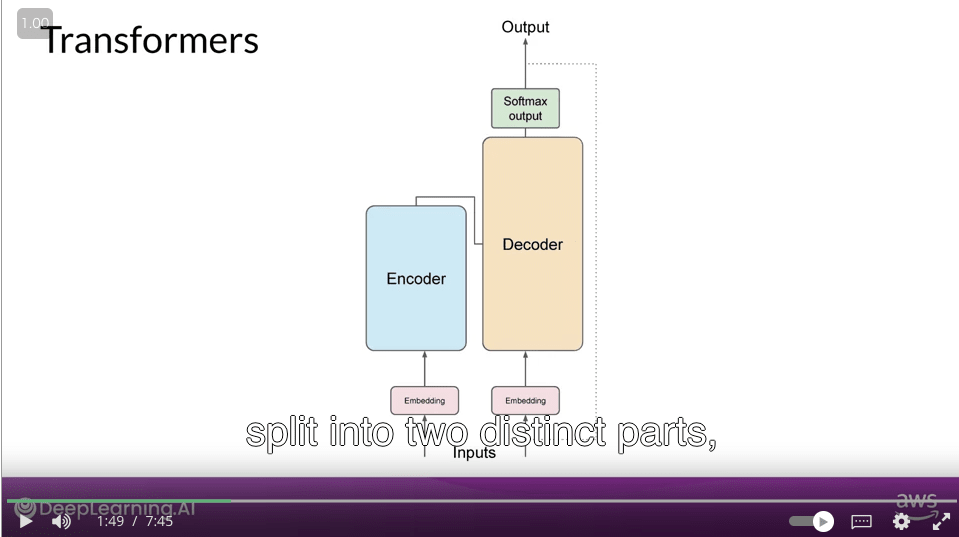
- transformer のアーキテクチャは 2 つのパーツに分けられる。Encoder と Decoder
- inputs は数字なので、文字を tokenize する必要がある
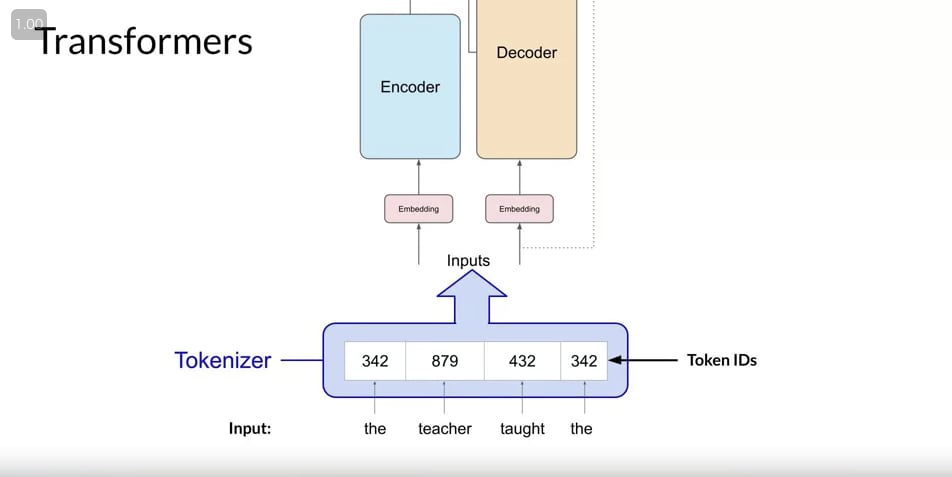
- tokenizer の選択はモデル設計の 1 種
- tokenize された input は embedding になる
- original paper では 512 次元
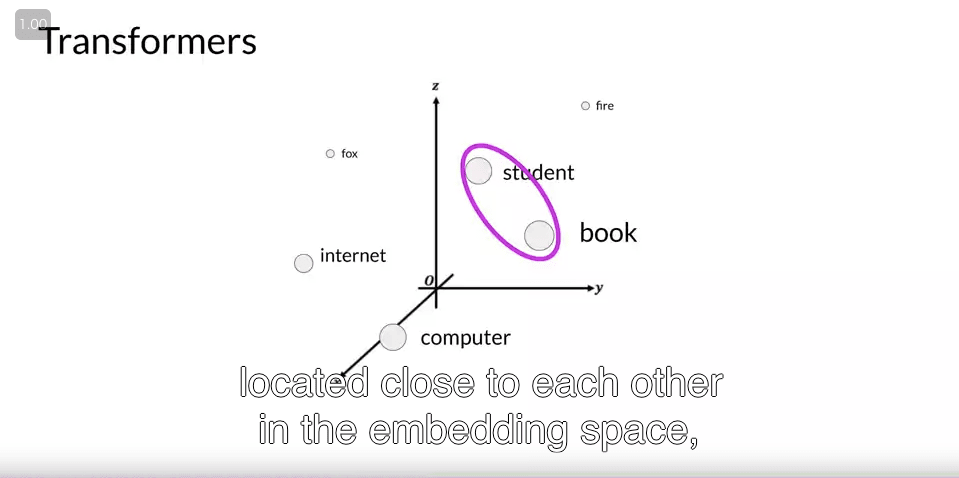
- embedding は単語単体の意味を表すようなベクトル
- positional encoding
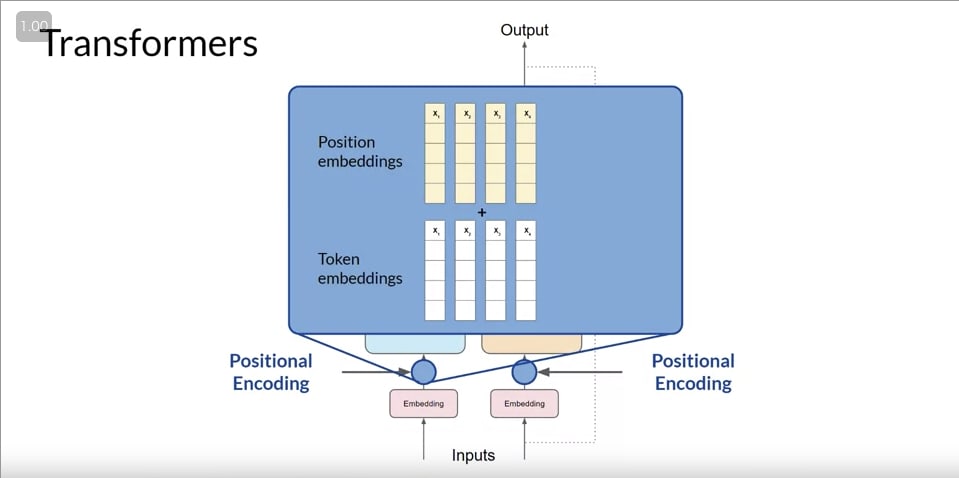
- 単語の順番をモデルが理解できるようにするための仕組み
- multi head attention
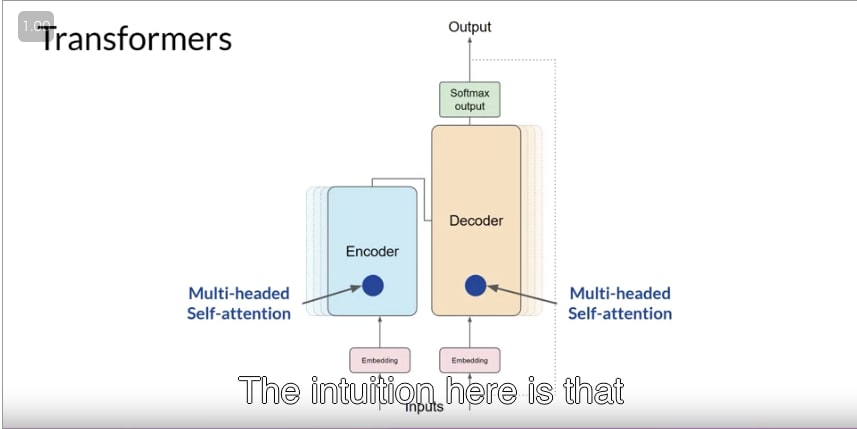
- 1 つの self attention では、単語の関係性を 1 つしか学習できない
- multi head attention では、複数の attention を学習することで、複数の単語の関係性を学習できる
- 例
- 文の人物の関係
- 単語の韻
- activity(?)
- softmax
- tokenizer 内の単語の数だけの次元を持つベクトル
- その中で最も大きい値を持つ次元が、モデルが出力する予測単語
Generating text with transformers
- Generating text with transformers | Coursera
- Encoder の output と tokenized された input を 1word ずつ入力として受け付け、Decoder は次の単語を予測する
- e.g. French への翻訳
- tokenized: English sentence
- encoder's output: english sentence 全体の意味や構造
- e.g. French への翻訳
- Encoder 単体の学習も昔はされていた. encoder の output に分類層をつける。
- sentiment 分析.
- BERT
- Encoder-Decoder model の方が翻訳はうまくいく
- input と output の出力次元が異なってもいいので
- テキスト生成にも向いてる
- BART
- 最近は Decoder-only model が主流
- GPT
- LLaMa
- BLOOM
- Jurassic
Prompting and prompt engineering
- Prompting and prompt engineering | Coursera
- in-context learning(ICL): context window (prompt) に問いだけでなく、同形式の問いと答えのペアを入れることで推論性能を向上させるテクニック
- zero shot inference
- 問い + 補足情報 + 答えの形式
- 追記:
- 答えの形式は、例えば、"Summary: "とか。
- 仮に問いに"Summarize the following sentences"と書いてあったとしても、"Summary: "を付加することで改善することがある
- one shot inference
- (問い + 補足情報 + 答え) * 1 + (問い + 補足情報 + 答えの形式)
- few shot inference
- (問い + 補足情報 + 答え) * N + (問い + 補足情報 + 答えの形式) (N>=2)
- smaller model の方が one, few shot inference で改善しやすい

Generative configuration
- Generative configuration | Coursera
- Inference parameters: 推論時に関係があるパラメータ
-
max new tokens : 生成する token 数
- stop token が出たら max までいかないこともある
- greedy decoding: 予測単語の中で最も確率が高いものを選ぶ
- 最もよく使われる設定だが、単語の繰り返しを起こしやすくなる
- 短文生成には向いている
- random sampling: softmax の確率に従ってランダムに単語を選ぶ
- top k sampling: softmax の確率が高い上位 k 個の単語から sampling
- top p sampling: softmax の確率が高い上位 p%の単語から sampling
-
temperature: softmax の確率分布を変化させる
- 高いと峰が低く、低いと峰が高くなる
- ランダム性(creativeness)を高くしたければ高く設定すればよい
- ※太字が一般的に設定できるパラメタ
- 疑問: k と p を併用しているときって and 条件?
-
max new tokens : 生成する token 数
- temperature の例

Generative AI project lifecycle
- Generative AI project lifecycle | Coursera
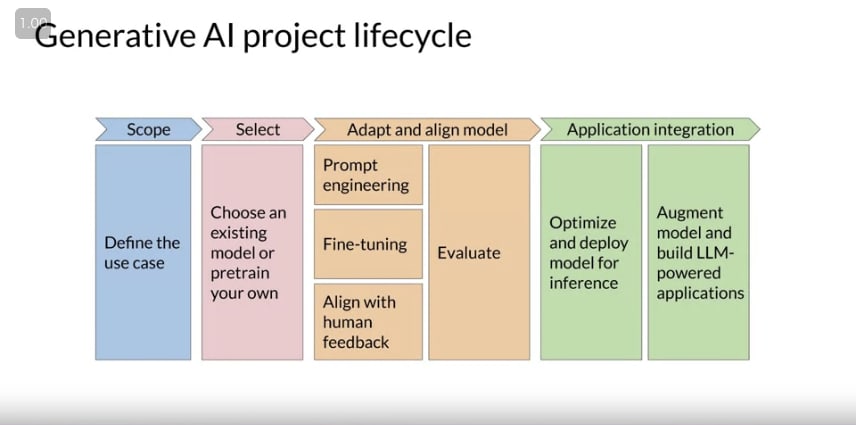
- Lifecycle の全体像
- Scope
- model に対してどういう要求があるのかを定義する
- どのタスク?
- であればどのサイズのモデル?
- compute cost の低減にも寄与する
- model に対してどういう要求があるのかを定義する
- Select
- from scratch で作るか、ありものの model を使うか?を考える
- 判断基準は week1 の後ほどで解説
- Adapt and align model
- training のような step
- Prompt engineering(one or few shot inference)
- 初手としてとりあえず実施
- fine-tuning
- prompt engineering でうまくいかなかったら実施
- 方法は week2 で学ぶ
- align with human feedback
- 人間の好み(preference)に従っているかを保証する step
- reinforcement learning with human feedback (RLHF) を実施する
- RLHF は week3 で学ぶ
- evaluation
- 推論や振る舞いの良さの評価
- 指標については week2 で学ぶ
- この step は iterative
- Fine-tuning の実施後、prompt-engineering を実施して、また評価、といった具合
- Application integration
- model を推論に最適化
- additional infra の構築
- tendency
- complex reasoning
- complex mathmatics
- に対応する
Introduction to AWS labs
- Introduction to AWS labs | Coursera
- AWS で excercise するための機能紹介
Lab 1 walkthrough
- Lab 1 walkthrough | Coursera
- Jupyter で要約タスクの prompt engineering
- 扱うモデルは FLAN-T5
- zero-shot inference の実行
- zero-shot inference で答えの形式を変えて実行
- one-shot inference の実行
- few-shot inference の実行
- 発表者の経験的には、5 or 6 shot 以上はあまり改善しない
- この notebook の例でも、one-shot で十分(2-shot でもあまり改善していない)
- inference parameter を変えた推論の実行
感想
- 誰から・何で学んだは重要かも
- スタンダードな教材・有名な先生で学ぶのはその分野の共通言語を学ぶことになっている気がする
LLM pre-training and scaling laws
- 次ここから
Discussion