📈
PytorchでMobileNetV2を使うときに詰まったこと
久々にPytorchをダウンロードして以前自分が作ったマスクつけてる人分類モデルを動かしてみました。
ところが、以下のモデルを読み込むコードでエラーになりました。
Model = torch.hub.load('pytorch/vision:v0.10.0', 'mobilenet_v2', pretrained=True)
エラーの内容としては、HTTP Error 403: rate limit exceeded when loading model で以下のissueでも同様の内容がありました。
バージョンが新しくなるとダウンロード先が変更されるのでしょうかね。でもこのためだけにバージョンを動いてたときのバージョンまで落とすのは辛いので、issueのコメントにならって以下の対処をしてみました。
from torchvision.models import mobilenetv2
Model = mobilenetv2.MobileNetV2()
するとMobileNetV2は使えたので良かったのですが、明らかに精度が落ちました。
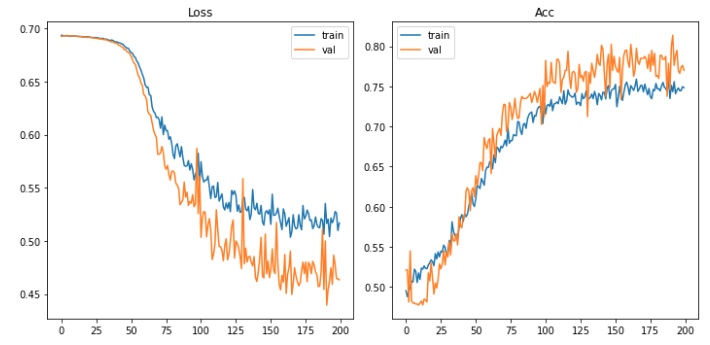
ミニバッチを以前より増やしてエポック数を増やしていてこれですよ。
で、ソースコードを眺めていたらmobilenet_v2()関数があるのに気づきました。
この関数の引数でpretrained=Trueを指定すると学習済みモデルで転移学習ができるようになるようです。
つまり、mobilenetv2.MobileNetV2()だと訓練されていない状態で位置から学習するのと変わらないということです。
そんなのソースコード見ないと分からんよ…
というわけで以下のコードに修正して再度学習してみます。
from torchvision.models import mobilenetv2
Model = mobilenetv2.mobilenet_v2(pretrained=True)
先程と同じ条件で学習させたら、見事にキレイなグラフを描いてます(学習精度が極端に良すぎなのはご愛嬌)。

これを学習済みモデルを使わずにやろうとしたらそりゃ簡単に精度上がるわけ無いですよね。
逆に一から学習をさせようとするとものすごい数のデータセットとそれを処理するのに見合うスペックのグラボが必要ということですね。
Discussion
参考になりました。
学習済みファイルをローカルに置いておくアプローチを書き残していきます。
【Python】オフラインでfine-tuningのpretrainedを使用する方法【PyTorch】 - tmori’s blog
MobileNet_v2学習済みモデルダウンロード場所
Torchvision 0.8.1 documentation
PyTorch Hub, torchvision.modelsで学習済みモデルをダウンロード・使用 | note.nkmk.me
コメントありがとうございます。今回紹介した方法でも初回でモデルを読み込むときにモデルのダウンロードが走って所定の位置に保存されるので、2回目以降はローカルに保存されたモデルを読み込むようになりますね。
ちょうどこちらの記事にあるような挙動と同じ感じですね